Clear Sky Science · it
Classificazione delle intenzioni per i servizi amministrativi universitari utilizzando una rete neurale ricorrente bidirezionale modificata da un algoritmo di ottimizzazione Kepler sviluppato
Assistenza digitale più intelligente per le domande quotidiane del campus
Gli studenti universitari oggi si aspettano risposte rapide e accurate a qualsiasi ora — che stiano facendo domanda di ammissione, registrandosi ai corsi o chiedendo informazioni sull’aiuto finanziario. Questo articolo esplora un nuovo tipo di chatbot potenziato dall’IA progettato specificamente per i servizi amministrativi universitari, con un focus sulla gestione sia dell’inglese che del greco. Insegnando a un singolo sistema a comprendere meglio cosa intendono gli studenti e quali dettagli sono rilevanti, gli autori mirano a rendere gli sportelli di assistenza digitale più veloci, affidabili e facili da gestire.
Perché gli attuali chatbot si confondono ancora
La maggior parte dei chatbot moderni si basa su un campo chiamato comprensione del linguaggio naturale, che scompone la domanda dello studente in due parti principali. La prima è l’intento: cosa lo studente vuole fare, ad esempio “iscriversi a un corso” o “chiedere una scadenza”. La seconda sono le entità: i frammenti concreti di informazione presenti nella domanda, come un codice corso, il semestre o il nome del corso di studi. I sistemi tradizionali usano modelli separati per questi due compiti. Questa separazione spreca memoria e potenza di calcolo e può portare a risposte incoerenti — per esempio individuare correttamente un codice corso ma non collegarlo all’azione giusta. Questi problemi peggiorano nei contesti multilingue, dove la stessa idea può essere espressa in molte forme diverse tra le lingue.
Un solo cervello invece di due
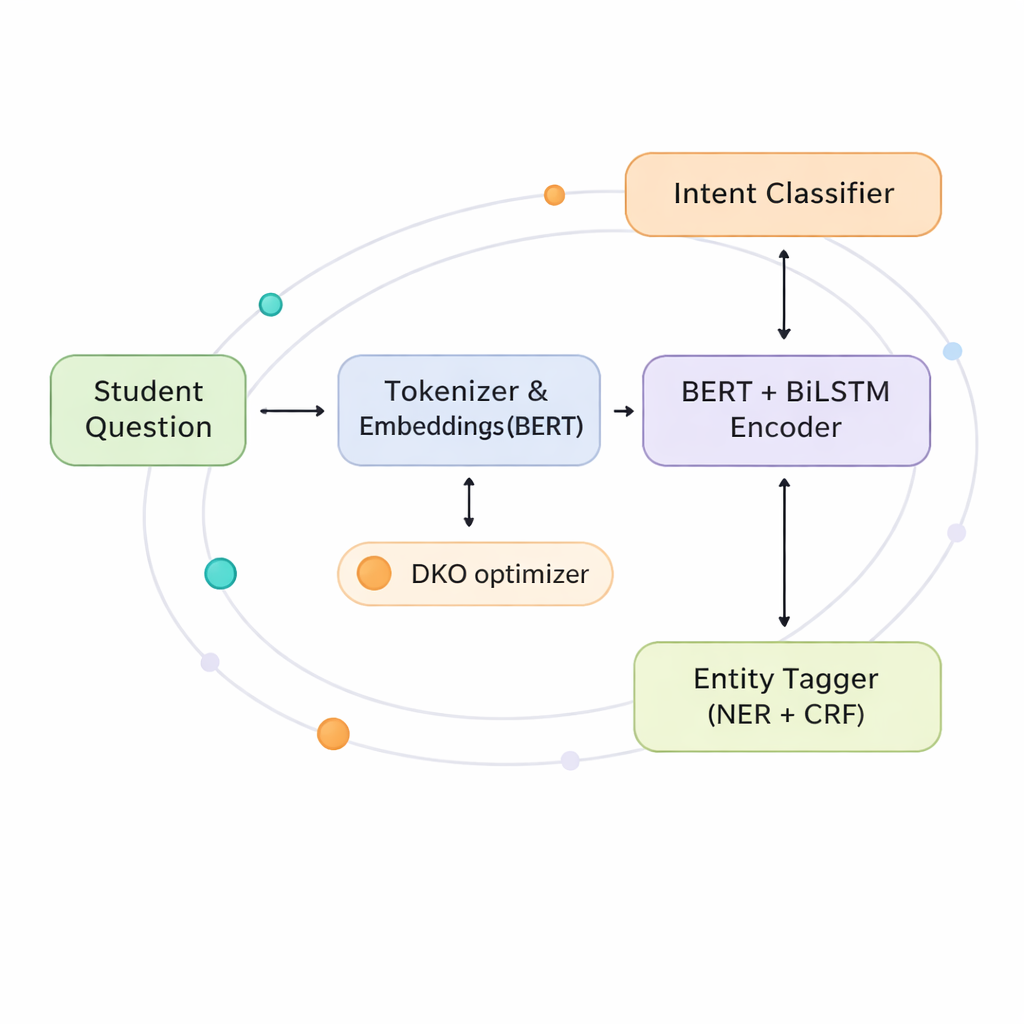
Gli autori propongono un modello congiunto che impara a riconoscere contemporaneamente intenti ed entità, usando un “cervello” condiviso anziché due separati. Al suo nucleo c’è la combinazione di due tecniche potenti. La prima, BERT, analizza l’intera frase in una volta per catturarne il significato globale. La seconda, una rete LSTM bidirezionale, presta attenzione all’ordine delle parole sia da sinistra a destra sia da destra a sinistra, il che aiuta a tracciare relazioni vicine come quale corso è associato a quale semestre. Sulla base di questa comprensione condivisa, il sistema si dirama in due testine: una predice l’intento dello studente e l’altra etichetta ogni parola con il suo ruolo come entità o meno.
Lasciare che i compiti si parlino tra loro
Per sfruttare al massimo questo cervello condiviso, il modello include uno strato “co-interactive transformer” che permette ai due compiti di informarsi a vicenda in tempo reale. Quando il sistema decide l’intento, può guardare alle entità che ritiene presenti; quando etichetta le entità, può appoggiarsi all’intento che sembra più probabile. Questo scambio aiuta a risolvere ambiguità, come se “abbandonare” si riferisca all’uscita da un corso o alla cancellazione di una domanda, ed è particolarmente utile in greco, dove le forme e l’ordine delle parole sono più flessibili rispetto all’inglese. Condividendo rappresentazioni e meccanismi di attenzione in questo modo, il modello riduce il numero di parametri di quasi la metà rispetto all’esecuzione di due grandi modelli separati, rendendolo più pratico per i dipartimenti IT universitari.
Un modo ispirato al cosmo per addestrare il modello
Addestrare un modello così ricco è difficile: i metodi di ottimizzazione standard possono essere lenti e sensibili a impostazioni finemente tarate. Gli autori introducono l’algoritmo Developed Kepler Optimization (DKO), ispirato al modo in cui i pianeti orbitano attorno al sole. In questa analogia, diverse versioni del modello sono come pianeti che esplorano lo spazio delle possibili impostazioni dei parametri mentre vengono attratti dal “sole” che rende meglio. DKO avvia questi candidati con una distribuzione più diversificata del solito e poi aggiusta continuamente le loro “orbite” in base alle prestazioni. Questo approccio accelera l’apprendimento di circa il 42 percento rispetto a un metodo popolare chiamato Adam, rendendo inoltre l’addestramento più stabile, in particolare su dati complessi e multilingue.
Test sul campo con gli studenti
Il team ha valutato il proprio sistema su diversi dataset, inclusi UniWay, una raccolta di domande in inglese e greco sui servizi universitari, e xSID, un benchmark noto per la comprensione di comandi brevi. Su tutti, il modello congiunto ha costantemente superato sistemi basati su regole, reti neurali più vecchie e persino forti baseline transformer. In prove sul campo in due università — una solo inglese e una bilingue — il chatbot ha identificato correttamente intenti ed entità degli studenti circa nove volte su dieci, e gli studenti hanno valutato la loro soddisfazione intorno a 4,5 su 5. Le prestazioni sono rimaste solide anche quando i dati di addestramento sono stati ridotti, suggerendo che il metodo è robusto in lingue e domini con risorse più scarse.
Cosa significa questo per studenti e università
Per un lettore non tecnico, il punto chiave è che gli autori hanno progettato un “motore di ascolto” per i chatbot universitari più efficiente e accurato. Unificando individuazione delle intenzioni ed estrazione dei dettagli, e usando un metodo di addestramento ispirato alle orbite, il loro sistema può comprendere meglio le richieste degli studenti usando meno memoria e tempo di addestramento. Questo potrebbe tradursi in risposte più veloci, meno fraintendimenti e supporto multilingue 24 ore su 24 senza sovraccaricare il personale umano. Pur restando delle sfide — come l’adattamento a nuove politiche, più lingue e pattern di utilizzo a lungo termine — il lavoro indica la strada verso sistemi di assistenza del campus che risultino più reattivi, equi e scalabili.
Citazione: Yang, Z., Lu, M. & Huang, S. Intent classification for university administrative services using a bidirectional recurrent neural network modified by a developed Kepler optimization algorithm. Sci Rep 16, 6263 (2026). https://doi.org/10.1038/s41598-026-35504-7
Parole chiave: chatbot universitari, classificazione delle intenzioni, riconoscimento delle entità denominate, IA multilingue, algoritmi di ottimizzazione