Clear Sky Science · it
Un quadro generale per la riduzione adattiva non parametrica della dimensionalità
Perché ridurre i big data è importante
La vita moderna si basa sui dati: immagini mediche, cronologie di acquisti online, fotografie, feed di notizie e altro ancora. Ogni record può contenere centinaia o migliaia di misure, rendendo difficile memorizzarli, analizzarli o anche solo visualizzarli. Gli scienziati usano la “riduzione della dimensionalità” per comprimere questa complessità in rappresentazioni e modelli più semplici mantenendo però i pattern importanti. Ma gli strumenti più diffusi richiedono spesso molte scelte manuali e aggiustamenti per tentativi ed errori. Questo articolo presenta un modo per lasciare che siano i dati a decidere come comprimere al meglio, con l’obiettivo di ottenere rappresentazioni più chiare, apprendimento più accurato e meno congetture da parte dell’utente.
Da linee semplici a realtà curve
Uno strumento classico per semplificare i dati, l’Analisi delle Componenti Principali, funziona come illuminare un oggetto e osservare la sua ombra: individua le direzioni piane migliori che spiegano la maggior parte della variazione. Questo è efficace quando la struttura dei dati è approssimativamente lineare o piatta. Ma i dati reali — come immagini, testi o letture da sensori — spesso giacciono su superfici curve nascoste in spazi ad alta dimensionalità. Negli ultimi vent’anni sono stati progettati nuovi metodi “non lineari” come Isomap, Locally Linear Embedding (LLE), embedding spettrale e UMAP proprio per scoprire queste forme tortuose. Essi si basano su vicinanze locali: per ogni punto si osservano i vicini più prossimi e si cerca di preservare quelle relazioni su piccola scala nel disegno a dimensione ridotta. Tuttavia, questi metodi costringono l’utente a scegliere due manopole chiave: quanti vicini usare e su quante dimensioni proiettare. Sceglierle male può portare a risultati fuorvianti o a costi computazionali elevati.
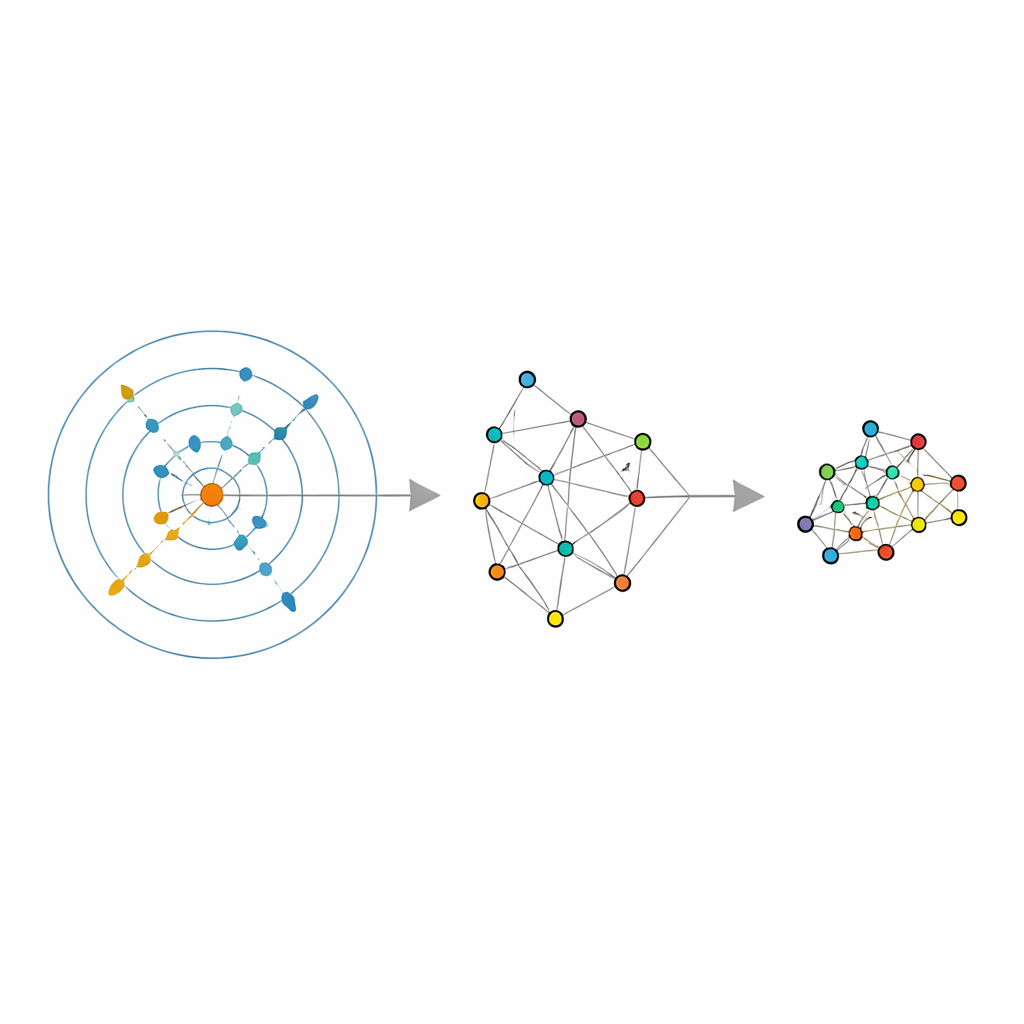
Lascare che siano i dati a scegliere il proprio vicinato
Gli autori si basano su un recente strumento statistico chiamato stimatore della dimensione intrinseca, che cerca di rispondere a una domanda semplice: in quante direzioni indipendenti i dati variano veramente, una volta eliminato il rumore? Il loro stimatore, chiamato ABIDE, va oltre. Intorno a ciascun punto cerca automaticamente un vicinato che appaia ragionevolmente uniforme — né troppo piccolo e affetto da rumore né troppo grande e distorto. In tal modo restituisce due informazioni: una stima globale della dimensione reale dei dati e una dimensione di vicinato su misura per ogni punto. Questo trasforma il solito “numero fisso di vicini” in una quantità adattiva locale che può crescere nelle regioni sparse e ridursi in quelle dense, adeguandosi alla reale densità dei dati.
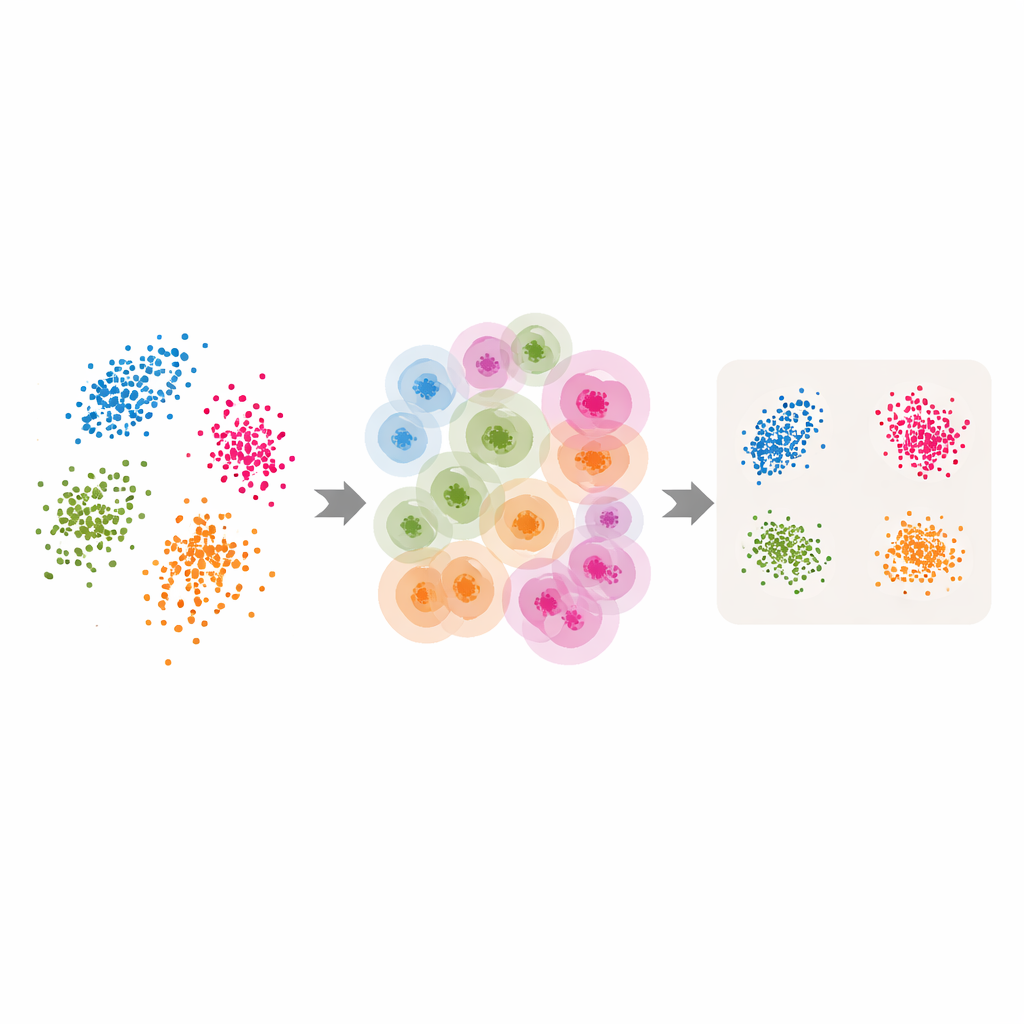
Trasformare strumenti classici in strumenti adattivi
Dotati di questi vicinati adattivi e della stima della dimensione intrinseca, gli autori aggiornano diversi metodi popolari di riduzione della dimensionalità e clustering. Per LLE sostituiscono il singolo numero di vicini scelto dall’utente con i valori per punto restituiti da ABIDE, e impostano la dimensione target uguale alla dimensione intrinseca stimata. L’algoritmo apprende così come ricostruire ogni punto a partire da un gruppo locale scelto con cura prima di trovare un assetto globale a bassa dimensionalità che preservi al meglio queste ricostruzioni locali. Idee simili sono applicate al clustering spettrale — dove un grafo di similarità fra punti è usato per raggruppare — e a UMAP, che costruisce una mappa fuzzy delle connessioni fra punti. In ciascun caso la dimensione del vicinato rigida viene sostituita da una struttura flessibile guidata dai dati che segue la geometria naturale dei punti.
Test su fiori, cifre, testi e forme sintetiche
Per verificare se questo approccio adattivo dia benefici, gli autori conducono esperimenti su diversi benchmark: le classiche misure del fiore Iris, immagini di cifre scritte a mano (MNIST), articoli di notizie rappresentati tramite embedding di modelli linguistici e forme tridimensionali sintetiche con rumore aggiunto. Confrontano le versioni adattive con le impostazioni software standard e con griglie di iperparametri accuratamente ottimizzate. In compiti non supervisionati come clustering e visualizzazione, i metodi adattivi tipicamente producono cluster più chiari, raggruppamenti più compatti e punteggi migliori nelle misure di qualità standard. Per esempio, su varietà complesse con densità di punti non uniforme, i metodi adattivi recuperano la struttura reale molto meglio delle versioni a vicini fissi. Nei test supervisionati, dove i dati ridotti sono forniti a un classificatore, l’approccio adattivo eguaglia o supera nuovamente le migliori scelte a impostazione fissa, senza necessitare di una sintonizzazione esaustiva.
Cosa significa per l’analisi dei dati di tutti i giorni
Per non esperti e professionisti, il messaggio principale è che ridurre i dati non deve basarsi sul tentativo e errore. Usando la geometria intrinseca dei dati per decidere “quanti vicini” e “quante dimensioni”, questo quadro trasforma strumenti ampiamente usati come LLE, clustering spettrale e UMAP in versioni più intelligenti e robuste di se stessi. Il risultato sono viste a bassa dimensionalità più affidabili — grafici e caratteristiche che riflettono meglio la forma reale dei dati — riducendo spesso il tempo dedicato alla ricerca manuale degli iperparametri. In termini pratici, ciò significa che compiti come visualizzare grandi collezioni di immagini, raggruppare documenti o preparare input per modelli predittivi possono diventare sia più semplici sia più affidabili, semplicemente lasciando che siano i dati a guidare in modo adattivo la loro compressione.
Citazione: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
Parole chiave: riduzione della dimensionalità, apprendimento di varietà, vicini più prossimi, dimensione intrinseca, visualizzazione dei dati