Clear Sky Science · it
Sentinella acustica: classificazione gerarchica del suono dei passi utilizzando rappresentazioni di caratteristiche acustiche fini e grossolane per la sorveglianza tattica
Ascoltare passi nascosti
Immaginate di rilevare persone che si muovono attraverso una foresta buia o lungo un confine remoto senza una sola telecamera in vista—solo ascoltando i loro passi. Questo studio esplora come i suoni sottili prodotti dal camminare possano diventare uno strumento di allerta precoce potente per soldati, forze di polizia e investigatori, specialmente in luoghi dove le telecamere falliscono o l'energia è scarsa.
Perché le telecamere non bastano
La sicurezza moderna spesso si basa sulla videosorveglianza, ma le telecamere hanno debolezze evidenti: hanno bisogno di una linea di vista diretta, consumano molta energia e possono essere difficili da installare rapidamente in terreni accidentati o ostili. Checkpoint mobili, pattuglie di confine e team antiterrorismo possono operare di notte, sotto una fitta copertura vegetale o in regioni montuose dove installare e mantenere reti di telecamere è impraticabile. In queste situazioni, il suono diventa un'alternativa interessante. I microfoni sono leggeri, consumano meno energia e possono “sentire oltre gli angoli”, captando persone prima che siano visibili. I passi, sebbene relativamente silenziosi, emergono in molti scenari tattici dove il rumore di fondo è basso, rendendoli un segnale promettente per allerta precoce e ricostruzione forense degli eventi.
Costruire una libreria di passi realistica
Per trasformare questa idea in un sistema funzionante, i ricercatori hanno prima dovuto risolvere un problema di base: non esisteva una raccolta adeguata di registrazioni reali di passi. I database sonori esistenti includono alcuni passi principalmente per riconoscimento generico dei suoni o per il confronto di identità, spesso registrati in condizioni di laboratorio controllate. Di norma non indicano se il suono provenga da una foresta, da una strada o da ambienti interni, né se sia prodotto da una sola persona o da più individui. Il team ha quindi creato una nuova risorsa chiamata dataset EWFootstep 1.0. Contiene 1.650 clip audio provenienti da 176 volontari che camminano naturalmente attraverso foreste, strade e spazi interni in tre diverse regioni dell'India. Le registrazioni includono una combinazione di suole morbide e dure, vari terreni e condizioni realistiche di campo come posizionamento non uniforme dei microfoni. Ogni clip contiene almeno 15 passi ed è etichettata sia per tipo di ambiente sia per la presenza di una singola persona o di un gruppo.
Insegnare a una macchina a sentire come una sentinella
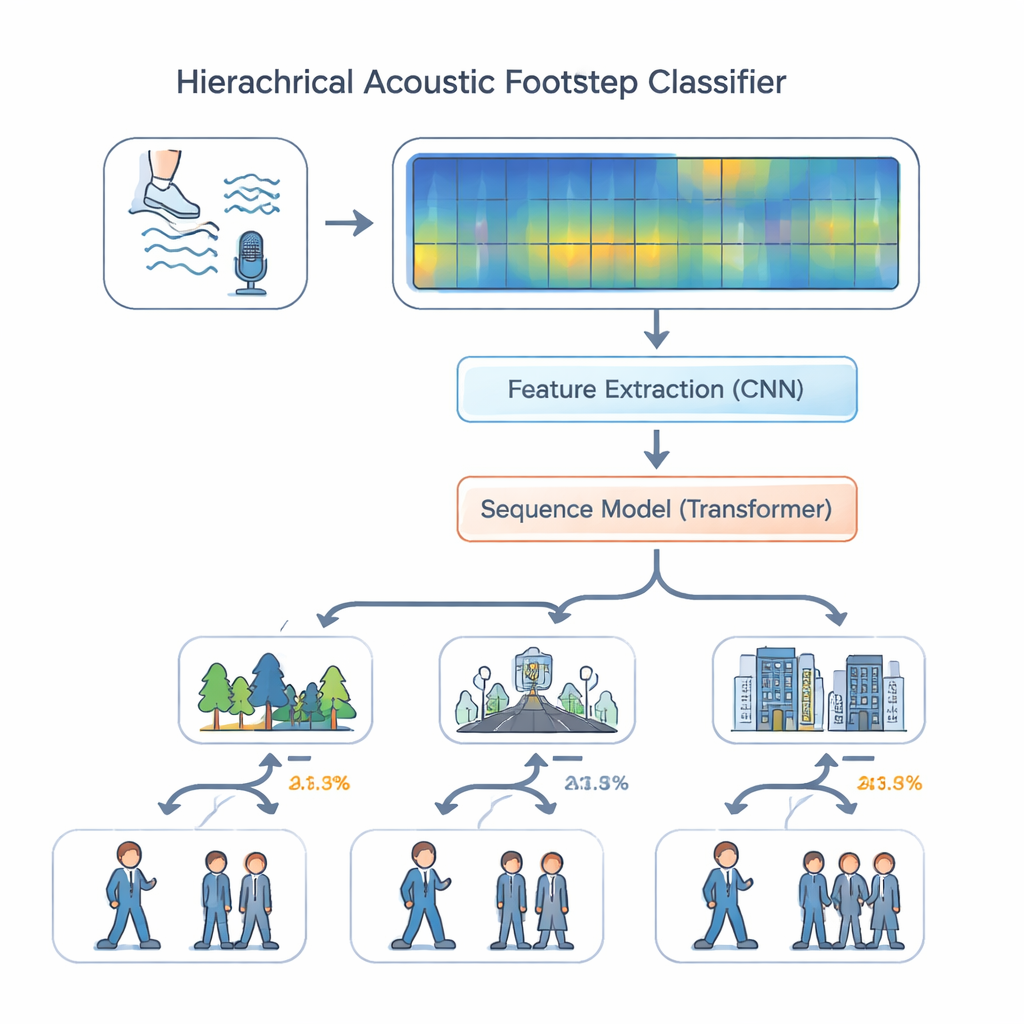
Con questo dataset a disposizione, gli autori hanno progettato un sistema di ascolto che imita il modo in cui un abile osservatore potrebbe ragionare sul suono. Invece di trattare tutti i compiti allo stesso modo, il loro modello “gerarchico multi-task” decide prima dove sta avvenendo il suono—foresta, strada o interno—e poi, usando quel contesto, stima se si tratta di una persona o di più individui. L'audio viene convertito in spettrogrammi colorati che mostrano come l'energia si distribuisce sulle frequenze nel tempo. Una serie di layer convoluzionali individua dettagli fini legati alle superfici e alle calzature, come il fruscio delle foglie o il colpo degli stivali sul cemento. Queste caratteristiche passano poi a un modulo transformer, un moderno motore per l'elaborazione di sequenze che esamina pattern su molti passi—ritmo, spaziatura e impatti ripetuti—invece di suoni isolati. L'encoding posizionale aiuta il modello a tenere traccia dell'ordine nel tempo, essenziale per riconoscere i pattern del camminare.
Quanto funziona la sentinella acustica?
I ricercatori hanno confrontato il loro modello gerarchico con approcci più semplici, come un singolo classificatore tutto‑in‑uno e un design multi‑task standard dove ambiente e numero di persone sono predetti in modo indipendente. Hanno anche testato varianti che rimuovevano componenti chiave come gli strati convoluzionali o il transformer. In tutti i casi, il progetto completo con entrambi i moduli e l'encoding posizionale ha fornito le migliori prestazioni. Sul dataset EWFootstep 1.0 ha identificato correttamente l'ambiente circa il 96 percento delle volte e il numero di persone con una precisione simile—nettamente superiore rispetto a ascoltatori umani addestrati, che risultano inferiori di 25‑30 punti percentuali. Esperimenti aggiuntivi su un dataset di suoni di tosse hanno mostrato che la stessa architettura si generalizza bene oltre i passi, suggerendo che può gestire tipi molto diversi di audio quotidiano.
Dal campo di battaglia alla scena del crimine
Per i non specialisti, la conclusione principale è che suoni deboli e quotidiani come i passi contengono molte più informazioni di quelle che normalmente percepiamo. Combinando grandi dataset realistici con strumenti avanzati di riconoscimento dei pattern, gli autori dimostrano che un sistema compatto può determinare in modo affidabile che tipo di luogo sta ascoltando e quante persone sono presenti, in tempo quasi reale e senza telecamere. Questa “sentinella acustica” potrebbe aiutare a proteggere pattuglie e strutture remote, e la sua capacità di analizzare pattern sonori sottili può anche agevolare la fonoteca forense, ad esempio ricostruendo movimenti su una scena del crimine quando il video non è disponibile o non è affidabile.
Citazione: Agrahri, A., Maurya, C.K., Tiwari, R.S. et al. Acoustic sentinel: hierarchical classification of footstep sound using fine and coarse-grain acoustic feature representations for tactical surveillance. Sci Rep 16, 5635 (2026). https://doi.org/10.1038/s41598-026-35756-3
Parole chiave: sorveglianza acustica, rilevamento dei passi, sistemi di allerta precoce, deep learning audio, sicurezza tattica