Clear Sky Science · it
Generazione sicura di dati per casi di test multi-parte tramite reti generative avversarie
Perché i test software più intelligenti contano
Le fabbriche moderne, le reti elettriche e gli impianti industriali funzionano grazie a software complessi che devono comunicare perfettamente su reti digitali. Un piccolo errore nello scambio di messaggi tra due sistemi può causare guasti alle apparecchiature, incidenti di sicurezza o attacchi informatici. Eppure i dati di test necessari per trovare questi bug nascosti sono spesso dispersi tra molte organizzazioni, vincolati da regole sulla privacy e segreti aziendali. Questo articolo presenta un nuovo modo per le aziende di collaborare alla generazione di casi di test efficaci senza condividere mai i loro dati sensibili grezzi.
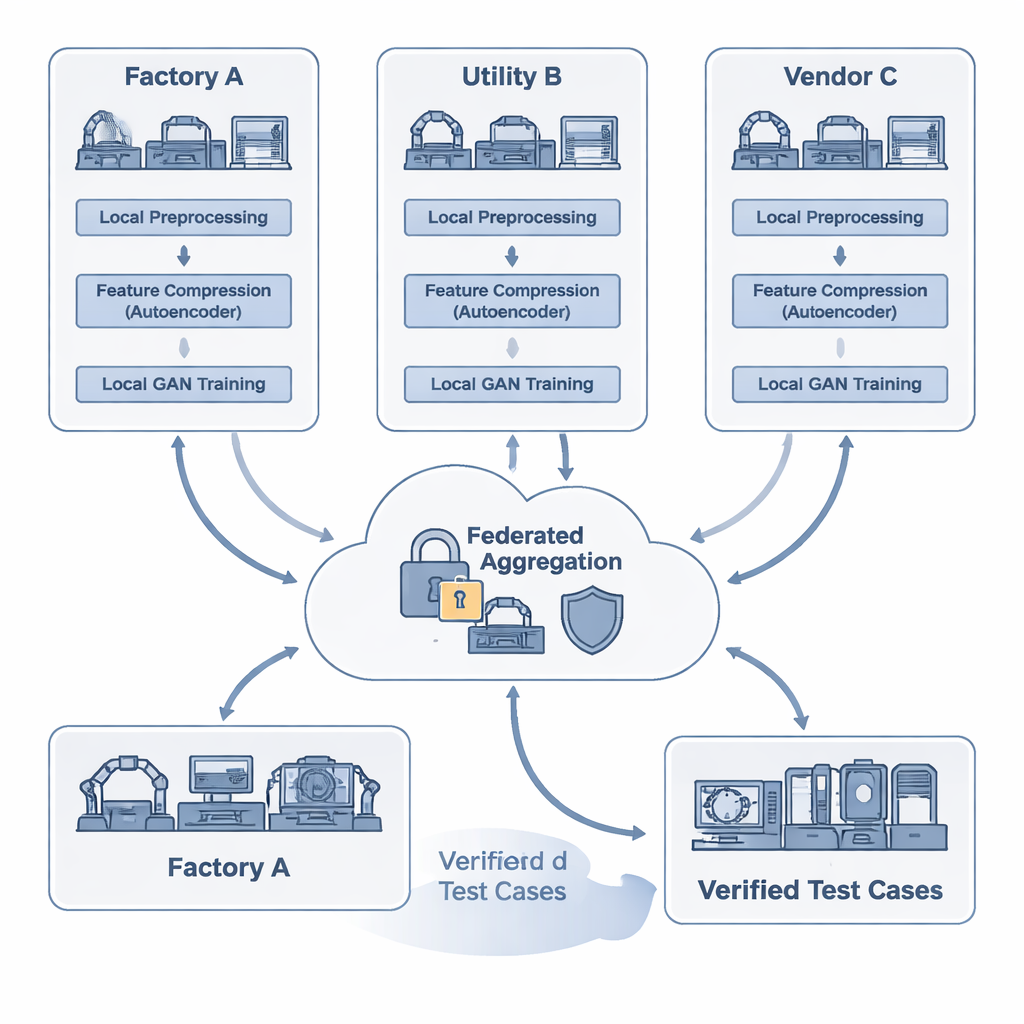
La sfida del testing in un mondo connesso
Gli strumenti di testing tradizionali sono stati progettati per un’epoca più semplice, quando un’unica squadra controllava la maggior parte del codice e dei dati. Le reti industriali odierne sono molto diverse: dispositivi di molti fornitori, che parlano protocolli di comunicazione rigorosi, sono distribuiti tra fabbriche, imprese di servizi e fornitori. Ogni organizzazione vede solo una parte del traffico, e leggi o contratti spesso vietano di aggregare i log. Di conseguenza, suite di test costruite in isolamento possono non cogliere combinazioni rare di messaggi che appaiono solo quando sistemi di proprietari diversi interagiscono. Anche gli strumenti di privacy esistenti, che offuscano o rimuovono campi sensibili, non sono sufficienti: se si “generalizzano” troppo i dati di protocollo, i messaggi smettono semplicemente di essere validi e non possono più essere usati per test realistici.
Un framework collaborativo ma orientato alla privacy
I ricercatori propongono FAT-CG, un framework che permette a più parti di addestrare congiuntamente un generatore di dati di test mantenendo segreti i loro dettagli dei tracciati di protocollo. A livello locale, ogni partecipante pulisce e anonimizza i propri dati, quindi li alimenta in un autoencoder, un tipo di rete neurale che comprime i messaggi in sommari numerici compatti. Questi sommari sono sufficientemente ricchi da preservare la grammatica e la struttura dei protocolli industriali, ma non espongono più indirizzi grezzi o valori proprietari. Invece di spedire i log, le organizzazioni condividono solo aggiornamenti di modello crittografati. Un coordinatore centrale usa crittografia speciale (crittografia omomorfica) e rumore aggiunto con cura (privacy differenziale) per combinare questi aggiornamenti in un modello condiviso più forte, senza essere in grado di ricostruire il traffico originale di nessun partecipante.
Insegnare alle macchine a creare casi di test efficaci
Al centro di FAT-CG c’è una Generative Adversarial Network (GAN), una coppia di reti neurali che competono tra loro. Una rete, il generatore, cerca di produrre nuovi messaggi di protocollo; l’altra, il discriminatore, cerca di distinguere i messaggi reali da quelli falsi. Nel tempo, questa competizione spinge il generatore a imparare modelli sottili su come sono strutturati i messaggi validi. FAT-CG introduce un’altra svolta: descrizioni formali delle regole di protocollo vengono usate per controllare ogni messaggio generato, e le violazioni vengono penalizzate durante l’addestramento. Questo mantiene il traffico sintetico sia realistico che vario. Il sistema funziona in un ciclo: una volta generati, i messaggi vengono inviati a dispositivi industriali simulati in una sandbox. I casi che causano crash, perdite di memoria o risposte anomale vengono reinseriti nel processo di addestramento, spingendo il generatore verso gli angoli più promettenti dello spazio di ricerca.
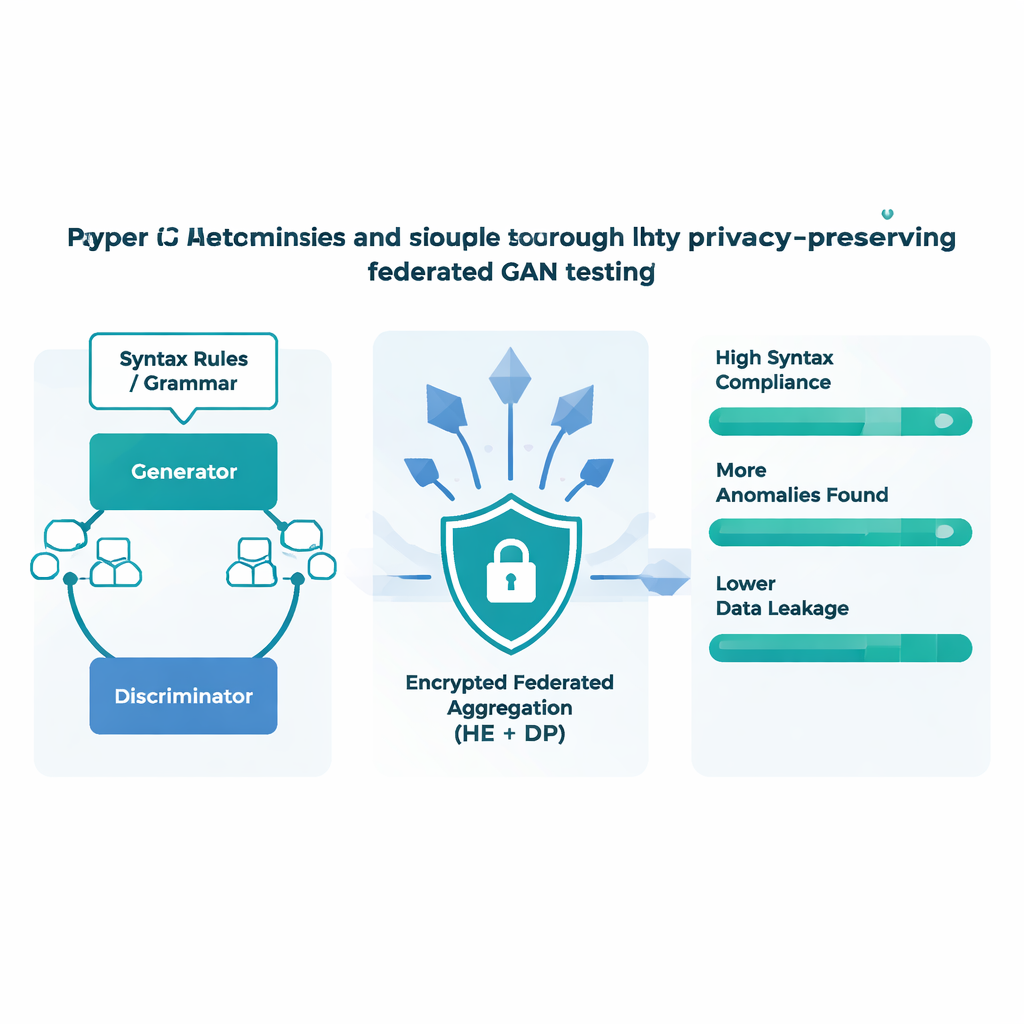
Privacy, velocità e individuazione di bug nei test reali
Il team ha testato FAT-CG su diversi protocolli industriali comuni, inclusi Modbus-TCP e OPC UA, usando un setup realistico con più dispositivi edge e un server centrale. Rispetto agli strumenti di fuzzing esistenti e ai metodi di apprendimento federato più semplici, il nuovo approccio ha prodotto messaggi di test che rispettavano le regole di protocollo per oltre il 90% dei casi e ha scoperto quasi tre volte più anomalie per mille test. Allo stesso tempo, le sue difese stratificate hanno ridotto nettamente il rischio che un attaccante potesse ricostruire i dati di addestramento dagli aggiornamenti di modello condivisi. Comprimendo le caratteristiche del protocollo in codici piccoli e strutturati prima della cifratura, il sistema ha anche ridotto l’overhead di comunicazione di quasi un fattore trenta, accorciando i round di addestramento e rendendolo praticabile per reti industriali con larghezza di banda limitata.
Cosa significa per i sistemi critici
In termini pratici, questo lavoro dimostra che le aziende che gestiscono infrastrutture critiche non devono scegliere tra mantenere privati i propri dati e testare accuratamente i loro sistemi. FAT-CG offre un modo per molte parti di mettere insieme la loro conoscenza sul comportamento delle reti reali, senza mai cedere i log sensibili. Il risultato è un generatore di test condiviso che parla meglio il “linguaggio” dei dispositivi industriali e che è più efficace nello scatenare casi limite pericolosi—esattamente il tipo di strumento necessario per scoprire vulnerabilità prima che provochino interruzioni o incidenti. Sebbene lo studio si concentri sui protocolli industriali, le stesse idee potrebbero aiutare in altri ambiti sensibili, come la sanità o la finanza, dove le organizzazioni devono collaborare su sicurezza e affidabilità senza sacrificare la riservatezza.
Citazione: Wang, Z., Zhao, L., Meng, F. et al. Secure multi-party test case data generation through generative adversarial networks. Sci Rep 16, 5085 (2026). https://doi.org/10.1038/s41598-026-35773-2
Parole chiave: testing del software industriale, apprendimento federato, reti generative avversarie, IA che preserva la privacy, fuzzing di protocolli di rete