Clear Sky Science · it
Generazione di immagini d'arte a colori guidata visivamente con AI usando GAN migliorati
Perché le macchine artistiche più intelligenti contano
Gli strumenti digitali possono ora dipingere ritratti, paesaggi e scene astratte in pochi secondi, eppure molte di queste opere prodotte dall’IA appaiono ancora leggermente sbagliate: i colori possono confliggere, le texture risultano piatte o lo “stile” non corrisponde a quanto le persone immaginano. Questo articolo presenta un nuovo modo di insegnare ai computer a creare opere a colori più ricche, coerenti e vicine alla pittura reale, consentendo allo stesso tempo agli utenti di orientare il risultato con semplici suggerimenti visivi come schizzi e scelte cromatiche. L’obiettivo è rendere l’IA un partner creativo più affidabile per artisti, designer e utenti comuni che desiderano arte personalizzata senza dover seguire anni di formazione.
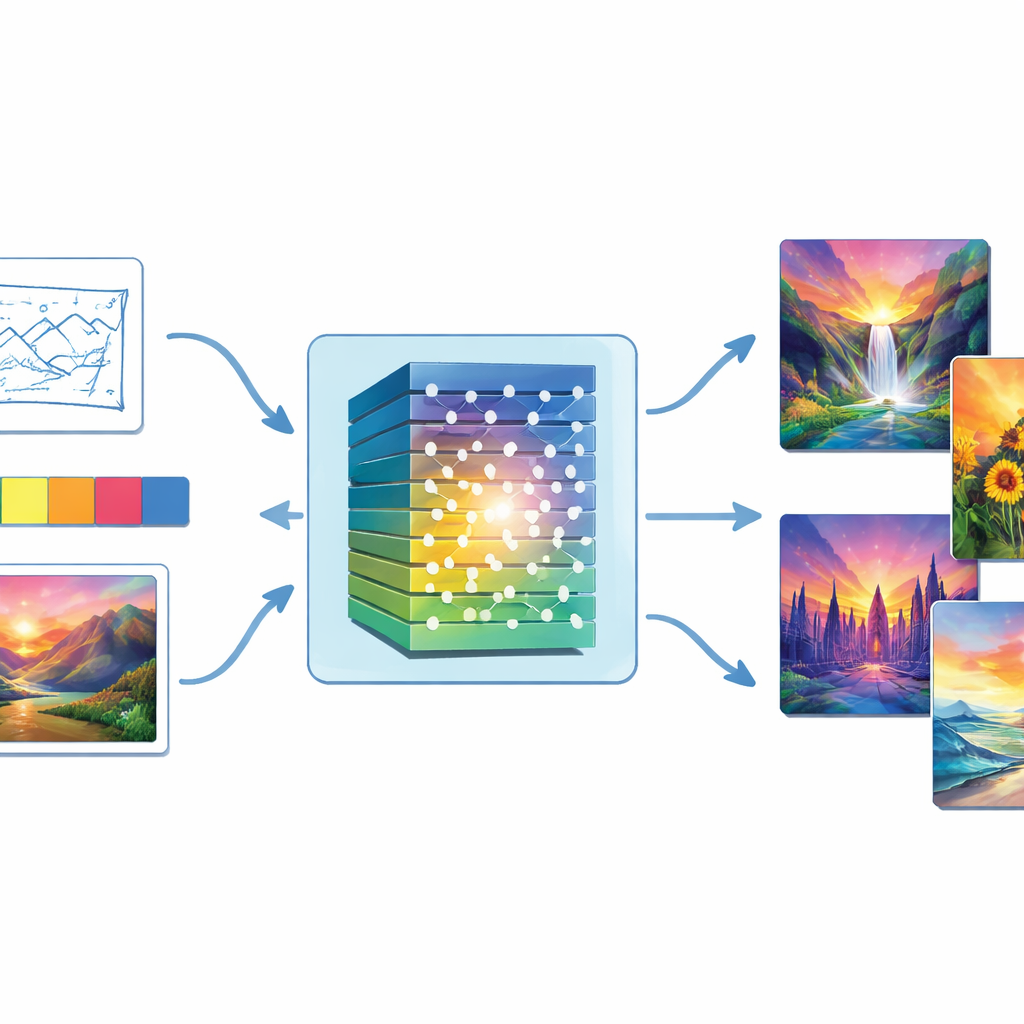
Dal rumore casuale ai dipinti finiti
Al centro dello studio c’è un tipo di IA chiamata Rete Antagonista Generativa, o GAN. Una GAN è composta da due parti opposte: un “generatore” che cerca di produrre immagini convincenti a partire da rumore casuale, e un “discriminatore” che giudica se un’immagine sembra reale o falsa. Attraverso molteplici cicli di addestramento reciproco, il generatore diventa più abile a ingannare il discriminatore e le immagini diventano gradualmente più realistiche. Gli autori rafforzano questa idea di base inserendo una profonda catena di elaborazione delle immagini — chiamata rete neurale convoluzionale — sia nel generatore sia nel discriminatore, così che il sistema possa catturare meglio tutto, dalle forme ampie ai dettagli fini simili a pennellate.
Insegnare al sistema dove guardare
Sebbene le GAN standard possano produrre immagini nitide, spesso perdono la visione d’insieme: possono sovra-enfatizzare piccoli dettagli e perdere la struttura globale, o non mantenere uno stile artistico coerente. Per affrontare questo problema, il team aggiunge un meccanismo di attenzione adattiva. Questo modulo analizza le mappe di caratteristiche interne del generatore e apprende, durante l’addestramento, quali regioni dell’immagine sono più importanti in ogni istante. Rafforza quindi quelle aree chiave — come bordi, texture e oggetti focali — attenuando le zone di sfondo meno rilevanti. Misure di perdita speciali monitorano quanto l’immagine generata corrisponda allo stile e alla tessitura di un’opera di riferimento, spingendo il modello a bilanciare contenuto riconoscibile e aspetto artistico coerente.
Guidare la macchina con indizi visivi
A differenza dei sistemi basati solo su testo, questo approccio permette alle persone di orientare l’opera con indicazioni visive dirette. Gli utenti possono fornire uno schizzo per definire la composizione, una tavolozza di colori per impostare l’atmosfera, un’immagine di stile da imitare o semplici tag di scena. Questi input entrano nel generatore insieme al rumore casuale. Il modello calcola quindi proprietà cromatiche come tinta, saturazione e luminosità, e adatta il proprio output in modo che il dipinto finale rispetti sia le intenzioni cromatiche dell’utente sia lo stile di riferimento. Un obiettivo di corrispondenza del colore rafforza ulteriormente il legame tra ciò che l’utente indica e ciò che il sistema produce, così che un paesaggio marino freddo non si trasformi inaspettatamente in un tramonto caldo, per esempio.
Imparare a migliorare per tentativi
Il sistema compie un passo ulteriore usando l’apprendimento per rinforzo profondo, una tecnica ispirata all’apprendimento per tentativi ed errori. Qui, un modulo decisionale separato considera la differenza tra l’output corrente e la guida target come il suo “stato”, e propone piccoli aggiustamenti a elementi come l’intensità dello schizzo o i pesi della tavolozza come sue “azioni”. Dopo ogni modifica, il sistema misura quanto migliorano i punteggi di qualità dell’immagine — come rapporto segnale-rumore di picco, somiglianza strutturale e perdita di stile — e usa questo come segnale di ricompensa. Nel tempo, questo ciclo apprende una politica che ottimizza automaticamente la guida per indirizzare il generatore verso immagini sia fedeli alla visione che coerenti dal punto di vista artistico.
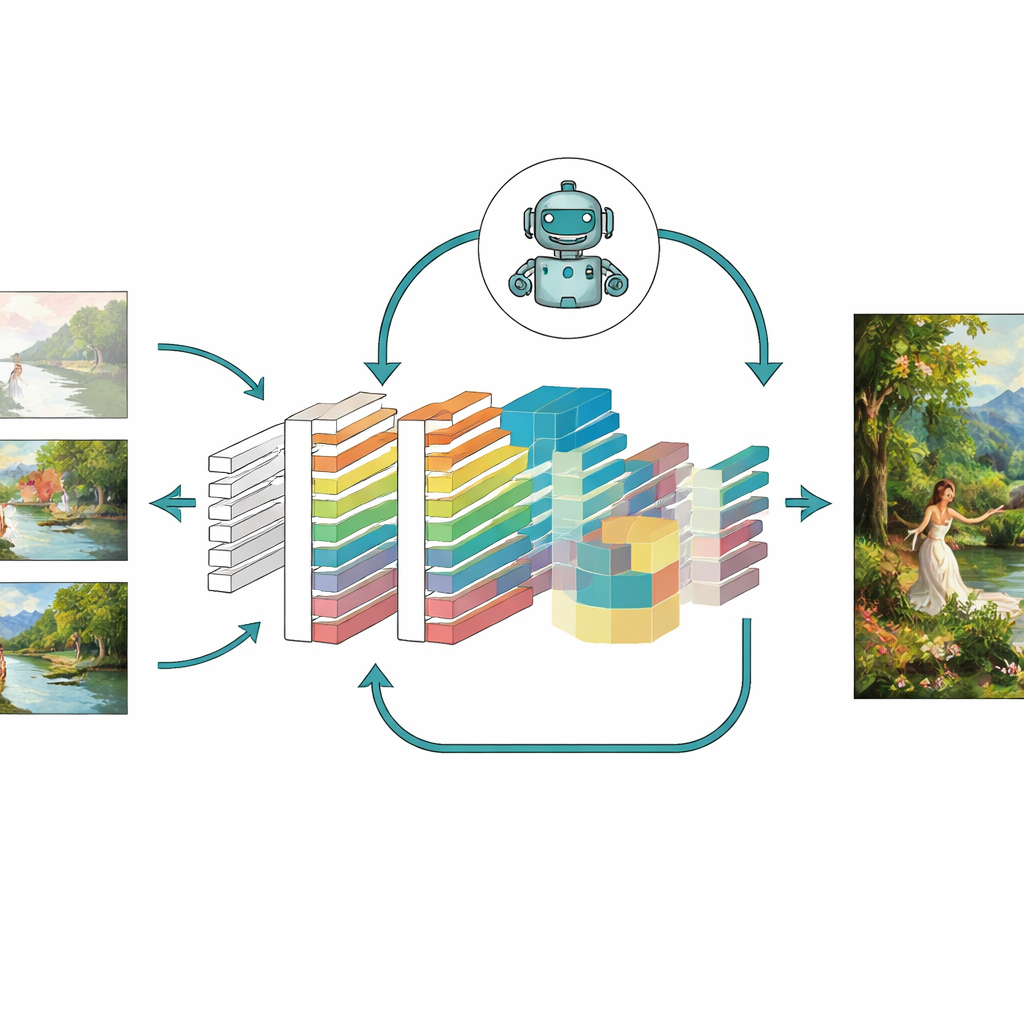
Mettere il modello alla prova
Per valutare se queste idee siano realmente efficaci, gli autori hanno testato il loro modello migliorato — chiamato CNN-GAN — su una vasta collezione di dipinti dell’Università di Oxford e su un insieme personalizzato di oltre 5.000 opere a colori in stili come ritratti, paesaggi e scene astratte. Hanno confrontato i risultati con diversi sistemi noti, incluse varianti classiche di GAN, autoencoder e persino generatori moderni basati su diffusione. Su molte misure, il nuovo modello ha prodotto immagini più nitide con meno artefatti, una corrispondenza strutturale più vicina alle opere reali, una distanza percettiva minore dalle immagini di riferimento e una maggiore varietà nei tipi di scene generate. Gli studi di ablazione, che rimuovevano un modulo alla volta, hanno mostrato che attenzione, apprendimento per rinforzo e la progettazione della funzione di perdita combinata hanno ciascuno contribuito a miglioramenti significativi e che insieme offrivano la performance più robusta.
Cosa significa questo per gli strumenti creativi futuri
In termini pratici, l’articolo descrive una macchina da dipinto che non solo apprende da migliaia di opere, ma presta anche attenzione speciale alle regioni importanti, ascolta gli indizi visivi degli utenti e si insegna gradualmente come regolare questi suggerimenti per ottenere risultati migliori. Il risultato è un’IA capace di generare immagini di alta qualità, stilisticamente unificate, in modo più affidabile rispetto ai metodi precedenti, pur lasciando spazio all’intervento umano. Sebbene il sistema fatichi ancora con texture estremamente intricate e dipenda da grandi quantità di dati di addestramento, gli autori suggeriscono possibili estensioni — come moduli multi-scala e reti più leggere — per renderlo più efficiente e di uso più diffuso. Complessivamente, questi progressi indicano strumenti di arte con IA più veloci, più fedeli alle intenzioni dell’utente e migliori nel cogliere il carattere sottile dei dipinti fatti dall’uomo.
Citazione: Wu, Z. Visual guided AI color art image generation using enhanced GAN. Sci Rep 16, 9345 (2026). https://doi.org/10.1038/s41598-026-35625-z
Parole chiave: generazione di arte con IA, trasferimento di stile delle immagini, reti antagoniste generative, creatività artificiale, sintesi neurale delle immagini