Clear Sky Science · it
Metodi di kernel quantistici per l’analisi di marketing con teoria della convergenza e limiti di separazione
Perché previsioni sui clienti più intelligenti sono importanti
Le aziende fanno sempre più affidamento sui dati per decidere quali clienti indirizzare con offerte, assistenza o campagne di fidelizzazione. Ma man mano che i dati diventano più complessi, gli strumenti tradizionali possono faticare a individuare schemi sottili, soprattutto quando ogni cliente di alto valore perso ha un costo rilevante. Questo articolo esplora se i computer quantistici emergenti — macchine che sfruttano le regole della fisica quantistica — possano migliorare queste previsioni per problemi di tipo marketing, considerando con chiarezza l’hardware imperfetto e “rumoroso” di oggi.

Dai record dei clienti ai circuiti quantistici
Gli autori si concentrano su un compito pratico che chiamano classificazione dei consumatori: prevedere quali utenti interagiranno con o adotteranno un servizio digitale. Ogni utente è descritto da un piccolo insieme di caratteristiche numeriche, come dati demografici e comportamenti sulla piattaforma. Invece di inserire questi dati direttamente in un algoritmo classico, li codificano prima negli stati di pochi bit quantistici (qubit) usando un circuito quantistico compatto. Questo circuito funge da trasformazione delle caratteristiche, rimodellando i dati in una forma che potrebbe essere più facilmente separabile in due gruppi — “probabile che interagisca” e “improbabile che interagisca”. Sulla trasformazione quantistica applicano poi un noto metodo di classificazione, la macchina a vettori di supporto, in una versione con sapore quantistico chiamata SVM a kernel quantistico (Q-SVM).
Testare idee quantistiche in condizioni realistiche
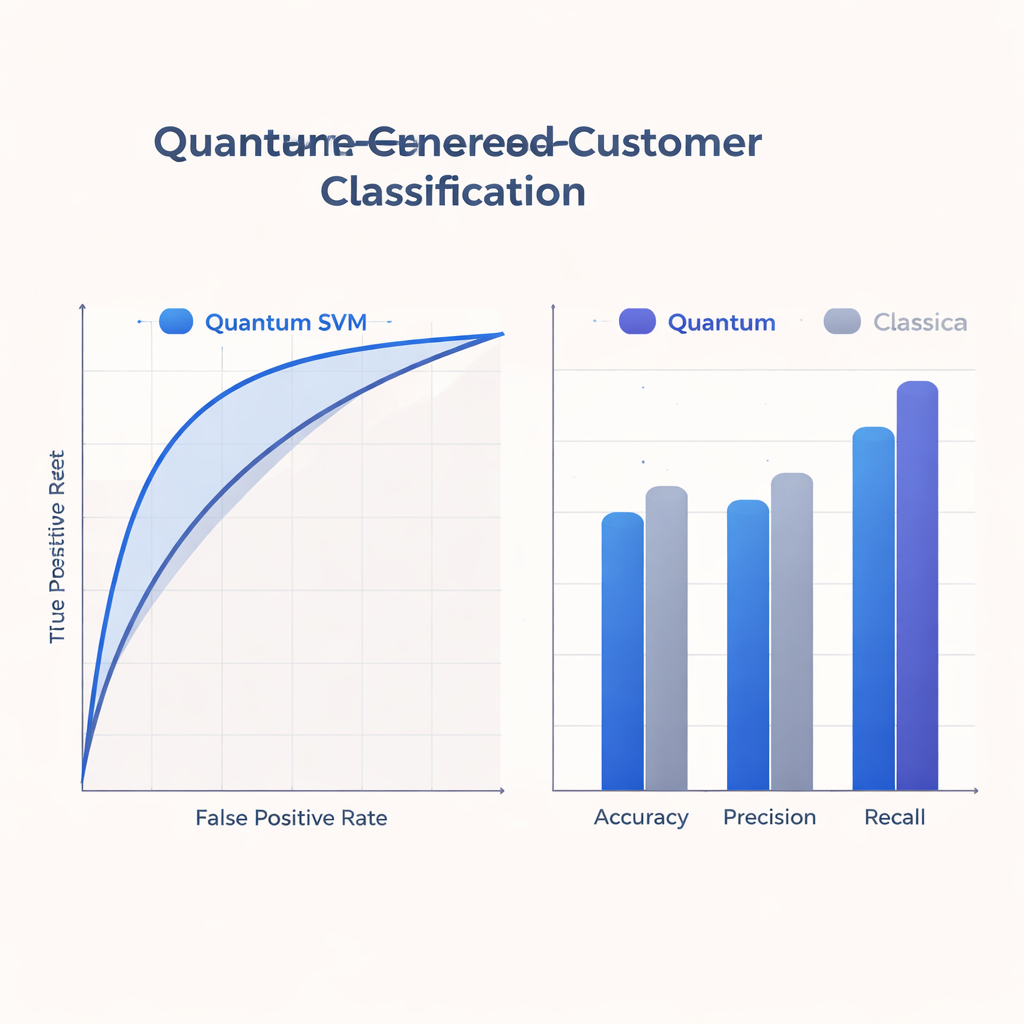
Poiché i dispositivi quantistici odierni sono piccoli e soggetti a errori, lo studio rimane su circuiti poco profondi che corrispondono a ciò che l’hardware a breve termine può gestire. Il team allena e valuta il loro Q-SVM su un set di dati reale anonimizzato di circa 500 casi di addestramento e 125 di test con otto caratteristiche per utente, simulando sia il comportamento quantistico ideale sia quello rumoroso. Confrontano l’approccio quantistico con solidi riferimenti classici che usano noti kernel su computer tradizionali. Su accuratezza, precisione, richiamo e area sotto la curva ROC (un riepilogo del compromesso tra intercettare positivi ed evitare falsi allarmi), il Q-SVM offre prestazioni competitive o migliori, con un richiamo particolarmente elevato: identifica correttamente una frazione più alta di utenti effettivamente interessati rispetto ai modelli classici.
Garanzie teoriche dietro le quinte
Oltre alla performance grezza, l’articolo si pone una domanda più profonda: quando ci si può aspettare che i metodi quantistici apportino realmente vantaggi? Gli autori sviluppano tre risultati teorici principali. Primo, mostrano che se il problema di apprendimento soddisfa certe condizioni di regolarità e i circuiti quantistici restano poco profondi, il processo di addestramento per i kernel quantistici dovrebbe convergere in modo affidabile in un numero ragionevole di passi. Secondo, forniscono limiti di separazione che suggeriscono come la loro estrazione quantistica delle caratteristiche possa, sotto specifiche ipotesi, aumentare il divario tra le due classi di clienti rispetto alle trasformazioni classiche — rendendo essenzialmente il problema più facile da risolvere. Terzo, analizzano come metodi approssimati possano ridurre drasticamente il costo di lavorare con ampi spazi di caratteristiche derivati quantisticamente, in modo che l’approccio resti computazionalmente fattibile.
Cosa potrebbe significare per i responsabili marketing
Per i team di marketing e analisi clienti, il beneficio più concreto riguarda il bilancio tra opportunità perse e spese di contatto inutili. L’elevato richiamo del Q-SVM significa che è meno probabile che trascuri utenti che risponderebbero positivamente a un’offerta, un vantaggio cruciale nelle campagne di fidelizzazione o di servizio proattivo. Allo stesso tempo, la sua precisione e l’accuratezza complessiva rimangono in un range comparabile ai solidi riferimenti classici, supportati da una curva ROC robusta. Poiché il metodo funziona bene su una gamma di soglie decisionali, i team potrebbero regolare quanto essere aggressivi o prudenti — favorendo richiamo o precisione — senza dover riaddestrare il modello ogni volta.
Un inizio promettente, non ancora una rivoluzione quantistica
Gli autori sottolineano che i risultati rappresentano passi iniziali, non la prova di una supremazia quantistica totale. I risultati derivano da simulazioni su un dataset, non da esecuzioni su larga scala su hardware reale o su molti mercati diversi. Le loro garanzie matematiche si basano inoltre su ipotesi idealizzate che potrebbero non valere completamente su dispositivi rumorosi. Tuttavia, il lavoro dimostra che kernel quantistici progettati con cura possono già eguagliare o leggermente superare buoni metodi classici su un compito di consumo realistico, offrendo al contempo una strada chiara verso vantaggi maggiori man mano che l’hardware quantistico scala. Per i lettori, la conclusione è che l’apprendimento automatico quantistico sta passando dalla promessa astratta a strumenti che un giorno potrebbero rendere le previsioni sui clienti più accurate e flessibili in contesti aziendali reali.
Citazione: Sáez Ortuño, L., Forgas Coll, S. & Ferrara, M. Quantum kernel methods for marketing analytics with convergence theory and separation bounds. Sci Rep 16, 6645 (2026). https://doi.org/10.1038/s41598-026-35793-y
Parole chiave: apprendimento automatico quantistico, analisi di marketing, classificazione dei clienti, macchine a vettori di supporto, kernel quantistici