Clear Sky Science · it
Un quadro ibrido CNN e apprendimento per rinforzo per l’identificazione del parlante usando Mel-Spectrogram e trasformata wavelet continua
Perché la tua voce può essere una chiave digitale
Immagina di sbloccare il conto in banca, la porta di casa o il telefono usando solo la tua voce. Perché ciò sia sicuro, i computer devono distinguere con affidabilità una persona dall’altra, anche in presenza di rumore di fondo, emozioni o un microfono scadente. Questo articolo esplora un nuovo modo di insegnare alle macchine a riconoscere chi parla, non solo cosa viene detto, combinando tecniche moderne di deep learning con una forma di apprendimento per tentativi e errori mutuata dalla robotica.
Da onde sonore a impronte vocali
La voce di ciascuno porta indizi sottili determinati dalle dimensioni e dalla forma del tratto vocale, dal modo in cui vibrano le corde vocali e dallo stile di parola. I ricercatori hanno iniziato chiedendosi: quali proprietà misurabili del parlato registrato differiscono realmente da persona a persona? Usando 2.703 clip audio di 40 parlanti inglesi del dataset LibriSpeech, hanno analizzato 22 semplici caratteristiche acustiche, come variazioni di intensità, energia in diverse bande di frequenza, ritmo e una misura chiamata entropia che cattura quanto il suono sia complesso o imprevedibile. I test statistici hanno mostrato che 21 di queste 22 caratteristiche contengono informazioni fortemente specifiche del parlante, con l’entropia e l’energia ad alta frequenza particolarmente distintive. In altre parole, l’“impronta vocale” di una persona è distribuita su molti aspetti del suono, non solo sul tono o sul volume.
Due modi per trasformare il suono in immagini
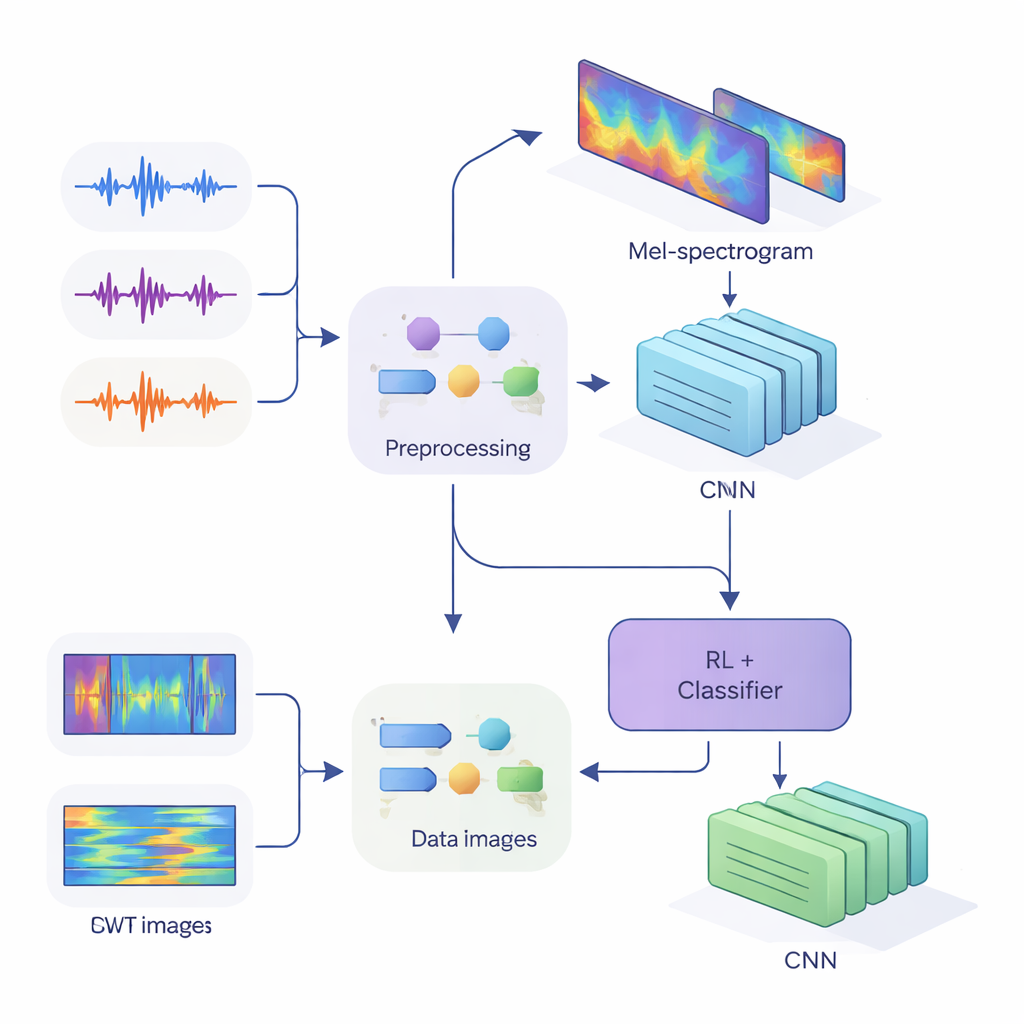
Per introdurre questi indizi nelle moderne reti neurali, il team ha convertito l’audio monodimensionale in immagini bidimensionali che catturano come l’energia varia nel tempo e in frequenza. Nel primo metodo hanno usato i Mel-spectrogrammi, che imitano il modo in cui l’orecchio umano raggruppa le frequenze e sono uno standard nella tecnologia del parlato. Nel secondo metodo hanno impiegato la trasformata wavelet continua, un modo più flessibile di ingrandire sia su suoni brevi e acuti sia su vocali più lunghe. Dopo un’attenta pulizia dell’audio — rimozione dei silenzi, standardizzazione del volume e aggiunta di piccole distorsioni come rumore e spostamenti di pitch per rendere il sistema più robusto — hanno prodotto “immagini” Mel di dimensione 80 per 313 e “immagini” wavelet di 128 per 128, pronte per essere processate da reti neurali convolutionali (CNN).
Insegnare alle reti ad ascoltare e a dubitare
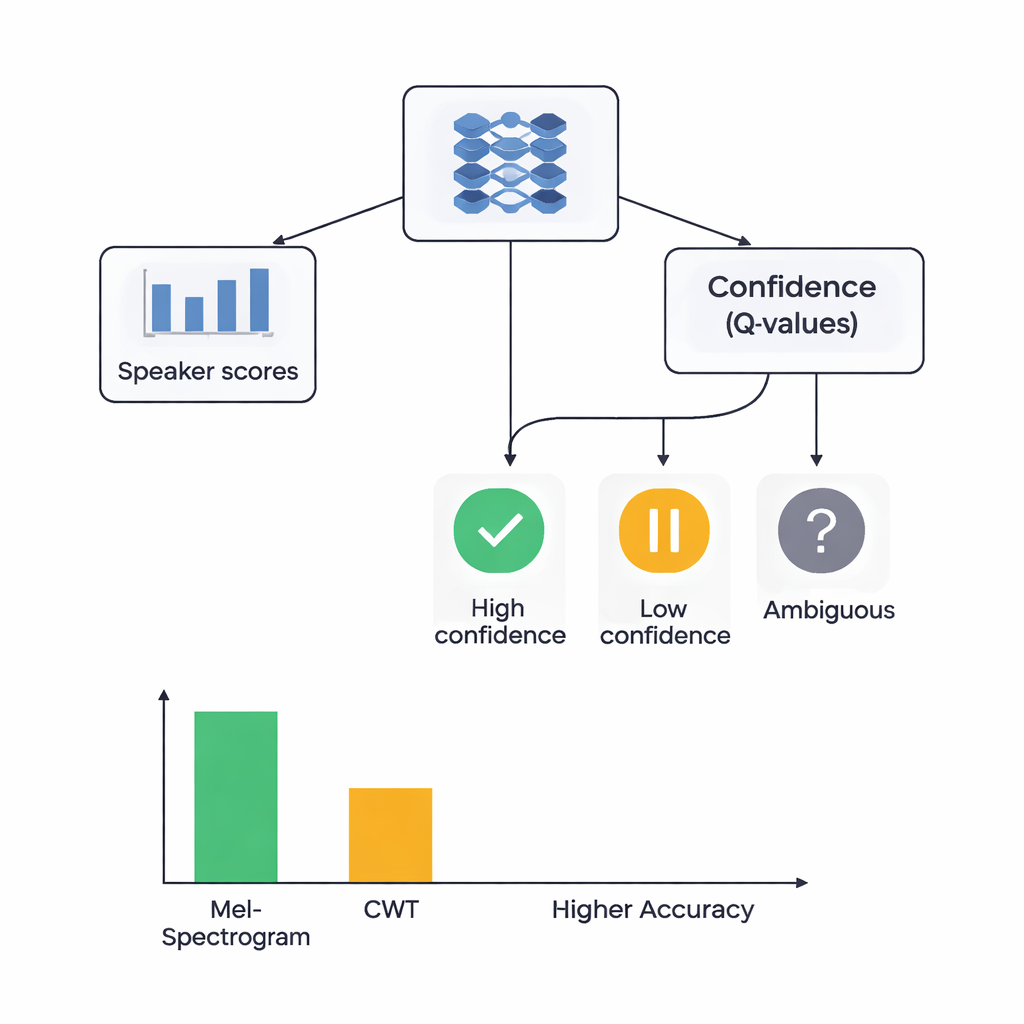
Al centro dello studio c’è un’architettura ibrida che unisce due stili di apprendimento. Prima, le CNN analizzano le immagini Mel o wavelet per estrarre pattern che tendono ad appartenere a specifici parlanti, similmente a come le reti per il riconoscimento delle immagini imparano a individuare occhi o contorni. Per il sistema basato su Mel, gli autori aggiungono un modulo di self-attention che permette alla rete di concentrarsi sui segmenti temporali più informativi. Sopra questi estrattori di caratteristiche, collocano un componente di apprendimento per rinforzo (RL) che apprende quanto il sistema debba essere sicuro di ciascuna decisione. Invece di prendere sempre una decisione netta, la parte RL assegna valori ad azioni come “accetta questa come ipotesi ad alta confidenza”, “considera questa a bassa confidenza” o “segna come ambigua”. Dopo molti cicli di addestramento, viene premiata quando decisioni sicure risultano corrette, spingendo la rete verso giudizi meglio calibrati.
Quanto bene funziona il sistema ibrido?
I ricercatori hanno confrontato quattro modelli: Mel con RL, Mel senza RL, wavelet con RL e wavelet senza RL. Tutti sono stati testati usando una accurata validazione incrociata a cinque fold, il che significa che ogni clip audio è servita sia per l’addestramento sia per il test in diverse tornate. Il sistema Mel più RL ha dato le migliori prestazioni, identificando correttamente il parlante circa l’88% delle volte e mostrando una separazione quasi perfetta tra parlanti secondo una misura standard di potere discriminante. Il sistema wavelet più RL ha raggiunto circa il 78% di accuratezza. Crucialmente, l’aggiunta del componente RL ha migliorato le prestazioni per entrambi i tipi di caratteristiche di circa 3 punti percentuali e ha reso i risultati più coerenti tra le diverse suddivisioni dei dati. Più classi di parlanti hanno ottenuto riconoscimenti di alta qualità quando è stato incluso l’RL, suggerendo che le decisioni consapevoli della confidenza hanno aiutato soprattutto con voci difficili e facilmente confondibili.
Cosa significa per la sicurezza vocale di tutti i giorni
Per i non specialisti, la conclusione chiave è che controlli d’identità basati sulla voce affidabili richiedono sia rappresentazioni ricche del suono sia una sana dose di dubbio da parte della macchina. Questo lavoro mostra che i Mel-spectrogrammi ispirati all’orecchio, combinati con attention e un apprendente per rinforzo che può dire “non ne sono sicuro”, superano immagini wavelet più esotiche nel compito di distinguere i parlanti. Pur avendo lo studio usato un dataset relativamente piccolo e pulito e non essendo ancora tarato per condizioni rumorose del mondo reale, dimostra che aggiungere uno strato consapevole della fiducia sopra reti neurali profonde può rendere l’autenticazione vocale sia più accurata sia più affidabile — un passo importante se vogliamo che le nostre voci diventino chiavi digitali sicure.
Citazione: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
Parole chiave: identificazione del parlante, biometria vocale, deep learning, apprendimento per rinforzo, Mel-spectrogrammi