Clear Sky Science · it
Tracker siamese a doppio ramo potenziato da transformer con regressione consapevole della confidenza e aggiornamento adattivo del template
Insegnare ai computer a seguire un solo oggetto in una scena affollata
Dalle auto a guida autonoma alle telecamere di sicurezza domestiche e ai droni, molti dispositivi moderni devono seguire un singolo oggetto in movimento in un mondo affollato e in continua evoluzione. Questo compito, chiamato tracciamento visivo di oggetti, sembra semplice per gli esseri umani ma è sorprendentemente difficile per le macchine: persone passano davanti alla camera, cambia l'illuminazione, l'oggetto si allontana o viene temporaneamente nascosto. Questo articolo presenta TSDTrack, un nuovo sistema di tracciamento che sfrutta i recenti progressi del deep learning e dei transformer per rimanere bloccato sull'obiettivo in modo più affidabile in condizioni reali.
Perché seguire una sola cosa è così difficile
Un tracker di solito vede l'oggetto chiaramente solo nel primo fotogramma di un video, poi deve continuare a individuarlo mentre la scena cambia. I metodi tradizionali si affidavano a caratteristiche visive progettate a mano o a una rete neurale che confrontava il primo fotogramma (il "template") con ogni nuovo fotogramma. Questi sistemi più vecchi avevano tre grandi debolezze. Primo, di solito mantenevano il template originale fisso, quindi se l'oggetto ruotava, veniva parzialmente coperto o cambiava dimensione, il tracker faticava. Secondo, spesso si concentravano su un solo livello di dettaglio dell'immagine, perdendo la combinazione di bordi fini e contesto generale che aiuta gli umani a riconoscere gli oggetti. Terzo, non avevano modo di dubitare delle proprie stime: producevano una scatola attorno al presunto oggetto senza un chiaro senso di quanto fosse affidabile quella previsione, il che li rendeva inclini a deviare sullo sfondo.
Fondere il contesto globale con i dettagli fini
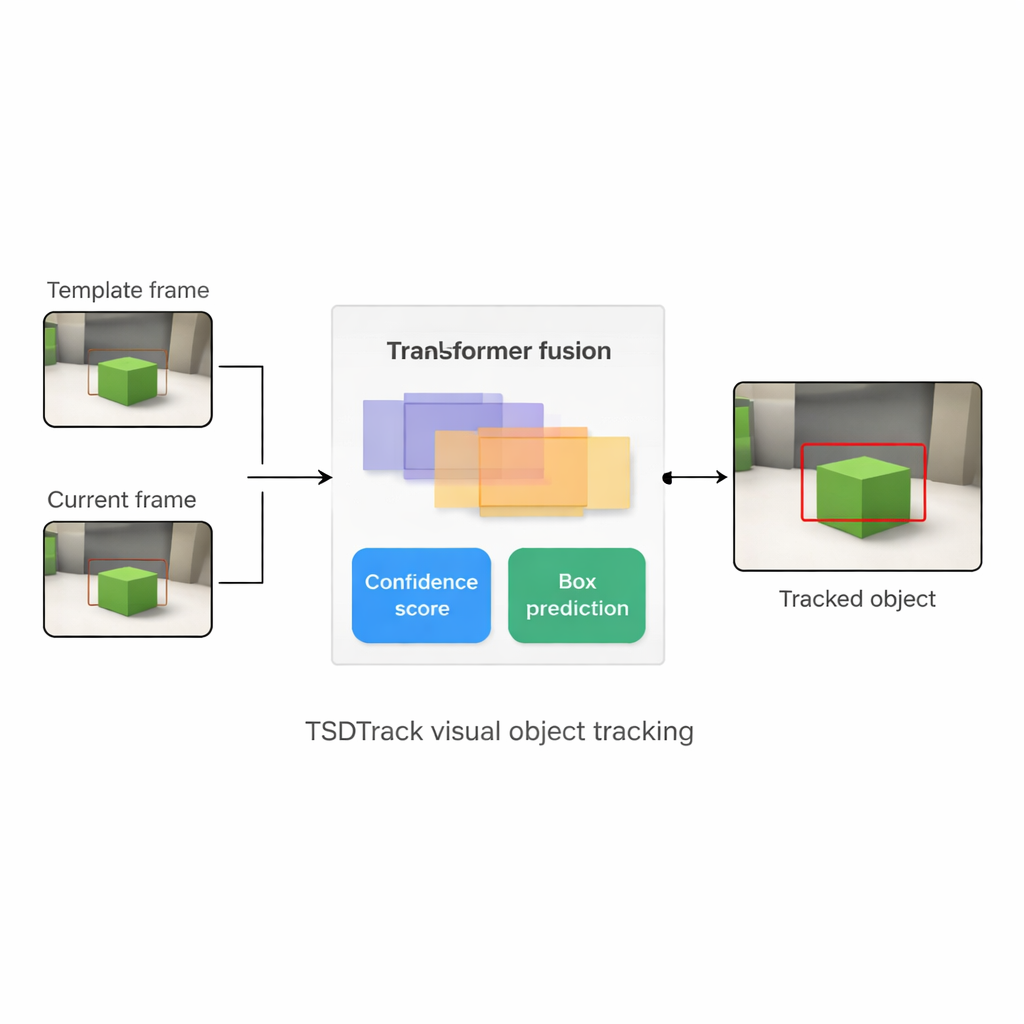
TSDTrack affronta questi problemi combinando un classico schema di tracciamento "Siamese" con un transformer, lo stesso tipo di modello basato sull'attenzione che ha trasformato compiti di linguaggio e visione. Il sistema usa una rete profonda per estrarre caratteristiche da due input: una piccola porzione che definisce il target e una porzione più ampia che contiene l'area di ricerca corrente. Invece di affidarsi a un solo livello di feature, attinge informazioni da più layer della rete, che rappresentano bordi, forme e pattern a livello di oggetto. Un modulo di fusione basato su transformer impara quindi come mescolare questi livelli in modo che il tracker comprenda sia dove si trovano le cose nell'immagine sia come si relazionano al contesto più ampio. Questo lo aiuta a distinguere il target da oggetti simili e dal disordine, anche quando la vista è rumorosa o parzialmente ostruita.
Capire quanto il tracker è davvero sicuro
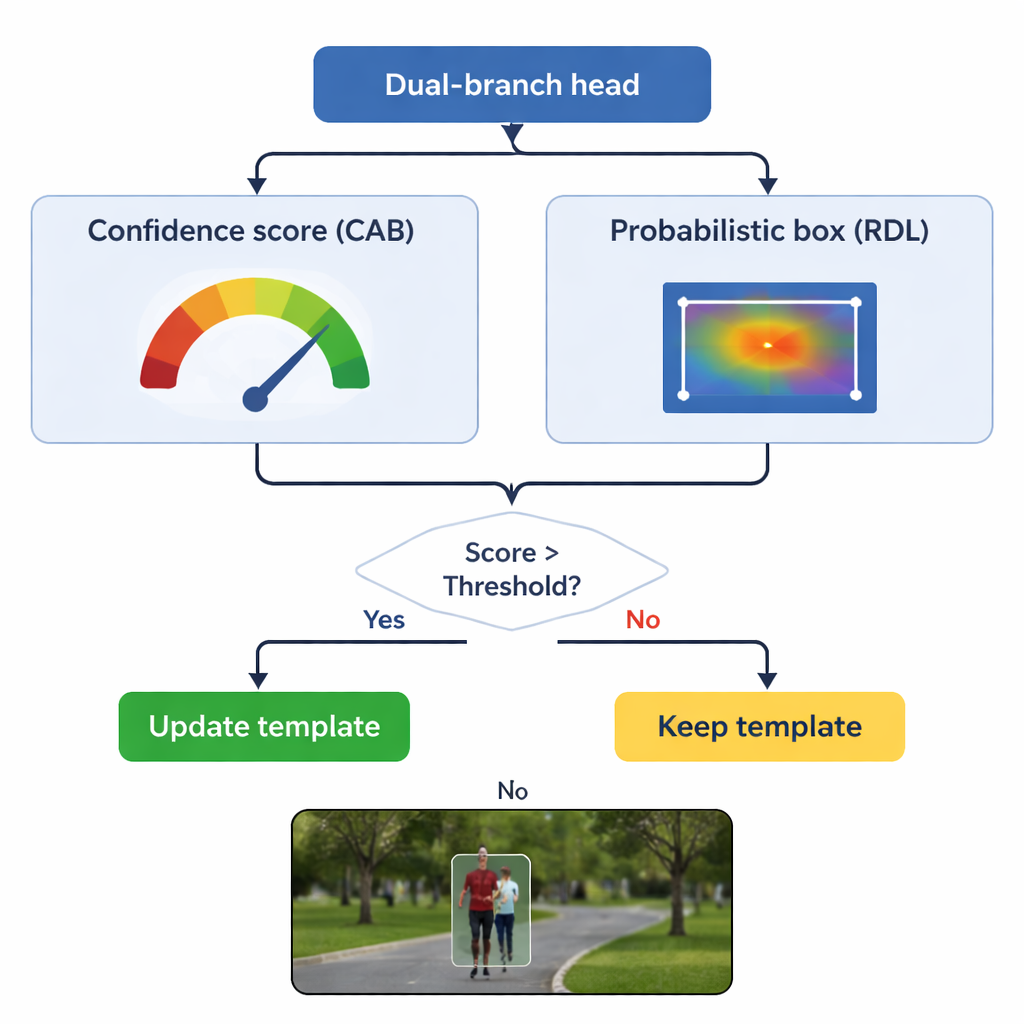
Il nucleo di TSDTrack è una testa di predizione a doppio ramo che divide il compito in due domande correlate: "Dove si trova l'oggetto?" e "Quanto dobbiamo fidarci di questa risposta?" Un ramo stima un punteggio di confidenza che riflette non solo quanto il target appare simile, ma anche quanto bene la scatola predetta si sovrappone a regioni probabili dell'oggetto. L'altro ramo tratta le coordinate della scatola non come un'unica ipotesi, ma come una distribuzione di probabilità su molte posizioni possibili, permettendo al modello di rappresentare l'incertezza. Quando l'immagine è chiara, la distribuzione diventa stretta e la scatola è precisa; quando l'oggetto è sfocato o parzialmente nascosto, la distribuzione si allarga. Questa visione probabilistica porta a un posizionamento della scatola più fluido e stabile rispetto ai tracker più vecchi che facevano una singola previsione rigida.
Aggiornare la memoria senza dimenticare l'originale
Un pericolo chiave nel tracciamento è il "template drift": se il modello continua ad aggiornare la sua idea dell'oggetto usando fotogrammi scadenti, può lentamente apprendere lo sfondo. TSDTrack affronta questo lasciando che il ramo di confidenza faccia da guardiano. Il sistema aggiorna il proprio template interno solo quando il punteggio di confidenza supera una soglia scelta e, anche in quel caso, fonde le nuove informazioni delicatamente con la vista originale invece di sostituirla completamente. Questo aggiornamento selettivo permette al tracker di adattarsi a cambiamenti genuini, come una persona che si gira o un'auto che ruota, senza essere ingannato da occlusioni momentanee o distrazioni. Il template originale viene inoltre mantenuto come riferimento stabile nel caso in cui aggiornamenti successivi si rivelino fuorvianti.
Cosa significano i risultati nella pratica
Gli autori hanno testato TSDTrack su diversi benchmark di tracciamento ampiamente usati, inclusi video lunghi, movimenti veloci, riprese aeree da droni e scene con forte disordine. In questi test, il nuovo metodo ha costantemente superato molti tracker di punta sia in accuratezza (quanto la scatola è vicina al vero oggetto) sia in robustezza (quanto raramente perde completamente l'oggetto), mantenendo comunque una velocità sufficiente per l'uso in tempo reale su hardware moderno. Per un non specialista, la conclusione è che TSDTrack può mantenere l'attenzione su un bersaglio scelto in modo più affidabile nelle condizioni disordinate delle telecamere reali. Combinando ragionamento transformer multi-scala, una stima della propria confidenza e un aggiornamento attento del template, offre un mattoncino più fidato per applicazioni come la guida autonoma, la videosorveglianza intelligente e i robot intelligenti.
Citazione: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
Parole chiave: tracciamento di oggetti visivi, tracciamento basato su transformer, reti Siamese, visione artificiale, sistemi autonomi