Clear Sky Science · it
Identificazione in tempo reale degli attacchi di phishing tramite estensioni del browser potenziate con machine learning
Perché i siti falsi sono un problema di tutti
Ogni giorno le persone ricevono messaggi che sembrano provenire dalla loro banca, da un servizio di consegna o dal datore di lavoro—ma alcuni sono trappole costruite ad arte. Le truffe di phishing usano email e siti che imitano l’aspetto di quelli reali per rubare password, numeri di carta di credito e altri dati personali. Man mano che i criminali diventano più abili a riprodurre siti autentici, le semplici liste di blocco e l’intuito non bastano più. Questo articolo descrive una nuova estensione del browser che osserva silenziosamente le pagine visitate e usa il machine learning per segnalare in tempo reale i siti pericolosi, con l’obiettivo di offrire agli utenti comuni una protezione solida senza costringerli a diventare esperti di sicurezza.
Come gli attacchi di phishing moderni ci ingannano
Il phishing è diventato uno dei crimini online più diffusi a livello mondiale, responsabile di una larga parte degli incidenti informatici e delle perdite finanziarie segnalate. Gli aggressori inviano email persuasive che sollecitano un’azione rapida—“verifica il tuo account”, “aggiorna il pagamento”, “traccia il tuo pacco”—e indirizzano le vittime su siti falsi che somigliano molto a pagine bancarie, di shopping o di servizi cloud reali. Molti di questi siti ora usano certificati HTTPS validi e design curati, quindi avvisi vecchio stile come “nessun lucchetto” o “pagina brutta” non funzionano più. Indagini e rapporti sulla criminalità mostrano che gli adulti tra i 20 e i 40 anni sono tra i principali bersagli, e i team di sicurezza rimangono molto preoccupati per le truffe via email che sfuggono ai filtri.
Uno sguardo più intelligente agli indirizzi web e all’aspetto delle pagine
I ricercatori sostengono che il punto più sicuro per fermare il phishing sia proprio all’interno del browser, nel momento in cui una pagina viene caricata. La loro estensione per Google Chrome (e browser compatibili) esamina due indizi principali: l’indirizzo web stesso e l’aspetto della pagina. Da ogni sito raccoglie dettagli “lessicali” dall’URL, come lunghezza, simboli insoliti o sottodomini sospetti; dettagli “strutturali” e del dominio, come traffico e dati di registrazione; e segnali “visivi” come blocchi di layout, colori e loghi. Un browser headless rende ogni pagina in modo controllato, la suddivide in regioni rettangolari e registra dove compaiono form, loghi e barre di navigazione. Poi confronta questa impronta visiva con quelle di siti affidabili, cercando copie quasi identiche che potrebbero essere frodi.
Usare ‘lupi’ digitali per scegliere gli indizi più significativi
Poiché il sistema raccoglie decine di misure da ogni sito, deve decidere quali siano davvero utili a separare le truffe dalle pagine sicure. Per farlo, gli autori utilizzano un algoritmo ispirato al comportamento di caccia dei lupi grigi. In questo “Grey Wolf Optimizer” competono molti insiemi candidati di feature, e l’algoritmo converge gradualmente su un sottoinsieme compatto che offre il miglior equilibrio tra intercettare siti di phishing ed evitare falsi positivi. Queste feature selezionate vengono poi fornite a tre modelli di machine learning—Support Vector Machine, Decision Tree e soprattutto Random Forest, che combina molti alberi decisionali in un ensemble robusto. L’addestramento utilizza 80.000 siti prelevati da collezioni pubbliche come PhishTank e archivi accademici, con tecniche aggiuntive per gestire lo squilibrio tra siti legittimi e dannosi.
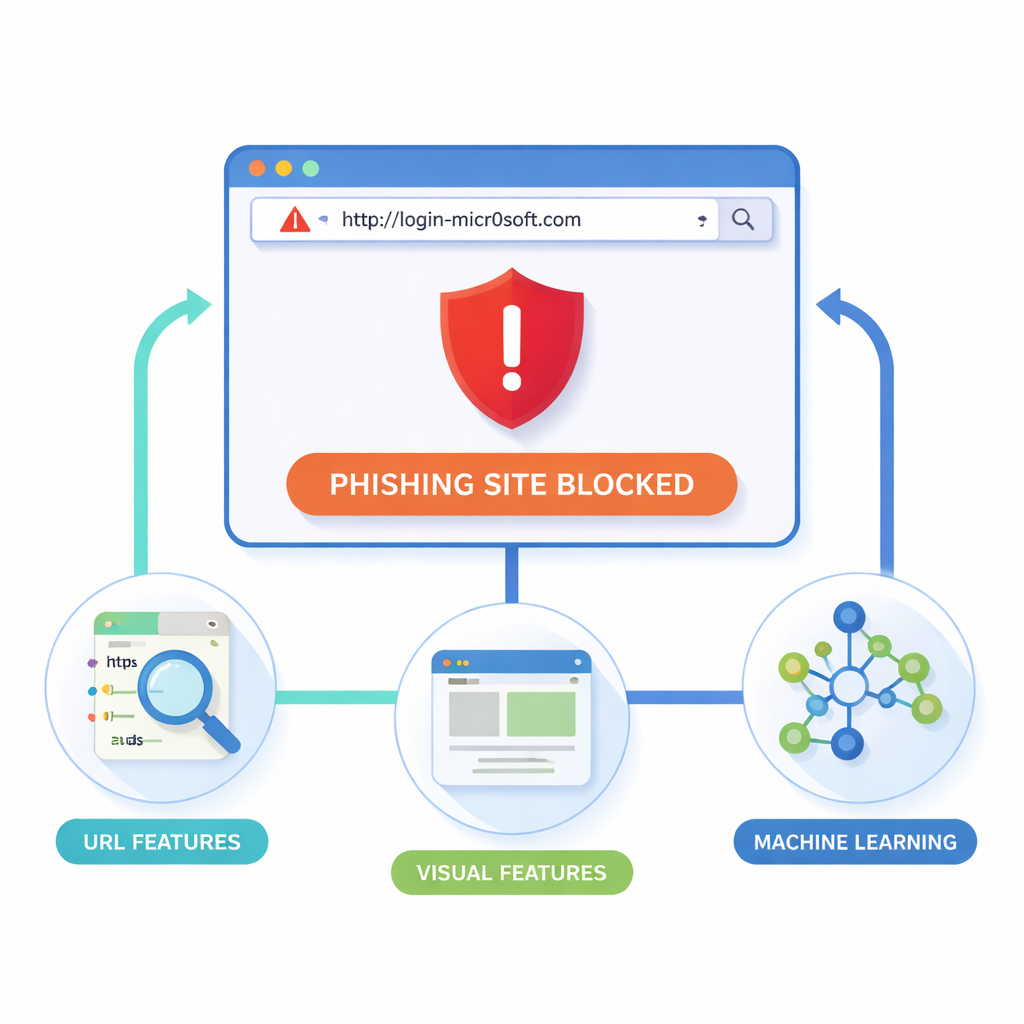
Trasformare i modelli di laboratorio in uno strumento utile per il browser
Il modello Random Forest ottimizzato ha raggiunto circa il 98–99% di accuratezza e un Matthews Correlation Coefficient vicino a 0,96, una misura rigorosa che considera sia gli attacchi mancati sia i falsi allarmi. Nei test live con un’estensione per Chrome, il sistema ha scansionato ogni URL in circa 200 millisecondi, abbastanza veloce da non causare ritardi percepibili agli utenti. Quando viene rilevata una pagina a rischio, l’add‑on mostra un avviso chiaro e permette all’utente di tornare indietro o procedere a proprio rischio. Rispetto a strumenti popolari come Google Safe Browsing e alle estensioni anti‑phishing esistenti, il nuovo sistema ha mostrato tassi di rilevamento più elevati, meno avvisi errati e la capacità di individuare indirizzi ingannevoli—anche quando erano accorciati, leggermente offuscati o appena creati.
Cosa significa questo per la navigazione di tutti i giorni
Per i non specialisti, il punto chiave è che la difesa dal phishing non deve più basarsi solo sull’intuito o su blacklist manuali. Combinando come è scritto un link con l’aspetto di una pagina e selezionando automaticamente i segnali più informativi, l’estensione proposta può riconoscere molte truffe al primo apparire, non solo dopo che qualcuno le segnala. Gli autori riconoscono che gli aggressori continueranno ad evolversi e che i modelli devono essere riaddestrati e estesi a telefoni e altri browser. Tuttavia, il loro lavoro dimostra che un add‑on intelligente, rispettoso della privacy e in esecuzione sul proprio dispositivo può fungere da instancabile secondo paio d’occhi—controllando discretamente ogni sito visitato e intervenendo quando qualcosa non torna, molto prima che un clic frettoloso si trasformi in un errore costoso.
Citazione: Dandotiya, M., Goyal, N., Khunteta, A. et al. Real time identification of phishing attacks through machine learning enhanced browser extensions. Sci Rep 16, 6612 (2026). https://doi.org/10.1038/s41598-026-35655-7
Parole chiave: rilevamento phishing, estensione del browser, machine learning, cybersicurezza, siti web falsi