Clear Sky Science · it
Fusione di immagini infrarosse e visibili tramite miglioramento visivo e accoppiamento semantico
Visione più nitida da telecamere diurne e notturne
Auto moderne, droni e sistemi di sicurezza spesso dispongono di due tipi di «occhi»: una fotocamera normale che cattura colore e texture e una fotocamera a infrarossi che rileva il calore. Ognuna ha punti di forza e limiti, e combinarle in un’unica immagine chiara è sorprendentemente difficile. Questo articolo presenta un nuovo metodo per fondere questi due punti di vista in un’unica immagine che non solo è più facile da guardare, ma anche più facile da interpretare per i programmi informatici.
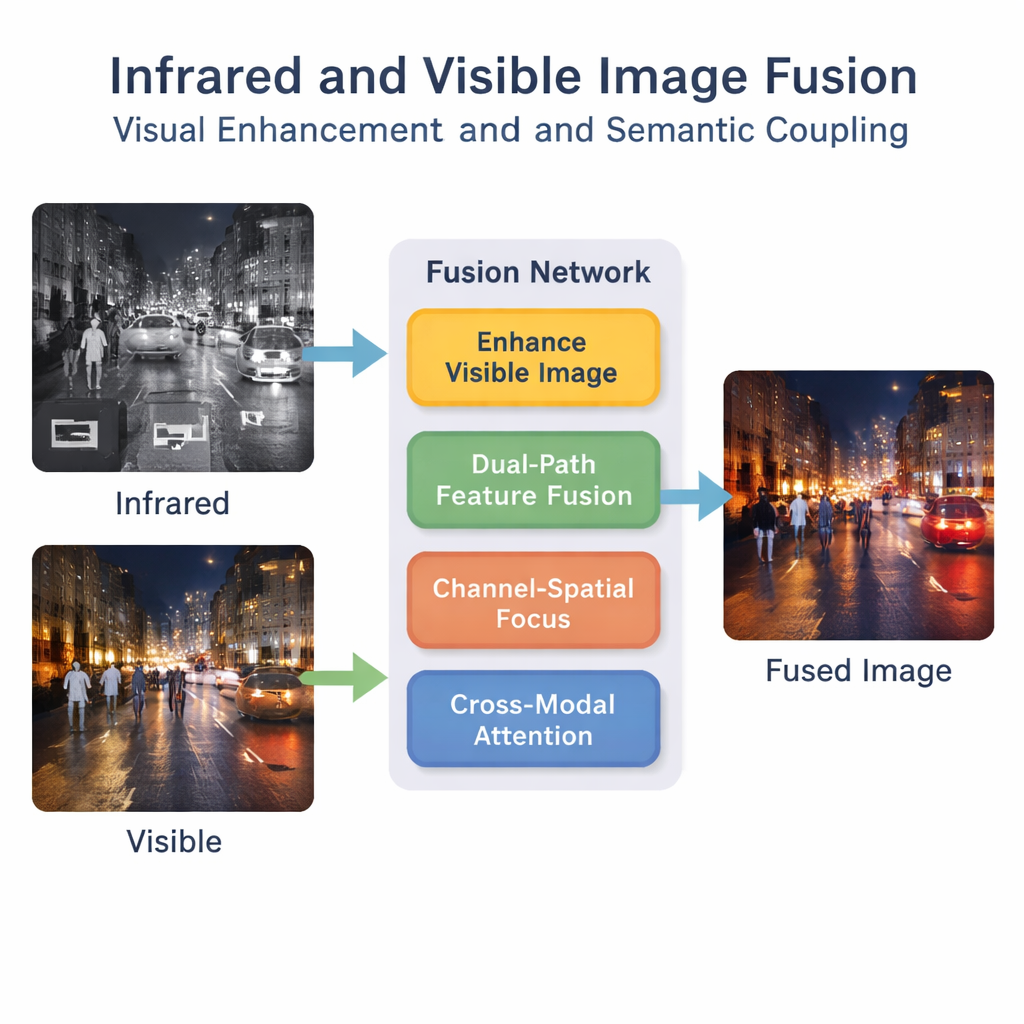
Perché due occhi sono meglio di uno
Le fotocamere in luce visibile catturano dettagli nitidi come segnali stradali, contorni degli edifici e indumenti, ma fanno fatica di notte, nella nebbia o quando gli oggetti si confondono con lo sfondo. Le fotocamere a infrarossi fanno l’opposto: evidenziano oggetti caldi come persone e veicoli anche al buio, ma le loro immagini risultano sfocate e prive di dettagli fini. Fondere questi due punti di vista in un’immagine «il meglio dei due mondi» può aiutare in compiti che vanno dal rilevamento di pedoni nei sistemi di assistenza alla guida alla sorveglianza e al soccorso. Tuttavia, molti metodi di fusione esistenti si concentrano solo su caratteristiche superficiali — punti luminosi dell’infrarosso e texture dell’immagine visibile — trascurando il significato più profondo a livello di scena che conta per le macchine intelligenti.
Un modo più intelligente di combinare le immagini
Gli autori propongono un framework di apprendimento profondo che considera la fusione come qualcosa di più di una semplice sovrapposizione. Prima, un passaggio di miglioramento speciale illumina e bilancia l’immagine visibile, soprattutto nelle scene a bassa luminosità, in modo che i dettagli preziosi non vadano persi prima ancora che inizi la fusione. Poi una rete a doppio percorso elabora in parallelo gli input infrarosso e visibile. Un percorso si concentra su pattern locali come bordi e texture, mentre l’altro osserva il contesto più ampio della scena. Combinando questi percorsi, il sistema produce una descrizione interna più ricca di ciò che accade nelle immagini.
Insegnare alla rete a cosa prestare attenzione
Estrarre molte caratteristiche non basta; la rete deve apprendere quali sono importanti. Un modulo “canale–spaziale” aiuta il modello a evidenziare regioni e tipi di informazione critici, come pedoni o fari luminosi, ridimensionando invece il rumore di sfondo meno utile. Su questo si innesta un meccanismo di attenzione interattiva bimodale che incoraggia i flussi infrarosso e visibile a comunicare tra loro. Impara come le firme termiche e le texture visive si allineano nella scena, catturando concetti di livello superiore come “questo alone luminoso nell’infrarosso corrisponde a quella persona nell’immagine visibile”. Questo accoppiamento semantico aiuta l’immagine fusa a rimanere logicamente consistente anziché solo visivamente amalgamata.

Mettere il metodo alla prova
Per verificare se le immagini fuse sono non solo gradevoli ma anche realistiche, gli autori aggiungono una rete discriminatrice simile a quelle usate nelle reti antagoniste generative. Questa rete supplementare impara a distinguere immagini visibili reali da quelle fuse, spingendo il processo di fusione a produrre output che appaiono naturali sia agli esseri umani sia alle macchine. Il metodo è addestrato e testato su tre raccolte impegnative di coppie di immagini infrarosso–visibile, coprendo strade diurne e notturne e scene in stile militare. Su una serie di misure standard di qualità, il nuovo approccio generalmente supera dieci tecniche di fusione esistenti, producendo immagini con contorni più netti, migliore contrasto e contenuti più informativi.
Immagini migliori per macchine più sicure
Oltre alla qualità visiva, gli autori pongono una domanda pratica: queste immagini fuse aiutano i computer a prendere decisioni migliori? Usando un sistema di rilevamento di oggetti popolare per individuare i pedoni, mostrano che le loro immagini fuse migliorano la precisione del rilevamento rispetto sia alle immagini di un singolo sensore sia ai metodi di fusione precedenti. In termini concreti, la tecnica crea immagini più facili da interpretare sia per gli esseri umani sia per gli algoritmi, specialmente in condizioni difficili come la guida notturna. Sebbene il sistema richieda ancora ottimizzazioni per l’uso in tempo reale su dispositivi con risorse limitate, rappresenta un passo promettente verso una visione più sicura e affidabile nei veicoli automatizzati, nella sorveglianza e in altre tecnologie che devono vedere chiaramente quando conta di più.
Citazione: Yang, Y., Li, Y., Li, J. et al. Infrared and visible image fusion via visual enhancement and semantic coupling. Sci Rep 16, 5666 (2026). https://doi.org/10.1038/s41598-026-35763-4
Parole chiave: fusione di immagini, imaging a infrarossi, visione in condizioni di scarsa luminosità, apprendimento profondo, rilevamento di oggetti