Clear Sky Science · it
Riconoscimento cieco dei codici di canale basato su reti neurali convoluzionali con fusione di caratteristiche a doppio ramo
Radio più intelligenti per spettri affollati
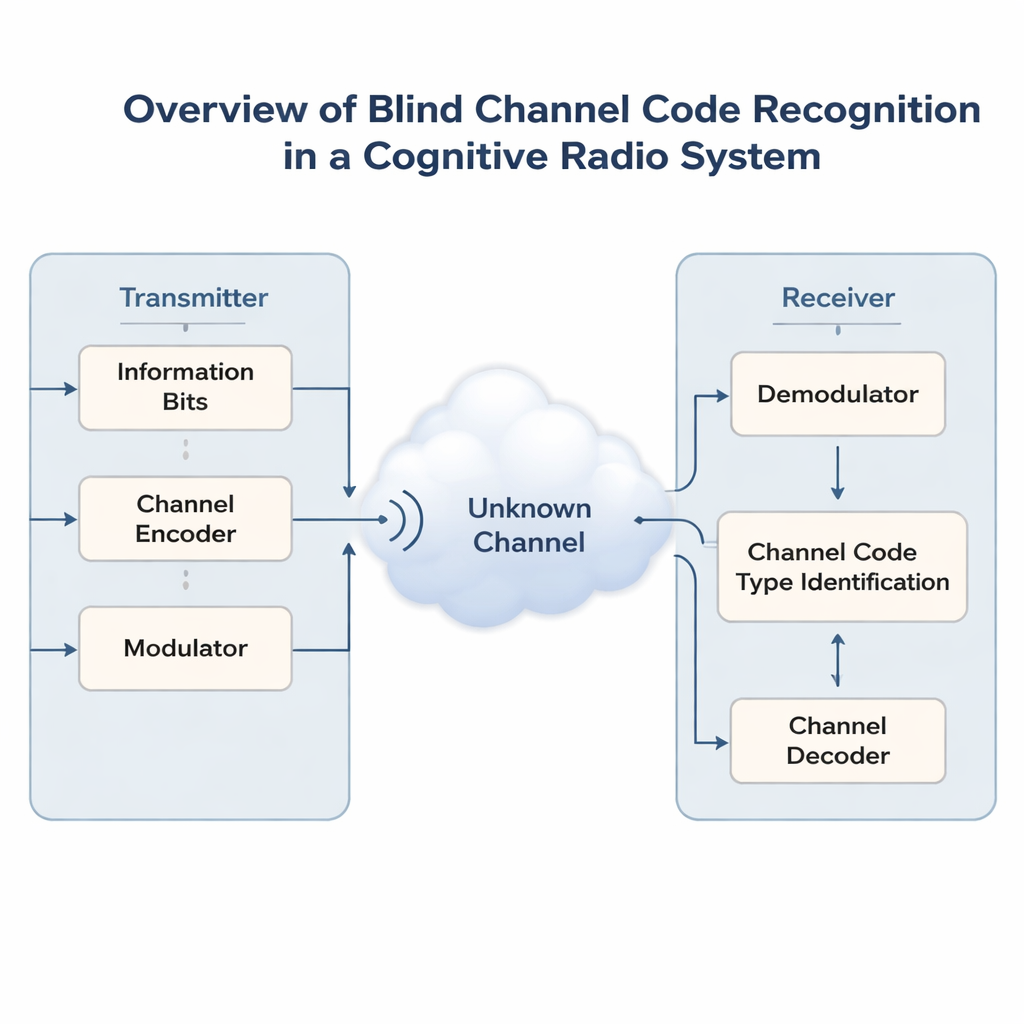
Le reti wireless stanno diventando affollate mentre telefoni, sensori e veicoli competono per le stesse bande. Per evitare il caos, le future “radio cognitive” dovranno prima ascoltare e poi condividere in modo intelligente lo spettro già occupato da altri. Un problema chiave è che queste radio spesso non sanno come il segnale originale sia stato protetto dagli errori prima della trasmissione. Questo articolo introduce un nuovo metodo di intelligenza artificiale in grado di indovinare il codice di correzione degli errori nascosto usato su un segnale—senza alcuna informazione preventiva—facilitando ai ricevitori intelligenti il sincronizzarsi e comunicare in modo affidabile.
Perché i codici di correzione nascosti sono importanti
I collegamenti wireless moderni proteggono i dati con codici di correzione degli errori, che aggiungono ridondanza strutturata in modo che i ricevitori possano correggere gli errori causati da rumore e interferenze. Diverse situazioni richiedono codici diversi: semplici codici di Hamming, codici più potenti come BCH e Reed–Solomon, codici flessibili LDPC e Polar, o codici a flusso come convoluzionali e Turbo. In contesti non cooperativi—come comunicazioni militari, monitoraggio dello spettro o bande condivise aperte—i ricevitori non possono chiedere al trasmettitore quale codice stia usando. Vedono solo uno stream di bit rumoroso. Indovinare correttamente lo schema di codifica, un compito chiamato riconoscimento cieco del codice, è essenziale prima che possa avvenire qualsiasi decodifica significativa o elaborazione di livello superiore.
Limiti dei metodi di riconoscimento precedenti
La ricerca precedente si è concentrata o su una sola famiglia di codici alla volta o si è basata su statistiche costruite a mano, come la frequenza di ripetizione dei bit, quanto casuale appare una sequenza, o trucchi algebrici mirati a un codice specifico. Questi approcci possono dire “questo è un qualche tipo di codice a blocchi” ma faticano a distinguere simultaneamente diversi formati diffusi. Il deep learning ha recentemente migliorato la situazione trattando gli stream di bit un po’ come frasi in un modello linguistico. Tuttavia, la maggior parte delle reti neurali osserva soltanto sequenze grezze o soltanto caratteristiche progettate manualmente, e tipicamente gestisce al più due o tre tipi di codice insieme. La loro accuratezza cala bruscamente quando il tasso di errore dei bit aumenta, proprio quando il riconoscimento robusto è più necessario.
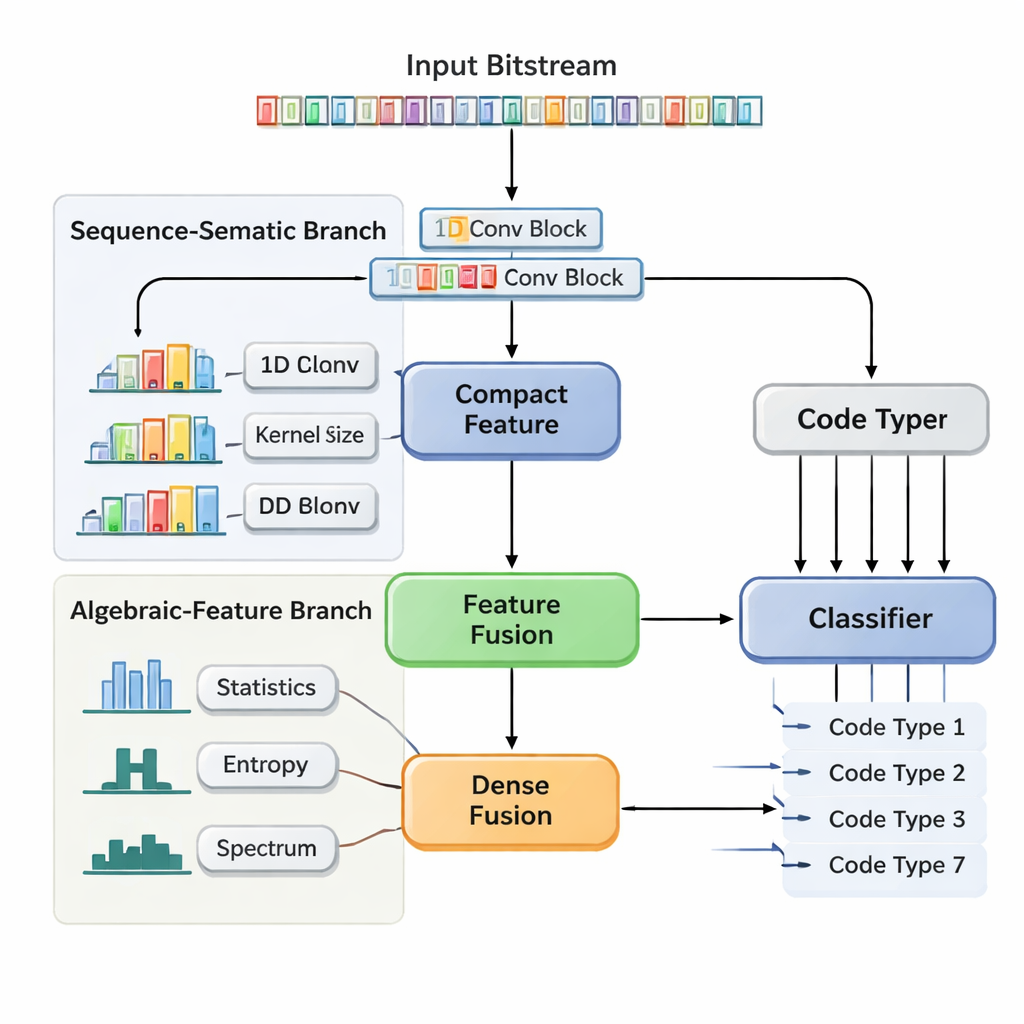
Una rete neurale a due binari che guarda struttura e statistiche
Gli autori propongono una Rete Neurale Convoluzionale a Fusione di Caratteristiche a Doppio Ramo (DBFCNN) che affronta il riconoscimento cieco di sette codici ampiamente utilizzati in un’unica passata: Hamming, BCH, Reed–Solomon, LDPC, Polar, codici convoluzionali e Turbo. Il primo ramo tratta i bit in arrivo come “parole” corte, raggruppandoli in blocchi da 8 bit e mappando ogni blocco in un vettore denso, analogamente a un embedding di parole nell’elaborazione del linguaggio naturale. Applica quindi una serie di convoluzioni monodimensionali con diverse dimensioni di finestra e tassi di dilatazione. Filtri piccoli catturano pattern a corto raggio, come la struttura rigorosa dei semplici codici a blocchi, mentre filtri più grandi e dilatati coprono intervalli più lunghi, rilevando tracce di interleaver e schemi di parità tipici dei codici Turbo e LDPC. Un passaggio di pooling globale comprime il tutto in un riassunto compatto dell’“impronta” strutturale della sequenza.
Misure costruite a mano che stabilizzano il modello
Il secondo ramo adotta una prospettiva molto diversa. Invece dei bit grezzi, calcola sette famiglie di statistiche descrittive che gli ingegneri sanno essere sensibili alle scelte di codifica. Queste includono la frequenza di run di bit identici, la complessità della sequenza, quanto appare casuale, quanto si correla con copie traslate di sé stessa e come l’energia si distribuisce tra le frequenze. Misure aggiuntive sondano quanto il codice sembri “lineare” e come si comportano blocchi locali di bit. Poiché queste statistiche cambiano lentamente con l’aumentare del rumore, offrono alla rete una prospettiva stabile e tolerante al rumore. Una piccola sotto-rete neurale trasforma questo vettore di caratteristiche in un’altra rappresentazione compatta. Infine, DBFCNN concatena i due rami, normalizza e regolarizza le caratteristiche combinate e le passa a un classificatore che restituisce probabilità per ciascuno dei sette tipi di codice.
Dimostrare l’affidabilità in condizioni rumorose
Per testare rigorosamente DBFCNN, gli autori hanno generato più di un milione di esempi sintetici coprendo sette famiglie di codici, molteplici impostazioni di parametri e tassi di errore dei bit che vanno da quasi assenti a condizioni estremamente rumorose. Hanno addestrato e testato il modello usando procedure Monte Carlo accurate per evitare sovrapposizioni nascoste tra dati di addestramento e di test. Su questa ampia gamma, DBFCNN ha costantemente superato tre solidi baseline, incluso un precedente CNN dilatato multiscala progettato specificamente per questo compito. A tassi di errore moderati e bassi (tasso di errore dei bit inferiore a 10⁻³), la nuova rete ha identificato correttamente il tipo di codice circa il 98% delle volte, migliorando l’accuratezza assoluta di circa 5–11 punti percentuali rispetto al modello precedente più performante. Anche quando il livello di rumore è diventato piuttosto severo, DBFCNN ha mantenuto un vantaggio chiaro e poteva ancora riconoscere con alta confidenza diversi codici complessi.
Cosa significa per le radio intelligenti del futuro
Per chi non è esperto, la scoperta chiave è che questo lavoro mostra come combinare conoscenza di dominio e deep learning possa rendere le radio molto più autonome. DBFCNN apprende il sottile “accento” dei diversi codici di correzione degli errori negli stream di bit rumorosi ascoltando in due modi contemporaneamente: un ramo coglie dettagli locali, mentre l’altro misura indizi statistici globali. Fondendo queste visioni, il sistema può di solito determinare esattamente quale schema di codifica è in uso, senza alcuna cooperazione dal trasmettitore. Questa capacità è un mattoncino fondamentale per radio cognitive che possono unirsi a reti sconosciute, adattarsi a ambienti cambianti e sfruttare meglio uno spettro scarso, mantenendo al contempo comunicazioni affidabili anche quando le onde radio sono affollate e rumorose.
Citazione: Ma, Y., Lei, Y., Liu, C. et al. Blind recognition of channel codes based on dual-branch feature fusion convolutional neural networks. Sci Rep 16, 5159 (2026). https://doi.org/10.1038/s41598-026-35558-7
Parole chiave: radio cognitiva, codifica di canale, deep learning, correzione degli errori, classificazione dei segnali