Clear Sky Science · it
Un approccio di apprendimento automatico basato su satellite per stimare la temperatura media giornaliera dell’aria ad alta risoluzione in una megacittà del Brasile
Perché il calore in città non è lo stesso ovunque
In una giornata calda in una grande città, la temperatura percepita su una strada alberata può essere molto diversa da quella che si prova in una piazza di cemento a pochi isolati di distanza. Eppure la maggior parte degli studi sulla salute e sul clima continua a trattare un’intera città come se avesse un’unica temperatura. Questo articolo mostra come gli scienziati abbiano usato satelliti, modelli meteorologici e apprendimento automatico per mappare le temperature giornaliere in tutta São Paulo, Brasile, con grande dettaglio—aiutando a rivelare chi è realmente esposto al calore pericoloso e dove gli sforzi di raffrescamento sono più necessari.
Prendere la temperatura della città in alta definizione
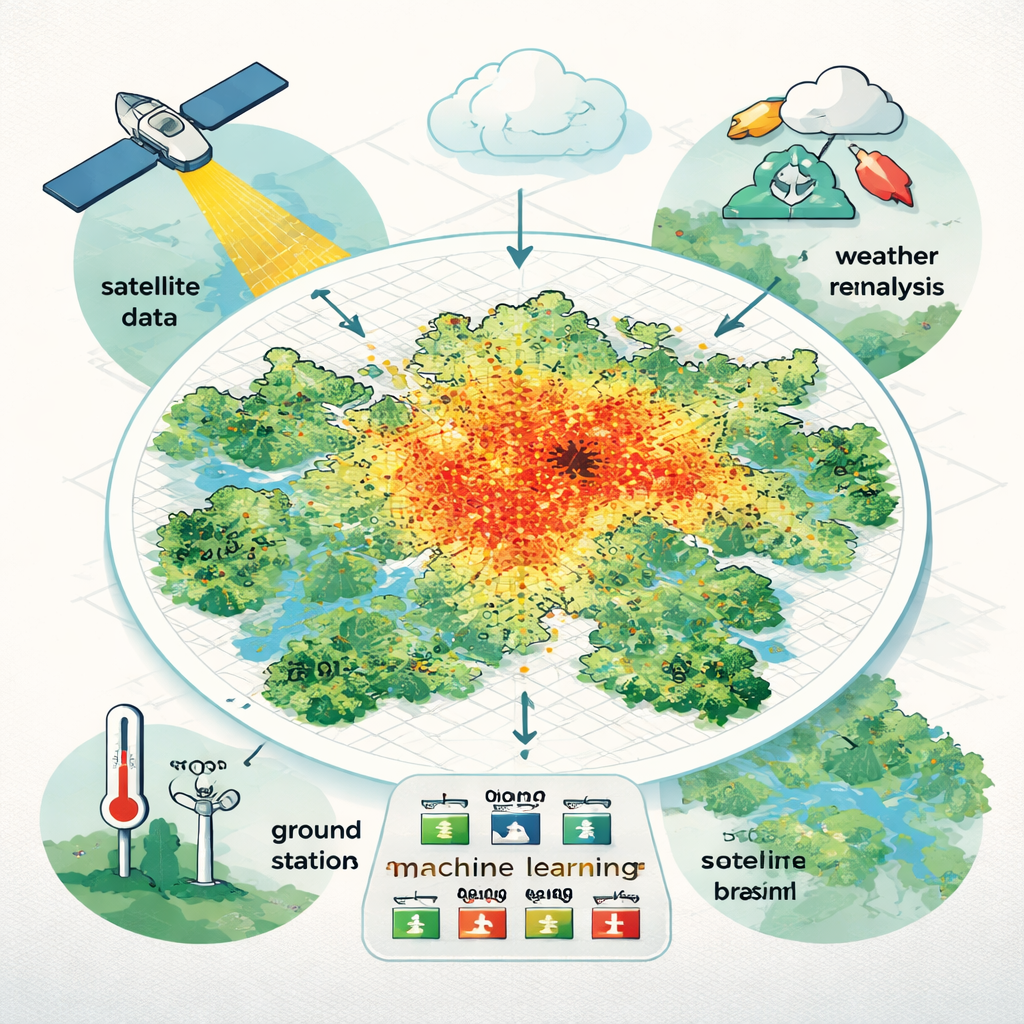
I registri di temperatura tradizionali si basano su un numero limitato di stazioni meteorologiche, spesso raggruppate vicino agli aeroporti o nei quartieri più ricchi. Questo rende difficile vedere come il calore sia distribuito nei quartieri reali, specialmente nelle grandi città e nei paesi a basso e medio reddito, dove le reti di monitoraggio sono scarse. I ricercatori si sono concentrati su São Paulo, una vasta e altamente variabile megacittà di oltre 22 milioni di persone. Hanno mirato a stimare la temperatura media giornaliera dell’aria per ogni quadrato di 500 per 500 metri in tutta l’area metropolitana per cinque anni, dal 2015 al 2019, creando uno dei dataset di temperatura urbana più dettagliati finora disponibili in Sud America.
Mescolare satelliti, modelli meteorologici e sensori a terra
Per costruire questa immagine ad alta risoluzione, il team ha combinato diversi tipi di dati liberamente disponibili. Hanno raccolto misure da 48 stazioni a terra, che forniscono le letture più dirette della temperatura dell’aria ma solo in punti specifici. Poi hanno integrato osservazioni satellitari della temperatura della superficie terrestre, dell’angolo del sole e della riflettanza del suolo, insieme a informazioni su umidità, vento e pressione provenienti da un prodotto di “reanalisi” meteorologica globale che ricostruisce il tempo orario su una griglia grossolana. Questi ingredienti sono stati rimappati per corrispondere alla griglia da 500 metri e ripuliti per colmare i vuoti dovuti a nuvole o a passaggi satellitari mancanti. In totale, hanno testato 23 possibili variabili predittive che potrebbero aiutare a spiegare come il calore varia nello spazio e nel tempo.
Addestrare una macchina che legga il calore
Invece di usare una semplice equazione lineare, gli scienziati si sono rivolti a una Random Forest, un popolare metodo di apprendimento automatico che costruisce molti alberi decisionali e ne media i risultati. Questo approccio è particolarmente adatto a individuare relazioni complesse e non lineari, come il modo in cui la temperatura risponde in maniera diversa al calore superficiale, all’umidità e al vento in diverse parti della città o in diversi periodi dell’anno. Per evitare l’overfitting dovuto alle particolarità di poche stazioni, hanno usato un processo passo dopo passo di selezione delle caratteristiche che mantiene solo le variabili che migliorano realmente le previsioni, e hanno validato il modello in due modi: escludendo ripetutamente gruppi di stazioni durante l’addestramento e trattenendo cinque stazioni intere come test esterno rigoroso per valutare come il modello si comporta in nuove località.
Cosa rivelano le mappe dettagliate
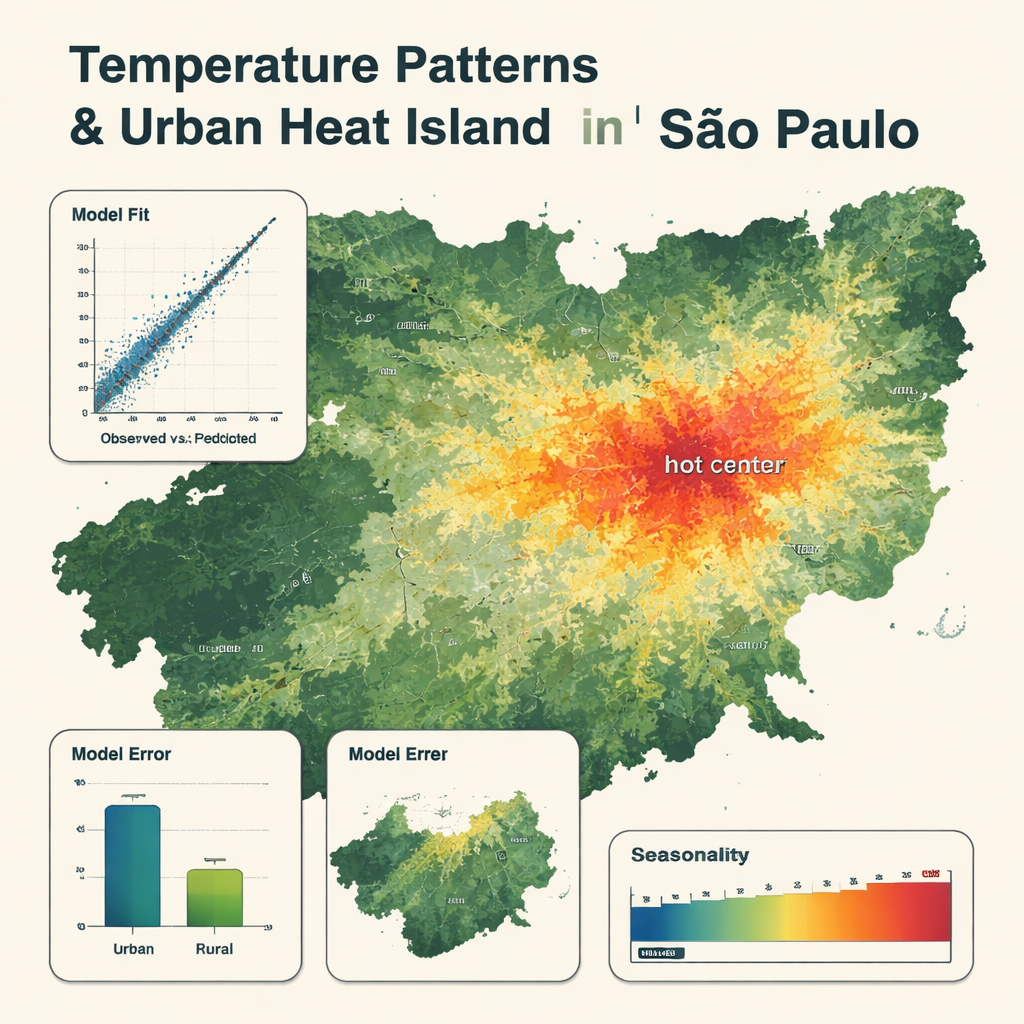
Il modello finale ha usato solo otto variabili chiave, guidato dalla temperatura dell’aria del prodotto meteorologico globale, con la temperatura della superficie satellitare e l’umidità che hanno svolto ruoli importanti. Ha riprodotto da vicino le letture delle stazioni, con un errore medio di circa 0,8 °C e una corrispondenza molto elevata tra temperature osservate e previste. Le mappe mostrano schemi chiari: zone più fresche su foreste, montagne e grandi bacini, e zone più calde nel centro cittadino densamente edificato, dove le temperature possono essere fino a 5 °C più alte rispetto alle aree rurali vicine. Il modello ha catturato le oscillazioni stagionali, con le condizioni più calde da dicembre a marzo e le più fredde da maggio ad agosto. È stato leggermente meno preciso in aree rurali e tendeva ad attenuare i giorni più estremi di caldo e freddo, ma ha comunque superato un modello di regressione multilineare più tradizionale utilizzando gli stessi input.
Perché queste mappe contano per la salute delle persone
Trasformando misure sparpagliate e istantanee satellitari in stime giornaliere della temperatura a livello stradale, questo lavoro offre uno strumento potente per la sanità pubblica e la pianificazione urbana a São Paulo e oltre. I ricercatori possono ora studiare come il calore colpisce diversi quartieri, incluse le insediamenti informali spesso assenti nei registri ufficiali, e identificare dove i residenti sono più a rischio durante le ondate di calore. Poiché il metodo si basa interamente su dati aperti e software standard, può essere adattato ad altre città che dispongono di alcune stazioni a terra e di una copertura satellitare simile. In termini semplici, lo studio dimostra che ora possiamo “vedere” il calore urbano con molto più dettaglio, fornendo una base essenziale per un adattamento climatico più equo, mirato e per la protezione delle comunità vulnerabili.
Citazione: Roca-Barceló, A., Schneider, R., Pirani, M. et al. A satellite based machine learning approach for estimating high resolution daily average air temperature in a megacity in Brazil. Sci Rep 16, 7459 (2026). https://doi.org/10.1038/s41598-026-35689-x
Parole chiave: calore urbano, apprendimento automatico, dati satellitari, São Paulo, temperatura dell’aria