Clear Sky Science · it
Ottimizzatore basato sulla distribuzione normale generalizzata migliorata con metodo di riparazione gaussiana e apprendimento inverso di Cauchy per la selezione delle caratteristiche
Perché è importante scegliere i dati giusti
La vita moderna si basa sui dati, dalle scansioni mediche ai registri bancari fino ai flussi dei social media. Ma più dati non sono sempre meglio. Quando si chiede ai computer di apprendere da migliaia di misurazioni grezze contemporaneamente, possono diventare più lenti, più costosi da eseguire e, sorprendentemente, meno accurati. Questo articolo presenta un modo più intelligente per setacciare tutte quelle misurazioni e conservare solo quelle davvero rilevanti, usando un nuovo algoritmo chiamato Binary Adaptive Generalized Normal Distribution Optimizer, o BAGNDO.
Il problema di troppe informazioni
Immaginate di diagnosticare una malattia con centinaia di esami di laboratorio, scansioni e risposte a questionari. Molte di queste “caratteristiche” possono essere rumorose, ridondanti o semplicemente irrilevanti, e fornirle tutte a un classificatore può confondere più che aiutare. La selezione delle caratteristiche mira a scegliere un sottoinsieme più piccolo e informativo di input in modo che i modelli di machine learning diventino più veloci, meno costosi e più affidabili. Filtri statistici semplici possono rimuovere le caratteristiche chiaramente inutili, ma non adattano le loro scelte al modello specifico in uso e spesso perdono combinazioni sottili di variabili. Metodi più avanzati di tipo “wrapper” valutano i set di caratteristiche testando direttamente quanto bene si comporta un classificatore, ma questo genera un enorme problema di ricerca: il numero di possibili sottoinsiemi esplode all’aumentare del numero di caratteristiche.
Cercare con intelligenza invece che alla cieca
Per gestire questa esplosione, i ricercatori fanno affidamento su algoritmi metaeuristici—strategie di ricerca ispirate a processi naturali o fisici che bilanciano una esplorazione ampia con un raffinamento mirato. Uno di questi metodi, il Generalized Normal Distribution Optimizer (GNDO), tratta le soluzioni candidate come se fossero estratte da una curva a campana flessibile e sposta gradualmente questa curva verso risposte migliori. GNDO ha funzionato bene in applicazioni ingegneristiche e energetiche, ma tende a stabilizzarsi troppo presto su soluzioni mediocri e fatica a bilanciare l’esplorazione globale con la messa a punto locale quando applicato alla selezione delle caratteristiche. Gli autori identificano questa come una lacuna critica: la matematica elegante di GNDO non si traduce automaticamente in prestazioni solide su decisioni binarie ad alta dimensionalità su quali caratteristiche conservare.
Un potenziamento in tre parti per un motore classico
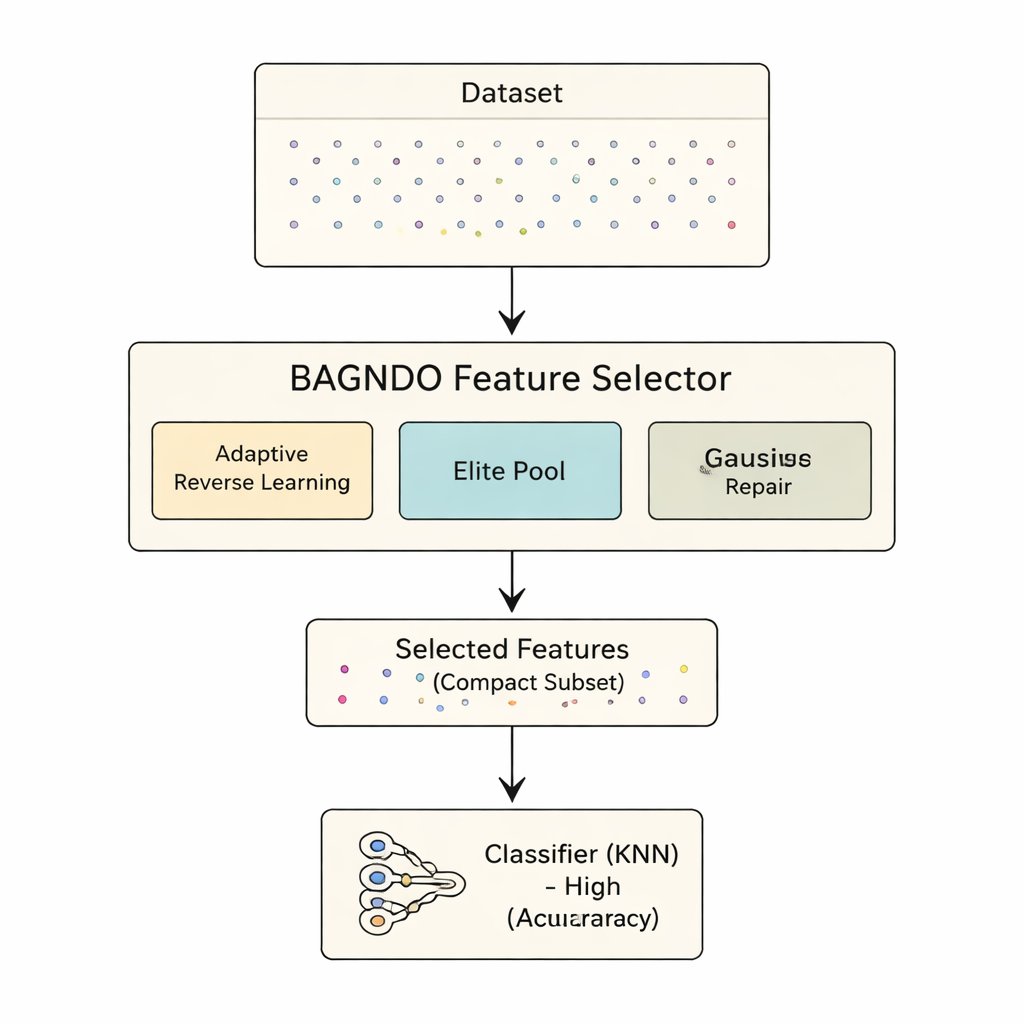
Il framework proposto BAGNDO migliora GNDO con tre idee coordinate. Primo, una strategia Adaptive Cauchy Reverse Learning genera regolarmente versioni “speculari” delle soluzioni correnti usando una distribuzione di probabilità a coda pesante. Questo incoraggia salti audaci in regioni inesplorate dello spazio di ricerca, evitando che l’algoritmo rimanga intrappolato in minimi locali. Secondo, una Elite Pool Strategy mantiene non solo la singola migliore soluzione, ma un piccolo gruppo di migliori performer più un candidato “guida” miscelato. Questo gruppo di leadership più ricco aiuta a mantenere la diversità pur orientando la ricerca verso regioni promettenti. Terzo, un metodo di riparazione delle peggiori soluzioni basato sulla distribuzione gaussiana osserva i candidati più deboli e li spinge verso schemi appresi dal gruppo elite, riciclando efficacemente le soluzioni scadenti in soluzioni migliori invece di scartarle del tutto.
Mettere il metodo alla prova
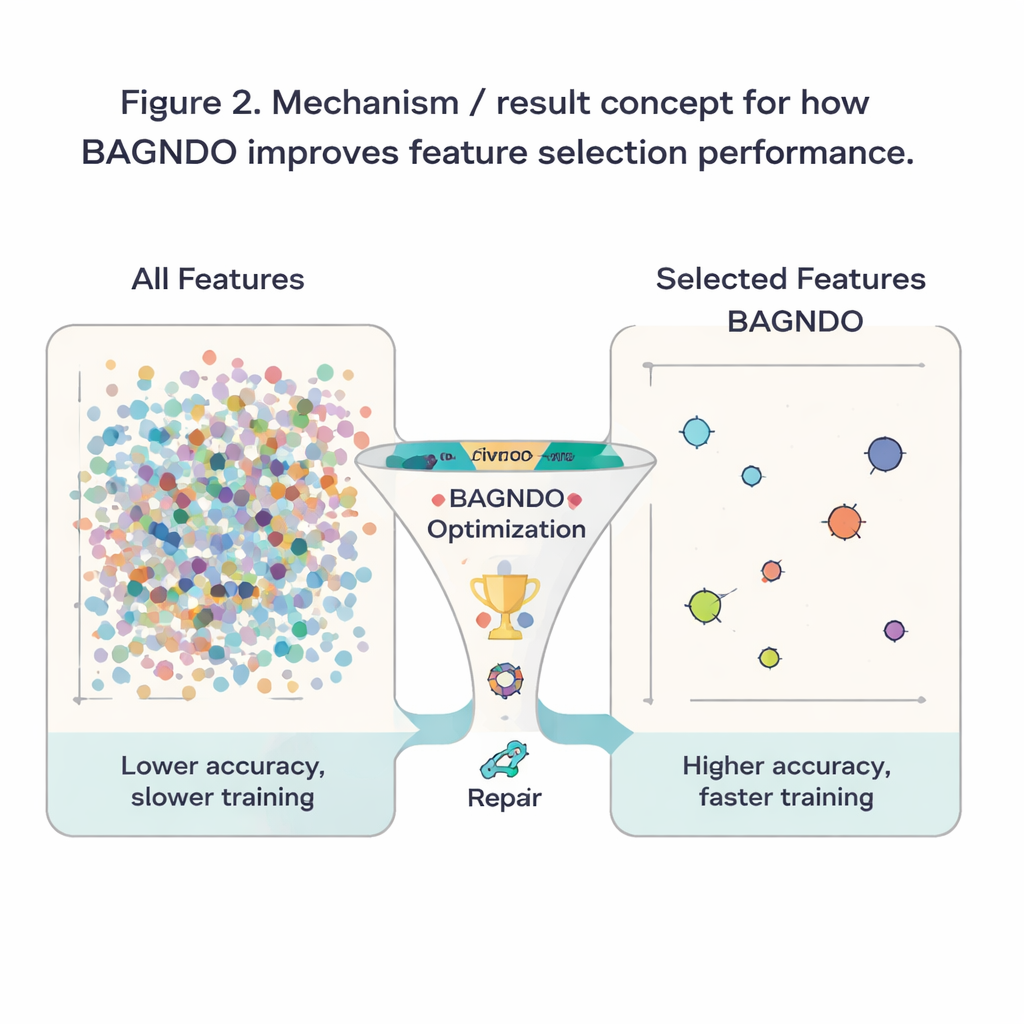
Per verificare se queste idee funzionano nella pratica, gli autori hanno applicato BAGNDO a 18 dataset di riferimento ben noti dal repository UCI, che coprono diagnosi mediche, giochi, segnali e altro. In ogni caso, l’algoritmo ha cercato un sottoinsieme di caratteristiche che permettesse a un classificatore k-nearest neighbors standard di fare predizioni accurate. BAGNDO è stato confrontato con nove forti competitor, tra cui particle swarm optimization, metodi di tipo genetico e diversi algoritmi ispirati agli sciami moderni. In questi test, BAGNDO ha costantemente trovato set di caratteristiche più piccoli mantenendo, e spesso migliorando, l’accuratezza predittiva. Ha ottenuto la migliore accuratezza con i sottinsiemi di caratteristiche più compatti in 14 dei 18 dataset, e test statistici hanno confermato che questi guadagni non sono dovuti al caso.
Cosa significa per il machine learning di tutti i giorni
Per un lettore non specialista, il risultato si può riassumere così: gli autori hanno costruito un “selettore di caratteristiche” più disciplinato che aiuta gli algoritmi di apprendimento a concentrarsi su ciò che conta davvero in un dataset. Bilanciando meglio esplorazione ampia, guida da parte degli elite e riparazione dei candidati deboli, BAGNDO elimina input non necessari mantenendo o migliorando l’accuratezza. Questo significa modelli più veloci, costi di archiviazione e calcolo ridotti e spesso una comprensione più chiara di quali misurazioni o domande siano più informative. Sebbene il metodo sia più esigente in termini computazionali rispetto ad alcune alternative più semplici, offre uno strumento potente per problemi in cui accuratezza e interpretabilità sono fondamentali, dal supporto decisionale medico al monitoraggio industriale e oltre.
Citazione: Ghetas, M., Elaziz, M.A. & Issa, M. Enhanced generalized normal distribution optimizer with Gaussian distribution repair method and cauchy reverse learning for features selection. Sci Rep 16, 4794 (2026). https://doi.org/10.1038/s41598-026-35804-y
Parole chiave: selezione delle caratteristiche, ottimizzazione metaeuristica, apprendimento automatico, riduzione della dimensionalità, accuratezza di classificazione