Ogni volta che governi, scienziati o sondaggisti cercano di ricavare informazioni su un’intera popolazione — come il reddito medio, la resa delle colture o i livelli di inquinamento — raramente possono misurare tutti gli individui. In genere si estrae un campione e si scala il risultato. Questo funziona bene solo se i dati si comportano in modo regolare. Nella realtà, però, sondaggi e misurazioni sono spesso pieni di errori e valori estremi che possono distorcere gravemente i risultati. Questo articolo presenta un nuovo modo di calcolare le medie di popolazione che rimane affidabile anche quando i dati sono disordinati, rendendo le decisioni basate sui sondaggi più attendibili.
Quando le medie semplici falliscono
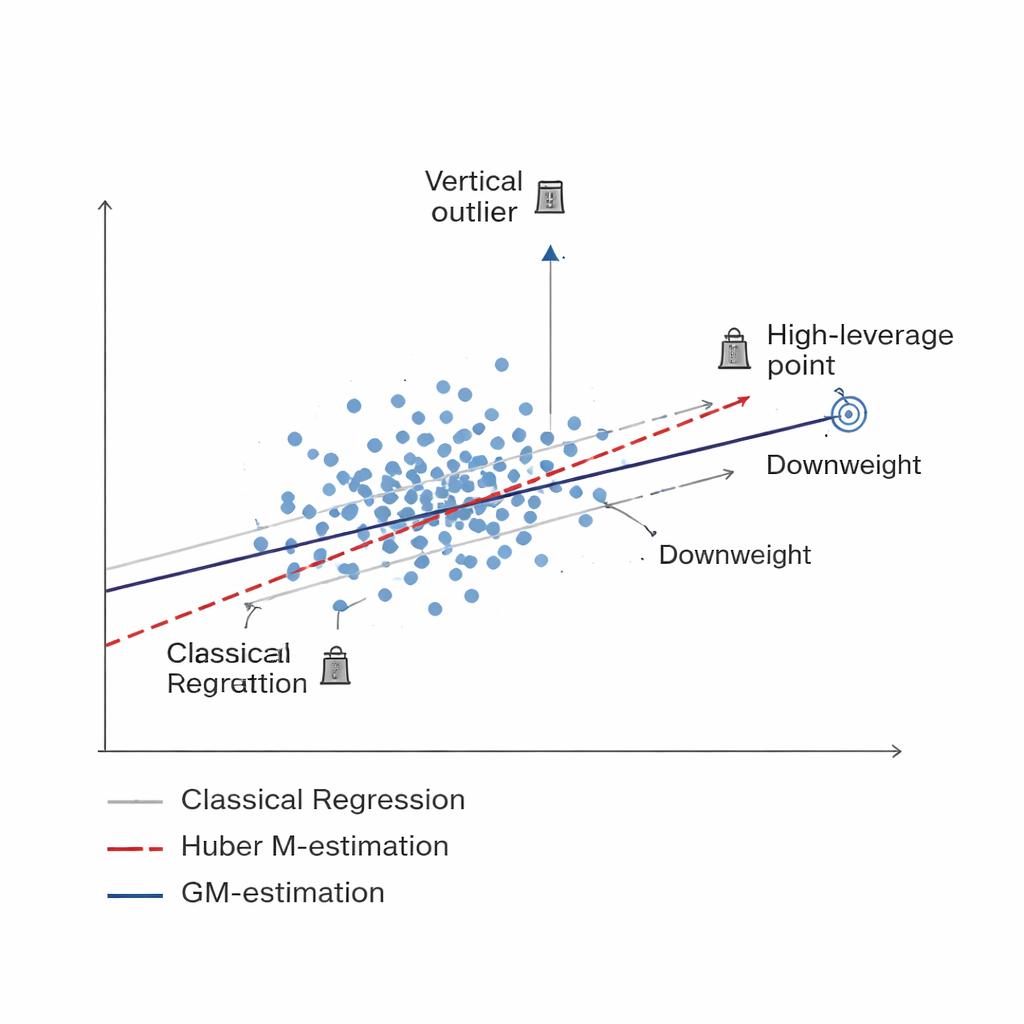
Gli strumenti standard per stimare una media di popolazione, come la semplice media campionaria o la regressione ordinaria, presuppongono che la maggior parte dei punti dati segua schemi regolari, senza outlier estremi o casi insoliti. Nei sondaggi socio-economici, nel monitoraggio ambientale e nelle statistiche agricole questa speranza è spesso disattesa. Poche misurazioni difettose, eventi rari ma estremi o risposte errate possono allontanare le stime dalla verità, aumentando sia il bias sia l’incertezza. Lavori precedenti hanno cercato di attenuare l’impatto di tali outlier usando metodi cosiddetti robusti, incluso un approccio noto e diffuso come la Huber M-estimation. Pur essendo utili, questi metodi proteggono soprattutto dai valori estremi nella variabile di esito e restano vulnerabili a schemi insoliti nelle informazioni esplicative associate.
Un modo più intelligente per ridurre il peso dei dati compromessi Figure 1.
Lo studio sviluppa una nuova famiglia di stimatori basata sulla Generalized M-estimation, o GM-estimation. Invece di trattare ogni unità campionaria allo stesso modo, i metodi GM assegnano pesi adattivi che dipendono simultaneamente da due aspetti: quanto è estrema la risposta di un’unità (un outlier verticale) e quanto è insolita l’informazione associata (un punto ad alta leva). Tre versioni specifiche — chiamate Mallows-GM, Schweppes-GM e SIS-GM — sono progettate per configurazioni di indagine comuni, inclusi il campionamento casuale semplice senza ripetizione e disegni stratificati più complessi in cui la popolazione è suddivisa in gruppi relativamente omogenei. Controllando congiuntamente entrambi i tipi di osservazioni problematiche, questi stimatori mirano a mantenere stabile la stima finale della media di popolazione anche quando i dati sono fortemente contaminati.
Mettere alla prova i nuovi stimatori
Per valutare l’efficacia degli stimatori basati su GM, l’autore conduce ampi esperimenti numerici. Innanzitutto si analizzano dati reali sull’agricoltura del tabacco in due versioni: una pulita e una deliberatamente contaminata in cui un’unità è sostituita da valori estremi. I nuovi stimatori vengono confrontati con la regressione tradizionale e i metodi robusti basati su Huber usando una misura chiamata efficienza relativa percentuale, che riflette quanto è più piccolo l’errore di stima. Su un’ampia gamma di dimensioni del campione, gli stimatori GM superano costantemente i metodi più vecchi, in particolare quando i dati includono valori estremi. In alcuni scenari, lo stimatore GM più performante riduce l’errore di oltre il 50% rispetto all’approccio di Huber.
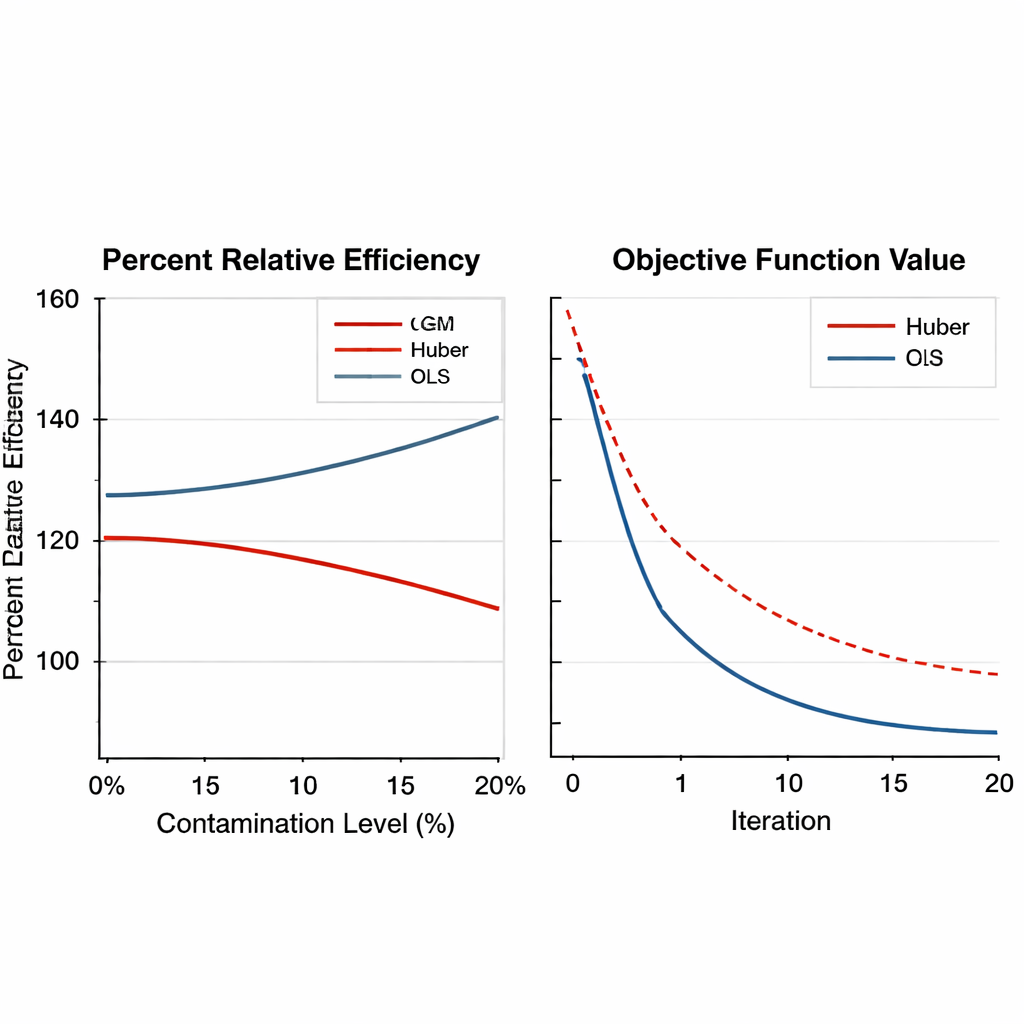
Robustezza attraverso disegni, contesti e scelte di tuning Figure 2.
Il lavoro amplia poi i test con simulazioni su larga scala. Vengono generate popolazioni artificiali con diverse forme — distribuzioni normali, asimmetriche e a code pesanti — e contaminate con frazioni variabili di outlier, da nessuna fino al 20%. Si considerano sia piani di campionamento semplici sia stratificati, e la forza della relazione tra la variabile principale e le variabili esplicative viene variata da debole a forte. Gli stimatori GM non solo mantengono il loro vantaggio in presenza di forte contaminazione, raggiungendo spesso guadagni di efficienza superiori al 150%, ma mostrano anche una convergenza numerica stabile e regolare. È importante sottolineare che le loro prestazioni cambiano poco quando i parametri interni di tuning vengono regolati entro intervalli ragionevoli, il che significa che i praticanti non devono ottimizzarli finemente per ogni nuovo sondaggio.
Cosa significa per i sondaggi nel mondo reale
In termini semplici, l’articolo dimostra che gli stimatori proposti basati su GM offrono un modo più sicuro per trasformare campioni imperfetti in stime della media dell’intera popolazione. In condizioni ideali e con dati puliti sono circa altrettanto accurati quanto i metodi classici. Ma quando i dati includono errori di misurazione, valori riportati in modo errato o rari eventi estremi — come spesso accade nei sondaggi nazionali, nel monitoraggio ambientale e nelle statistiche finanziarie — forniscono risposte sostanzialmente più affidabili. Poiché sono computazionalmente praticabili e funzionano bene in diversi disegni e contesti, questi stimatori offrono ai professionisti dei sondaggi un aggiornamento pratico che può rendere le decisioni basate sulle prove più resilienti all’inevitabile disordine dei dati reali.
Citazione: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation.
Sci Rep16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5
Parole chiave: campionamento statistico, stima robusta, valori anomali, generalized M-estimation, media di popolazione finita