Clear Sky Science · it
Geolocalizzazione degli utenti social basata su K-medoids e rete di attenzione su grafo con kernel gaussiano
Perché i tuoi tweet possono rivelare dove vivi
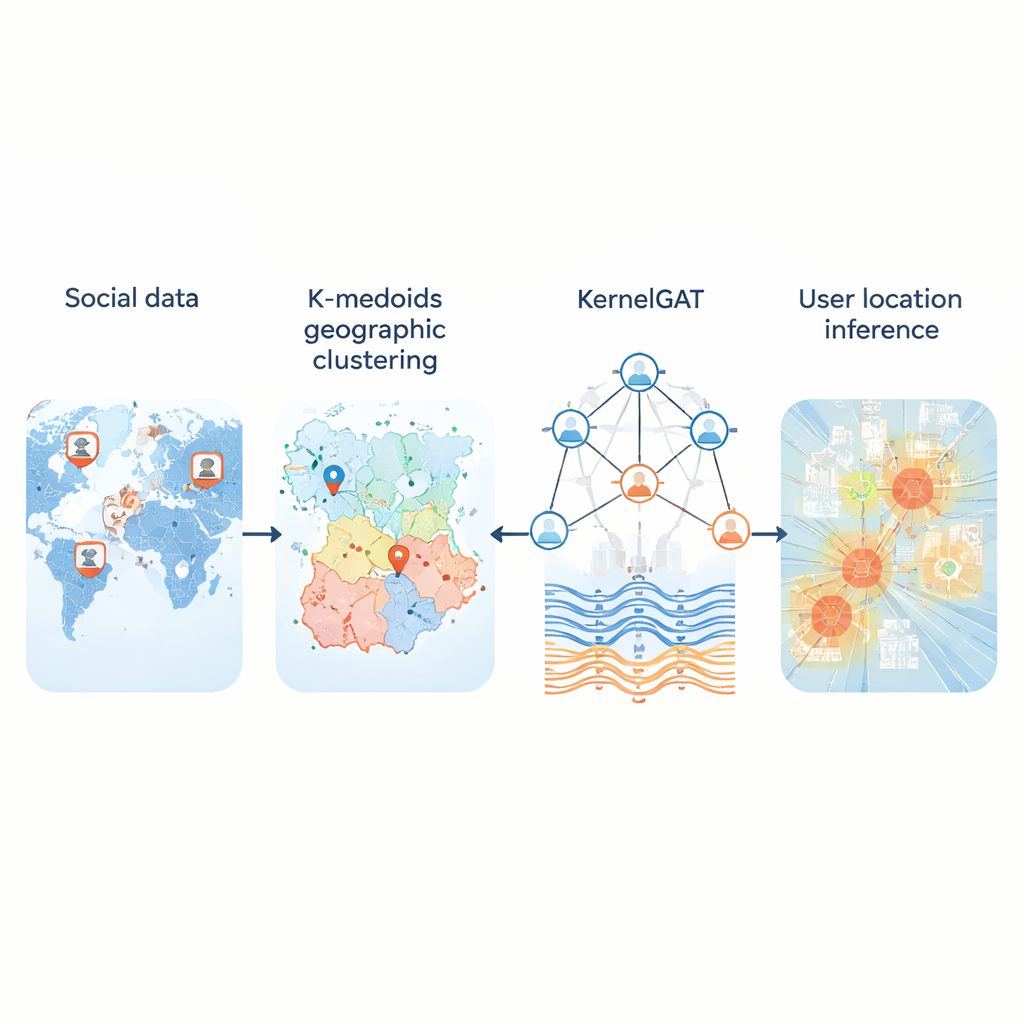
Ogni giorno milioni di persone postano sui social senza condividere le coordinate GPS. Tuttavia quei post lasciano comunque indizi su dove gli utenti vivono, lavorano e viaggiano. Poter inferire la posizione da questa traccia pubblica è importante per tutto, dalla risposta alle emergenze e il tracciamento delle malattie, alle raccomandazioni locali e ai servizi mirati. Questo articolo introduce un nuovo metodo, chiamato KMKGAT, che usa sia ciò che le persone dicono sia come sono connesse online per stimare dove si trovano, con maggiore accuratezza rispetto agli approcci precedenti.
Dalla conversazione online ai luoghi reali
Quando gli utenti scrivono tweet o microblog possono menzionare toponimi, usare gerghi locali o interagire con amici nelle vicinanze. Aziende come Twitter (ora X) conoscono l’indirizzo Internet di un utente, ma i ricercatori esterni e i fornitori di servizi di solito no. Devono quindi lavorare con informazioni pubbliche: il testo stesso, i profili utente e chi parla con chi. I metodi precedenti si dividevano in tre categorie. I metodi solo-contenuto estraevano parole e hashtag per indovinare le posizioni. I metodi solo-rete si basavano sul fatto che le persone tendono a interagire con utenti vicini. Una terza famiglia, più potente, combinava entrambe le viste, ma aveva ancora punti ciechi—soprattutto per le persone in aree scarsamente popolate e per utenti le cui connessioni online coprono grandi distanze.
Raggruppamenti geografici più intelligenti con centri utente reali
Un problema chiave è come trasformare il globo continuo in un insieme di regioni che un computer possa imparare a prevedere. Molti sistemi dividono la mappa in una griglia fissa. Questo funziona abbastanza bene nelle città ma fallisce nelle aree rurali, dove celle enormi coprono centinaia di chilometri. Il nuovo metodo sostituisce le griglie rigide con il clustering k-medoids, un modo di raggruppare gli utenti in cui ogni regione è centrata su un utente reale invece che su un punto artificiale. Questo rende le regioni compatte e meno sensibili agli outlier, in particolare dove gli utenti sono scarsi. Nei test su tre grandi dataset Twitter che coprono gli Stati Uniti e il mondo, questa partizionamento adattivo ha ridotto gli errori tipici rispetto agli schemi basati su griglia e ha fornito regioni “home” più realistiche per gli utenti.
Lasciare che la rete si concentri su utenti vicini e simili
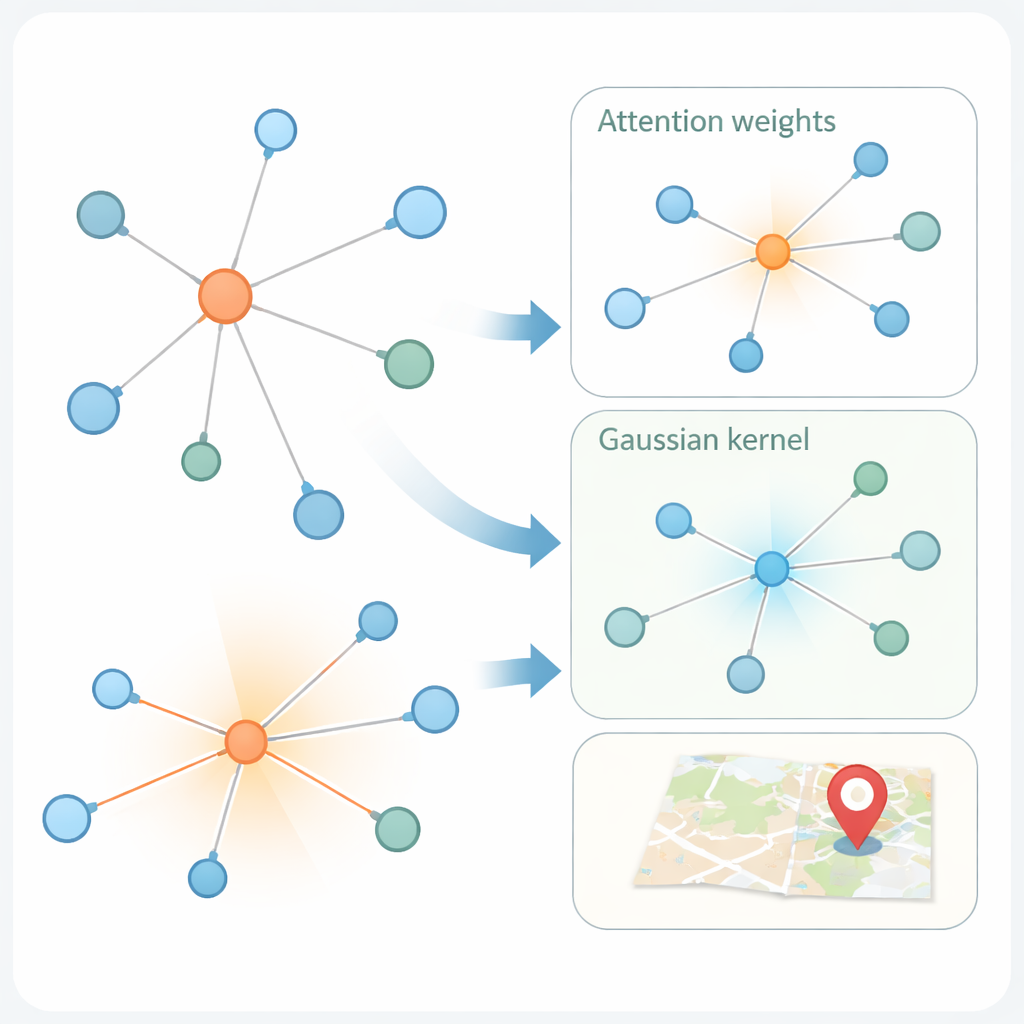
La seconda innovazione riguarda il modo in cui il modello apprende dal grafo sociale. Le moderne “graph attention network” già pesano in modo diverso i vicini di un utente, in base a quanto sono simili le loro rappresentazioni di caratteristiche. Ma la sola similarità può ingannare: un account a New York e uno a Londra possono usare un linguaggio simile ma essere lontani geograficamente. KMKGAT integra l’attenzione con un kernel gaussiano, un filtro matematico che favorisce i vicini le cui caratteristiche apprese sono vicine a quelle dell’utente target e attenua l’influenza di quelli distanti. Molti di questi kernel, combinati come una miscela di lenti, permettono al modello di catturare la località a scale diverse. Questo rispetta il principio semplice ma potente che le interazioni online sono spesso più forti tra persone fisicamente più vicine.
Caratteristiche testuali leggere ma informative sulla localizzazione
Piuttosto che affidarsi a pesanti modelli linguistici profondi, che possono faticare con lo stile rumoroso e pieno di gergo dei tweet, gli autori usano una tecnica classica chiamata TF–IDF per trasformare la raccolta di post di ciascun utente in un insieme di parole chiave pesate. Parole comuni come “the” o “lol” ottengono poco peso, mentre termini più rari e specifici di una regione emergono in alto. Queste caratteristiche testuali vengono quindi associate a ogni utente nel grafo sociale e passate attraverso la rete di attenzione migliorata. Interessante è che i risultati migliori sono stati ottenuti quando la maggior parte delle caratteristiche testuali veniva casualmente eliminata durante l’addestramento, suggerendo che solo una piccola frazione delle parole aiuta davvero con la localizzazione e il resto aggiunge principalmente rumore.
Sconfiggere lo stato dell’arte su scala
Per valutare le prestazioni, i ricercatori hanno misurato la distanza, in chilometri, tra il centro della regione predetta e le coordinate note di ciascun utente, e la percentuale di utenti collocati entro 161 km (100 miglia) dalla loro posizione reale. Su tre dataset di riferimento di Twitter, KMKGAT ha costantemente eguagliato o superato sistemi esistenti forti, migliorando l’accuratezza entro 161 km di qualche punto percentuale—un guadagno significativo a questo livello di maturità. I benefici sono stati più chiari su reti di piccola e media dimensione, mentre su un enorme grafo globale il metodo è stato limitato dall’obbligo di campionare solo i vicini immediati durante l’addestramento.
Cosa significa in termini quotidiani
Per i non specialisti, la conclusione è che è sempre più fattibile stimare dove si trovano gli utenti dei social media, anche se non condividono mai un tag di posizione. Raggruppando gli utenti in regioni realistiche basate su account reali e insegnando al modello a fidarsi principalmente di vicini simili e vicini nella rete sociale, KMKGAT restringe l’area in cui qualcuno probabilmente vive o da cui posta. Questo può aiutare i soccorritori a trovare persone durante i disastri, migliorare la ricerca e le raccomandazioni locali e supportare studi su come l’informazione si diffonde nei luoghi. Allo stesso tempo mette in luce quanto le nostre interazioni online ordinarie possano rivelare della vita offline, sottolineando l’importanza di un uso ponderato dei dati e di protezioni della privacy.
Citazione: Jiao, A., Qiao, Y., Li, P. et al. Social user geolocation based on K-medoids and Gaussian Kernel graph attention network. Sci Rep 16, 5115 (2026). https://doi.org/10.1038/s41598-026-35532-3
Parole chiave: geolocalizzazione sui social media, posizione utenti Twitter, reti neurali su grafi, servizi basati sulla posizione, privacy online