Clear Sky Science · it
Dai dati alle decisioni: l'uso dell'IA interpretabile per prevedere la resa della soia nei principali paesi produttori
Perché previsioni colturali più intelligenti sono importanti
Dai prezzi al supermercato al commercio globale, la modesta soia svolge un ruolo sorprendentemente rilevante nella vita quotidiana. Governi, operatori commerciali e agricoltori devono sapere quanto sarà grande il raccolto mesi prima che le mietitrebbie entrino nei campi. Oggi potenti strumenti di intelligenza artificiale (IA) possono setacciare montagne di dati meteorologici e satellitari per formulare queste previsioni, ma molti di tali modelli si comportano come “scatole nere”, offrendo poche indicazioni sul perché forniscano una determinata risposta. Questo studio esplora una nuova classe di IA interpretabile che non solo prevede le rese di soia nei principali paesi produttori mondiali, ma mostra anche in modo chiaro quali fattori guidano tali previsioni.
Tre paesi che nutrono il mondo
I ricercatori si sono concentrati sui tre paesi che dominano l'offerta globale di soia: Stati Uniti, Brasile e Argentina, che insieme producono più dell'80% della soia mondiale. Hanno analizzato i dati a una scala fine — contee negli Stati Uniti ed aree equivalenti di piccola estensione in Brasile e Argentina — utilizzando dati recenti dal 2018 al 2022. Per ciascuna regione hanno ricostruito un quadro ricco delle condizioni di crescita: registri meteorologici dettagliati, proprietà del suolo e diversi tipi di dati satellitari che monitorano la crescita delle piante, lo stato idrico e persino un debole bagliore legato alla fotosintesi noto come fluorescenza clorofilliana indotta dal sole (SIF). In totale sono state estratte 154 caratteristiche numeriche diverse per descrivere ogni stagione di crescita prima di essere immesse nei modelli.
Dai flussi di dati alle macchine che apprendono
Per gestire questo flusso di informazioni, il team ha costruito una pipeline di elaborazione standardizzata. Hanno allineato tutti i dataset nello spazio e nel tempo usando calendari colturali, levigato i segnali satellitari rumorosi e sintetizzato la stagione di crescita con statistiche come medie, estremi e variabilità. Hanno poi addestrato tre tipi di modelli per prevedere le rese: Random Forest (RF), un cavallo di battaglia del machine learning; Multilayer Perceptron (MLP), una classica rete neurale profonda; e Kolmogorov–Arnold Networks (KAN), un'architettura più recente progettata fin dall'inizio per essere più interpretabile. Per evitare autovalutazioni ottimistiche, gli autori hanno suddiviso attentamente i dati in blocchi spaziali in modo che i modelli fossero testati su regioni che non avevano “visto” durante l'addestramento.
Aprire la scatola nera dell'IA
Ciò che distingue questo lavoro non è solo l'accuratezza delle previsioni, ma il modo in cui i modelli si spiegano. RF e MLP sono stati analizzati con strumenti standard che mostrano quanto ciascuna caratteristica di input influisca sulle loro previsioni. KAN va oltre: rappresenta i legami tra input e output come curve unidimensionali e lisce che possono essere tracciate e ispezionate. Questo permette ai ricercatori di vedere concretamente come, per esempio, una variazione di SIF o dell'umidità del suolo sposti la resa verso l'alto o verso il basso. Tra paesi e metodi, un pattern è risultato chiaro — la SIF, il segnale satellitare legato direttamente alla fotosintesi, si è costantemente posizionata tra i predittori più importanti della resa della soia. Altri fattori chiave variavano per regione: negli Stati Uniti hanno prevalso segnali vegetazionali legati all'acqua, mentre in Brasile e Argentina temperatura e umidità del suolo hanno giocato ruoli più rilevanti.
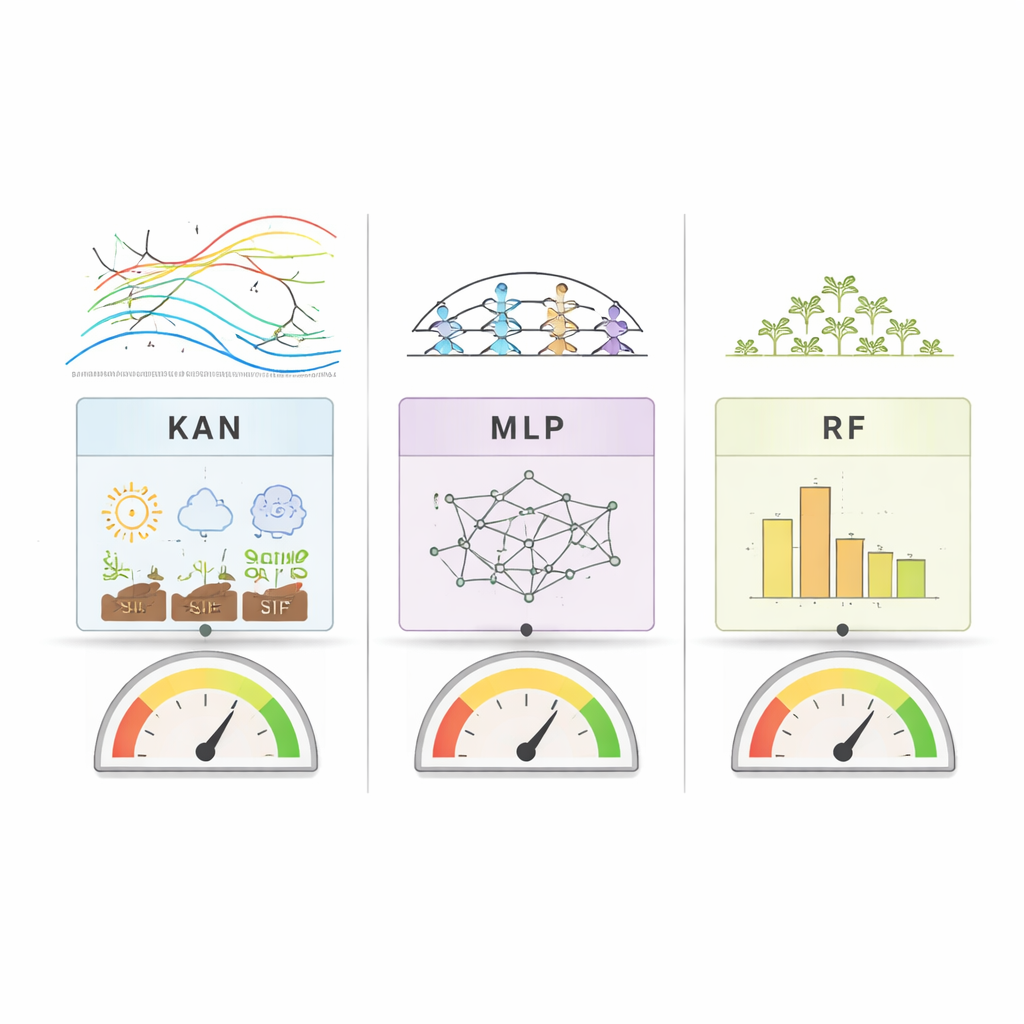
Quanto bene hanno funzionato i modelli?
Quando i ricercatori hanno confrontato l'accuratezza dei modelli, nessun metodo ha dominato in modo assoluto in tutte le situazioni. Negli Stati Uniti, dove le rese erano relativamente stabili di anno in anno, Random Forest ha performato leggermente meglio nel complesso, ma KAN e MLP lo seguivano da vicino. In Brasile, con rese più volatili e un dataset più ampio, tutti e tre i modelli hanno raggiunto alta accuratezza, pur mostrando qualche difficoltà nel prevedere rese molto elevate. In Argentina, dove i dati erano più limitati, KAN ha generalmente superato la baseline di deep learning (MLP) e si è avvicinato a Random Forest. Questi risultati suggeriscono che KAN può eguagliare i modelli tradizionali su dataset agricoli difficili e di piccole dimensioni offrendo al contempo una trasparenza molto maggiore sul modo in cui arriva alle sue conclusioni.
Cosa significa per agricoltori e sicurezza alimentare
Per i decisori operativi, poter fidarsi di un modello può essere importante quanto la sola accuratezza. Questo studio mostra che approcci di IA interpretabile come KAN possono fornire previsioni competitive della resa della soia rivelando in modo chiaro quali segnali ambientali e colturali contano di più. Questa visibilità aiuta gli scienziati a diagnosticare errori, integrare conoscenze agronomiche di esperti e adattare i modelli a nuove regioni o a climi in cambiamento. Sul lungo periodo, strumenti trasparenti di questo tipo potrebbero essere integrati nei sistemi nazionali di monitoraggio delle colture, offrendo ad agricoltori, pianificatori e mercati avvisi più precoci e affidabili su cattivi raccolti o produttività eccedente — supportando sistemi alimentari più resilienti e sostenibili.
Citazione: Wang, X., He, Y., Chen, H. et al. From data to decisions: the use of explainable AI to forecast soybean yield in major producing countries. Sci Rep 16, 5103 (2026). https://doi.org/10.1038/s41598-026-35716-x
Parole chiave: previsione resa della soia, IA interpretabile, telerilevamento, modellazione agricola, sicurezza alimentare