Clear Sky Science · it
Rete di fusione per l'arricchimento multi-caratteristica per la segmentazione semantica di immagini da telerilevamento
Mappe più nitide dal cielo
Ogni giorno satelliti e droni catturano immagini dettagliate delle nostre città e campagne. Trasformare questi scatti grezzi in mappe chiare, pixel per pixel, di strade, tetti, alberi e colture è fondamentale per attività come il monitoraggio della salute delle colture o la pianificazione di nuovi quartieri. Questo articolo presenta un nuovo approccio per rendere quelle mappe più accurate, in particolare lungo i confini difficili dove edifici, campi e vegetazione si confondono.
Perché le immagini aeree sono difficili da leggere
Le immagini da telerilevamento appaiono diverse rispetto alle foto di tutti i giorni. Sono scattate dall'alto, spesso con angolazioni accentuate e sotto illuminazioni variabili. Diversi oggetti possono sembrare molto simili dall'alto: un parcheggio in cemento e un tetto piano possono condividere quasi lo stesso colore; differenti tipi di colture possono mostrare motivi sorprendentemente simili. Allo stesso tempo, lo stesso tipo di oggetto può apparire molto diverso a seconda delle ombre, dell'umidità o delle impostazioni della camera. I programmi tradizionali, e persino molti sistemi moderni di deep learning, fanno fatica a mantenere i contorni nitidi in queste condizioni. Spesso sfumano i margini tra le categorie o perdono piccoli dettagli come auto parcheggiate o canali di irrigazione stretti.
Vedere sia il quadro d'insieme che le linee sottili
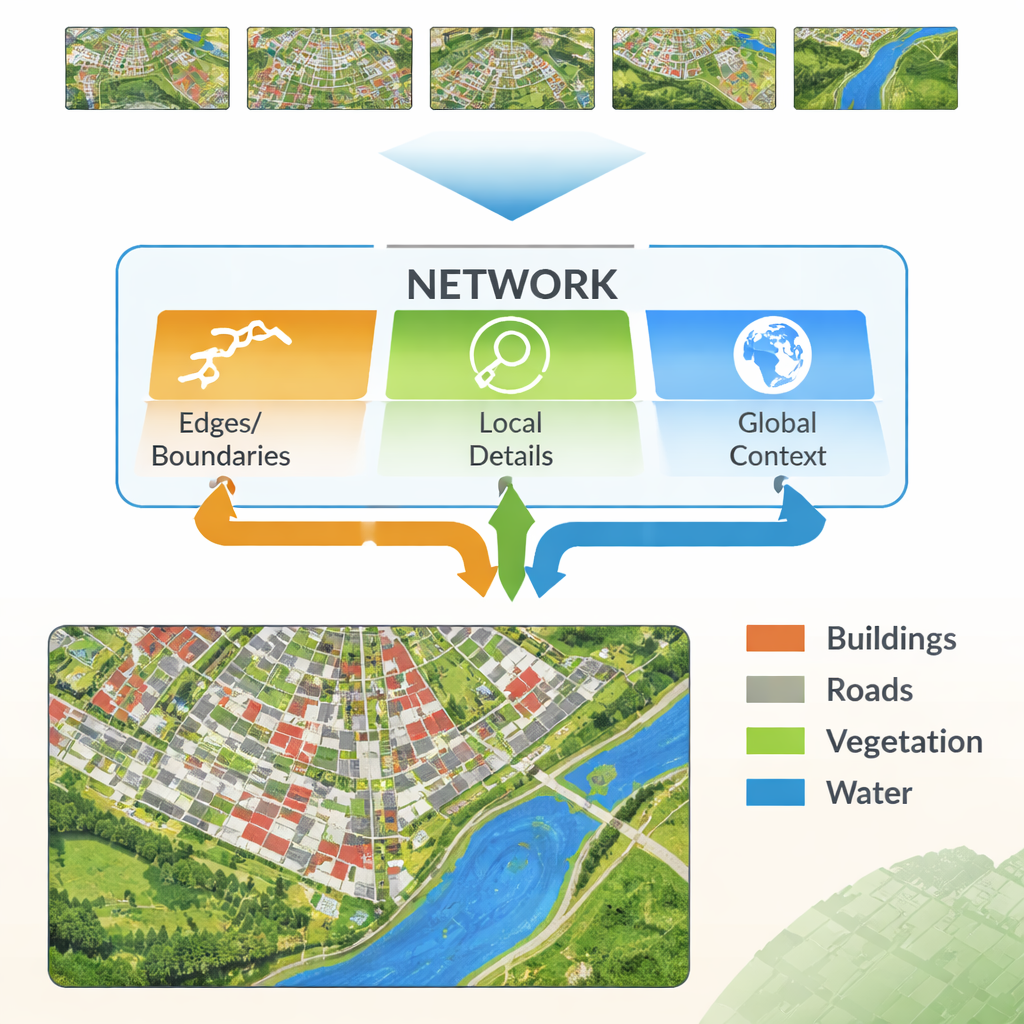
Le reti neurali moderne apprendono passando un'immagine attraverso molti strati. Gli strati iniziali rilevano dettagli fini come linee e trame, mentre gli strati più profondi apprendono schemi ampi come “questa regione è probabilmente edifici”. La sfida è che combinare questi due tipi di informazioni non è semplice. I dettagli a basso livello possono essere rumorosi e ridondanti, e i pattern ad alto livello possono attenuare i bordi, producendo contorni sfocati. Gli autori propongono una nuova architettura, chiamata Multi-Feature Enhancement Fusion Network (MFEF-UNet), progettata esplicitamente per bilanciare il dettaglio locale con la comprensione globale. Lo fa trattando bordi, pattern locali e contesto ampio come fonti separate ma cooperanti di informazione.
Evidenziare i bordi e fondere le caratteristiche
Un'idea chiave del nuovo metodo è recuperare semplici strumenti classici di rilevamento dei bordi e integrarli in una moderna pipeline di deep learning. Un Edge Enhancement Module prende le prime feature della rete e le elabora con operatori molto efficaci nel trovare i confini—similmente a come un software di fotoritocco di base può rilevare i contorni. Queste mappe dei bordi potenziate vengono prodotte a diverse scale, così la rete vede sia confini fini che grossolani. Un Multi-Feature Fusion Module riunisce poi tre flussi: l'informazione ad alto livello che evolve sul “che cosa è questa regione?”, la ricostruzione dei dettagli del decoder, e le mappe dei bordi. Invece di limitarvisi a sovrapporre, il modulo usa un meccanismo simile all'attenzione in modo che le feature semantiche possano “chiedere” ai flussi di bordo e dettaglio dove sono realmente i confini e le piccole strutture, e aggiustare la rappresentazione finale di conseguenza.
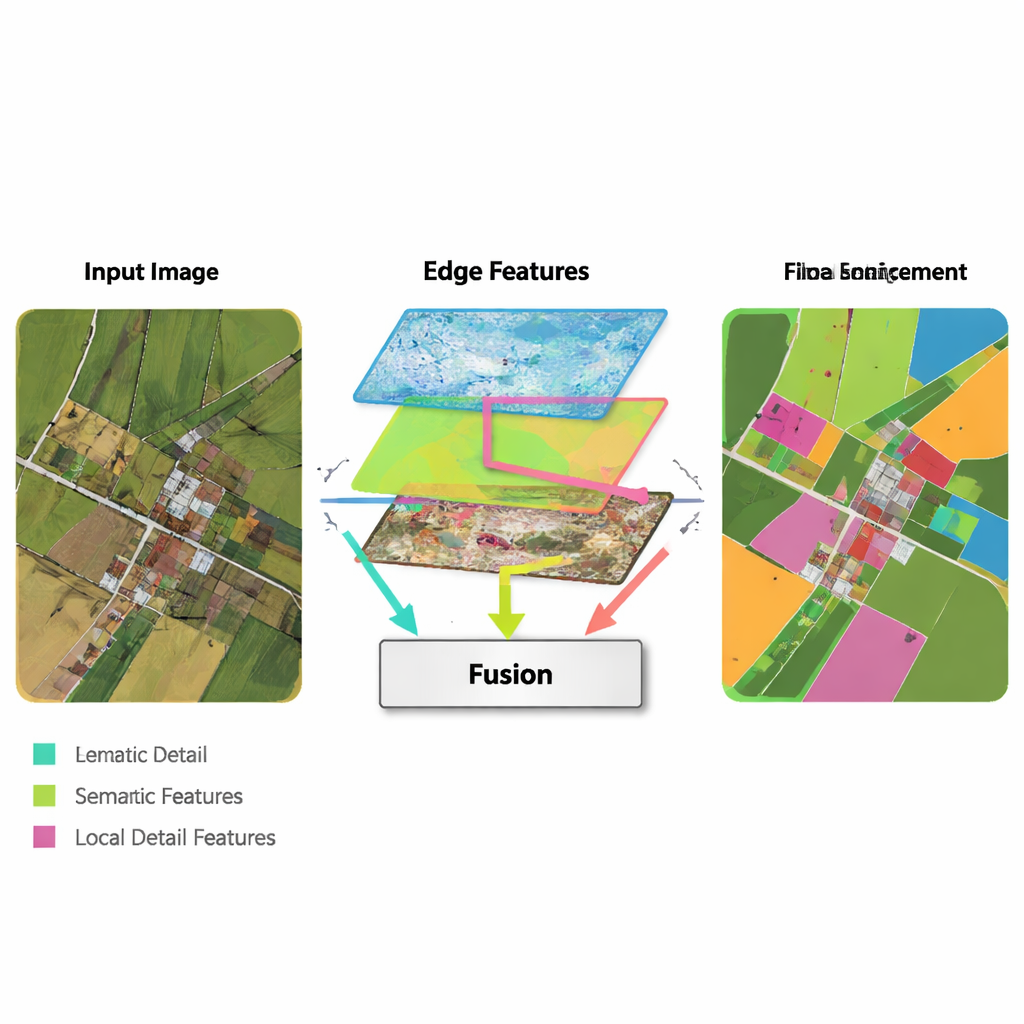
Bilanciare il dettaglio locale con il contesto globale
Un altro elemento di MFEF-UNet è il Local-Global Feature Enhancement Module. Per un non esperto, questo può essere visto come la parte della rete che assicura di non perdere di vista la foresta mentre si concentrano gli alberi—o la città mentre si rifinisce ogni edificio. L'immagine viene suddivisa in sotto-finestre gestibili in modo che i pixel vicini possano essere modellati insieme, preservando forme e trame. Dopo questa modellazione locale, le finestre vengono ricomposte in un'immagine completa e un secondo passaggio permette all'informazione di fluire attraverso regioni distanti. Questo processo in due fasi aiuta il modello a rispettare sia le strutture piccole, come automobili e confini stretti dei campi, sia i pattern su larga scala, come isolati di case o masse d'acqua continue.
Dimostrare il metodo su città e campagne
I ricercatori hanno testato il loro approccio su tre dataset pubblicamente disponibili: due che coprono cittadine e città europee, e una grande raccolta di immagini agricole dagli Stati Uniti. Questi dataset includono una miscela di tetti, strade, vegetazione, acqua e pattern colturali sottili. Su tutti e tre i benchmark, MFEF-UNet ha prodotto costantemente mappe più accurate rispetto a una serie di metodi di punta, incluse reti convoluzionali classiche, architetture basate su Transformer e modelli più recenti di tipo “state-space”. I suoi vantaggi sono risultati più visibili attorno a contorni edilizi complessi, ammassi di piccoli oggetti come veicoli e strutture lunghe e sottili come canali di drenaggio o filari di colture—luoghi in cui altri metodi tendono a frammentare o sfumare la segmentazione.
Cosa significa in pratica
In termini pratici, la rete proposta trasforma le immagini aeree in mappe di copertura del suolo più pulite e affidabili. I pianificatori urbani possono misurare con maggiore sicurezza le aree edificabili, gli ingegneri possono tracciare meglio strade e tetti e gli agronomi possono delimitare con più precisione campi, corsi d'acqua e zone di stress colturale. Sebbene i componenti aggiuntivi per i bordi e la fusione introducano un certo costo computazionale in più, il design complessivo rimane ragionevolmente efficiente pur offrendo evidenti miglioramenti in accuratezza e robustezza. Per i non specialisti, la conclusione è che enfatizzando deliberatamente i bordi e fondendo con cura diversi tipi di segnali visivi, i computer possono ora leggere le immagini satellitari e da drone con occhio più acuto—avvicinandoci a mappe del mondo aggiornate e ad alta precisione.
Citazione: Zhang, W., Yang, W., Yin, Y. et al. Multi-feature enhancement fusion network for remote sensing image semantic segmentation. Sci Rep 16, 5023 (2026). https://doi.org/10.1038/s41598-026-35723-y
Parole chiave: telerilevamento, segmentazione semantica, immagini satellitari, apprendimento profondo, mappatura della copertura del suolo