Clear Sky Science · it
Apprendimento automatico per la stima rapida dell’intensità macrosismica dai dati sismometrici in Italia
Perché le valutazioni rapide dei terremoti sono importanti
Quando il terreno comincia a tremare, le squadre di emergenza hanno solo pochi minuti per decidere dove inviare soccorritori e risorse. Tuttavia il modo abituale di descrivere quanto forte è avvertito un terremoto in superficie – l’intensità macrosismica, come la scala Mercalli usata in Italia – spesso arriva ore, giorni o persino mesi dopo, quando le persone compilano questionari e gli esperti ispezionano i danni. Questo articolo esplora come l’apprendimento automatico moderno possa trasformare le prime letture dei sismometri in mappe rapide e ragionevolmente accurate di quanto è stato avvertito un evento, aiutando le autorità a reagire più in fretta e con maggiore sicurezza.
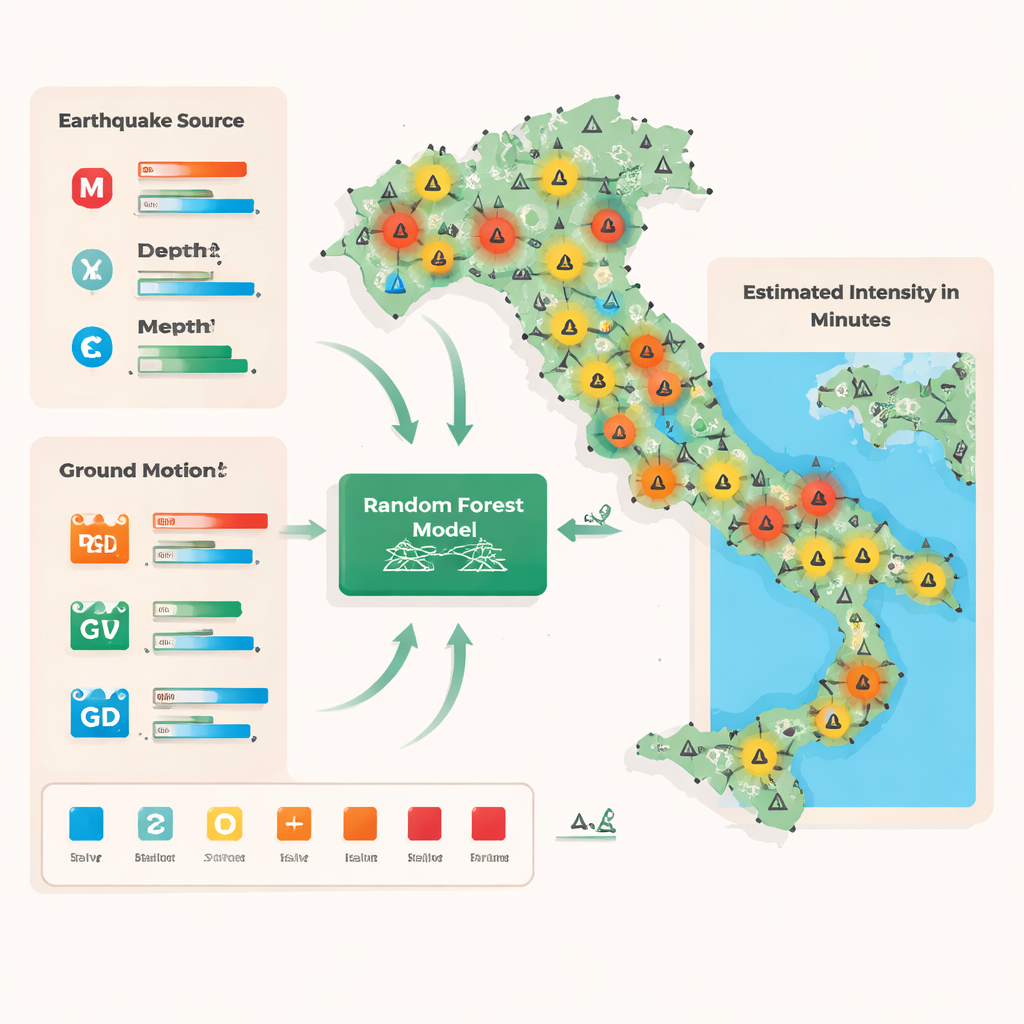
Dai resoconti di avvertimento alle stime rapide
Le stime tradizionali di intensità in Italia si basano su due principali flussi di dati. Il primo consiste in rilievi sul campo realizzati da esperti e registrati in un database ufficiale, che si concentrano sui luoghi danneggiati ma richiedono tempo per essere organizzati. L’altro proviene dal sistema online “Hai Sentito Il Terremoto”, dove i cittadini segnalano ciò che hanno sentito e visto, fornendo molte osservazioni di bassa e moderata intensità. Entrambe le fonti misurano l’intensità sulla scala Mercalli-Cancani-Sieberg, che classifica lo scuotimento dal molto debole al distruttivo in base alle risposte umane e agli effetti sugli edifici. Per collegare queste misure centrate sull’esperienza umana con le registrazioni strumentali, gli autori hanno unito i due insiemi di dati attorno a ciascuna stazione sismica, mediando tutte le intensità segnalate entro 5 km per ottenere un unico valore rappresentativo per quell’area e arrotondandolo a una classe intera da 1 a 8.
Addestrare una foresta di modelli a leggere lo scuotimento
I ricercatori hanno inquadrato la stima dell’intensità come un problema di classificazione: date le misurazioni iniziali, prevedere quale delle otto classi di intensità si applicherà all’intorno di ciascuna stazione. Hanno utilizzato una Random Forest, un insieme di molti alberi decisionali che ciascuno effettua una semplice serie di suddivisioni “se–allora” sui dati, come combinazioni di magnitudo, profondità, distanza dalla sorgente e misure dirette del moto del terreno come accelerazione, velocità e spostamento di picco. Addestrato su 5.466 osservazioni provenienti da 523 terremoti in tutta Italia (2008–2020), il modello ha appreso legami complessi e non lineari tra ciò che i sismometri registrano e ciò che le persone riportano. Per gestire il fatto che gli scuotimenti intensi sono più rari nei dati, gli autori hanno bilanciato l’addestramento in modo che tutti i livelli di intensità contassero allo stesso modo, evitando che il modello si concentri solo sugli eventi più comuni e più deboli.
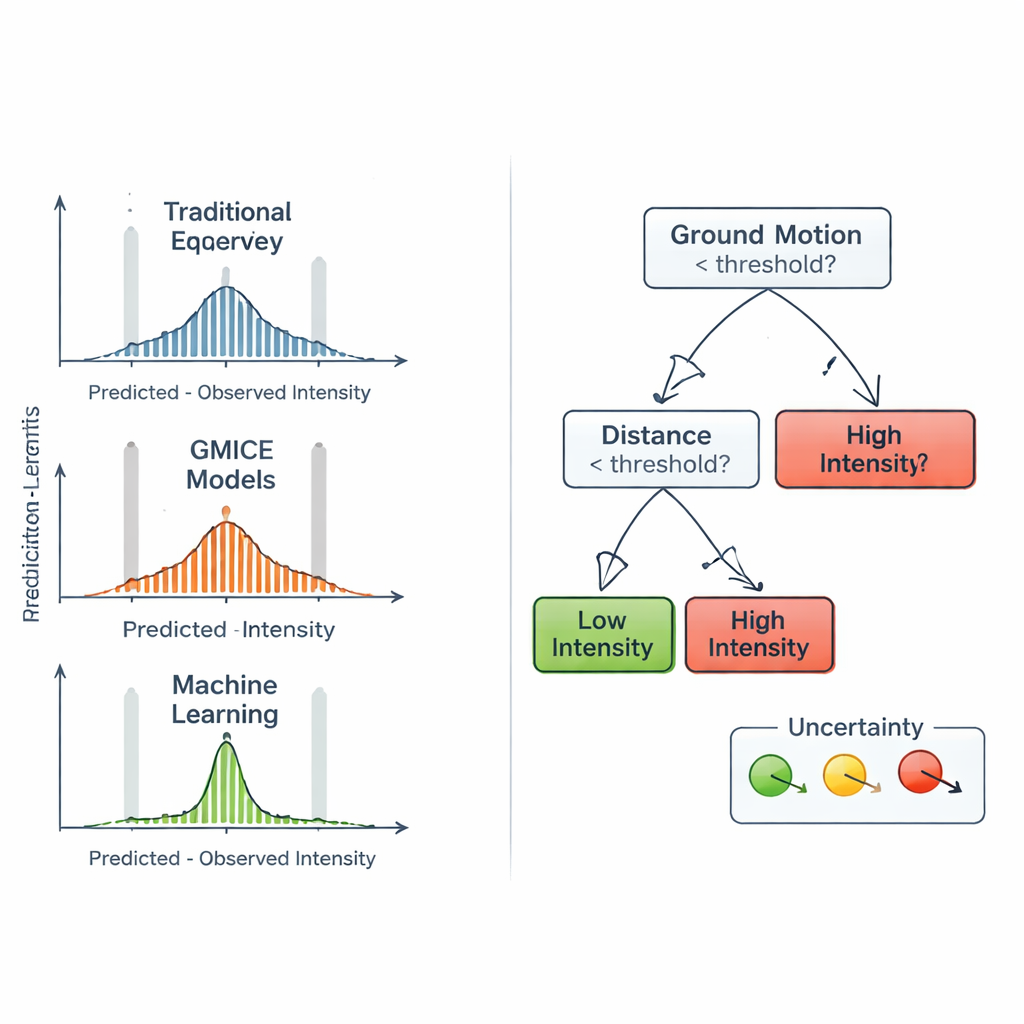
Confronto con regole consolidate
Per valutare se l’approccio di apprendimento automatico aggiunge realmente valore, il team ha confrontato le sue previsioni con due famiglie di relazioni empiriche ampiamente usate. La prima, chiamata Equazioni di Predizione dell’Intensità, stima l’intensità principalmente da magnitudo, profondità e distanza, assumendo che lo scuotimento diminuisca con la distanza in modo regolare. La seconda, Equazioni di Conversione moto del suolo–intensità, trasforma le misure strumentali del moto di picco in classi di intensità attese. Queste formule sono compatte e facili da applicare, ma non riescono a catturare appieno come la geologia locale, il patrimonio edilizio o la direzione delle onde influenzino lo scuotimento percepito. Per contro, la Random Forest integra naturalmente sia i parametri di sorgente sia le misure del moto del terreno, e può adattarsi a pattern sottili nel dataset italiano senza prespecifcare una forma matematica rigida.
Guardare dentro la scatola nera e i suoi limiti
Poiché i responsabili delle emergenze hanno bisogno di capire le basi delle decisioni automatizzate, gli autori hanno costruito alberi decisionali “surrogati” più semplici che imitano il comportamento della Random Forest. Questi alberi più piccoli possono essere rappresentati come diagrammi, mostrando quali soglie del moto del terreno separano intensità basse da alte e dove variabili come accelerazione e velocità predominano. Questa analisi ha rivelato che le misure dirette del moto del suolo, in particolare accelerazione e velocità di picco, pesano più della sola magnitudo o profondità. Gli autori hanno anche introdotto un modo semplice per segnalare quanto è incerta ciascuna previsione del surrogato, usando misure di quanto gli esempi di addestramento siano misti in ciascun ramo finale. Allo stesso tempo, hanno riscontrato che le intensità molto forti restano difficili da prevedere, in parte perché sono naturalmente rare nell’archivio storico, il che porta talvolta a sottostimare i livelli di scuotimento più elevati.
Test sul campo durante un recente terremoto italiano
Il team ha valutato il loro quadro su un evento reale significativo: un terremoto di magnitudo 5.5 al largo della costa adriatica vicino a Pesaro-Urbino nel 2022. In circa 15 minuti i sismologi avevano le informazioni necessarie su sorgente e moto del suolo, ma erano state presentate solo circa 90 segnalazioni pubbliche di intensità, offrendo un quadro molto frammentario. Usando solo i dati strumentali, la Random Forest e il suo albero surrogato hanno generato stime dettagliate di intensità attorno a centinaia di stazioni in meno di due secondi su un computer standard. Quando in seguito sono state confrontate con la mappa molto più densa costruita da oltre 12.000 segnalazioni di cittadini raccolte nel corso di alcuni giorni, le mappe generate dall’apprendimento automatico hanno colto bene sia l’area complessivamente avvertita sia la diffusione degli scuotimenti moderati, e hanno eguagliato o superato le equazioni classiche.
Che cosa significa per le persone che vivono con i terremoti
Nel complesso, lo studio mostra che un sistema di apprendimento automatico accuratamente addestrato può prendere i primi minuti di dati sismometrici e produrre mappe rapide e ragionevolmente trasparenti dell’impatto di un terremoto. Queste mappe non sostituiscono i rilievi dettagliati o i report di crowd-sourcing, ma possono colmare il pericoloso primo intervallo in cui le autorità devono scegliere dove inviare ambulanze, vigili del fuoco e ispettori strutturali con informazioni molto limitate. Combinando algoritmi avanzati con modelli semplificati interpretabili e indicatori di incertezza di base, il quadro offre un passo pratico verso risposte più rapide e più informate ai terremoti in Italia e potrebbe essere adattato ad altre regioni che affrontano rischi sismici simili.
Citazione: Patelli, L., Cameletti, M., De Rubeis, V. et al. Machine learning for prompt estimation of macroseismic intensity from seismometric data in Italy. Sci Rep 16, 7265 (2026). https://doi.org/10.1038/s41598-026-35740-x
Parole chiave: intensità del terremoto, apprendimento automatico, random forest, rischio sismico, Italia