Clear Sky Science · it
Identificazione automatica di entità biomediche contestualmente rilevanti con LLM con fondamento
Perché una migliore etichettatura degli articoli medici è importante
Ogni anno compaiono migliaia di studi biomedici, ciascuno ricco di dettagli su geni, tipi cellulari, malattie e terapie. Eppure gran parte di queste informazioni resta imprigionata in PDF lunghi, rendendo difficile per altri ricercatori trovare esattamente i dati di cui hanno bisogno. Questo articolo esplora come l’intelligenza artificiale moderna — i grandi modelli linguistici, o LLM — possa estrarre automaticamente i termini biomedici chiave dagli articoli di ricerca, aiutando a trasformare pubblicazioni sparse in risorse ben organizzate e ricercabili.
Da documenti disordinati a mattoni ricercabili
I centri di ricerca biomedica, come i Collaborative Research Centers tedeschi, dipendono da dati chiari e strutturati per rendere gli studi riutilizzabili nel tempo. Tradizionalmente, i ricercatori dovevano etichettare manualmente i propri dataset con entità importanti come organismi, linee cellulari e geni — un compito tedioso e dispendioso in termini di tempo. Gli LLM possono leggere testi completi e comprendere il contesto, rendendoli strumenti promettenti per automatizzare questa etichettatura. C’è però un problema: decidere quali termini siano davvero rilevanti dipende dalla domanda scientifica e da come i dati verranno riutilizzati. Gli autori operano all’interno di uno schema di metadati progettato con cura dal CRC incentrato sulla nefrologia, “NephGen”, che indica all’IA quali tipi di entità cercare e come dovrebbero essere organizzate.
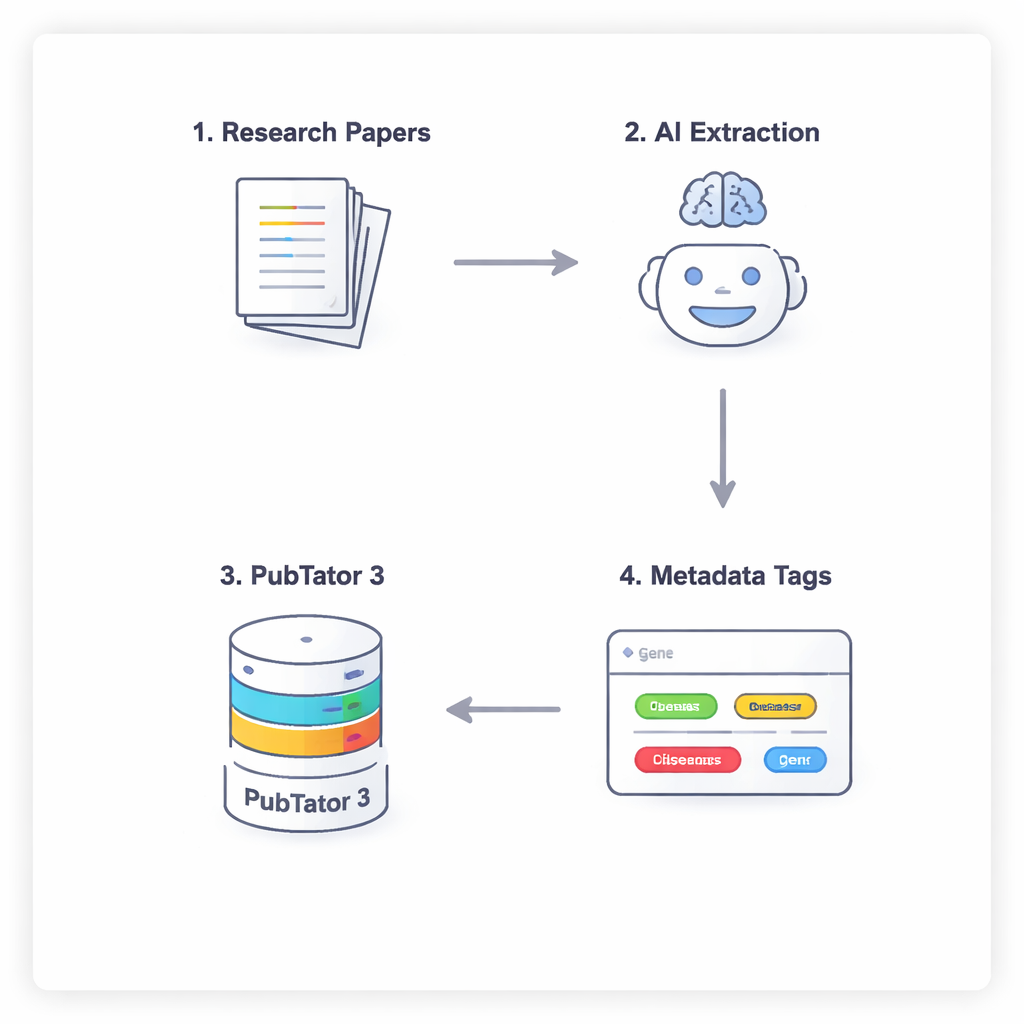
Una conversazione in quattro passi tra IA e un database biologico
Per impedire all’IA di limitarsi a indovinare o “allucinare” fatti biomedici, i ricercatori utilizzano un processo in quattro fasi che obbliga i modelli a ragionare con attenzione e a verificare le proprie risposte. Primo, il modello scandisce il testo completo di un articolo (ignorando discussione e riferimenti) per suggerire entità potenzialmente rilevanti. Secondo, deve consultare uno strumento esterno, PubTator 3, un ampio database biomedico, per confermare che ogni termine suggerito esista effettivamente e abbia un identificatore riconosciuto. Terzo, l’IA assegna ogni entità confermata a uno slot nello schema di metadati NephGen, che raggruppa le entità in una struttura gerarchica progettata dall’uomo. Infine, il modello consolida il tutto in un output JSON strutturato, essenzialmente un sommario leggibile dalla macchina delle entità biomediche chiave presenti nell’articolo.
Testare otto modelli di IA con ricerche reali sul rene
Il team ha implementato questo flusso di lavoro usando API per 14 diversi LLM e ha scoperto che soltanto otto erano in grado di seguire in modo affidabile i requisiti stringenti, come restituire JSON valido e usare correttamente gli strumenti. Successivamente hanno applicato questi otto modelli a sei articoli di ricerca in nefrologia e hanno chiesto a ciascun autore di revisionare la lista finale di entità proposta dall’IA in un breve colloquio faccia a faccia. Poiché non esiste un numero “corretto” fisso di entità da estrarre, gli autori si sono concentrati sulla precisione: quale frazione delle entità suggerite gli scienziati giudicavano corretta. Utilizzando metodi di meta-analisi statistica adattati per proporzioni prossime al 100%, hanno stimato la precisione per ciascun modello tenendo conto della variabilità tra gli articoli.
Alta accuratezza, ma compromessi su sforzo, costo e velocità
Nel complesso, i sistemi di IA hanno raggiunto una precisione media di circa il 91%, il che significa che la grande maggioranza delle entità suggerite è stata giudicata corretta. GPT-4.1, GPT-4o Mini e Gemini 2.0 Flash hanno mostrato la precisione più alta — grossomodo tra il 94% e il 98% — sebbene le differenze non fossero statisticamente significative. I modelli Gemini tendevano a proporre in assoluto più entità, portando a più etichette corrette ma anche a più elementi da verificare per gli umani. Alcuni modelli più piccoli o economici, come GPT-4.1 Nano, erano più rapidi e a basso costo ma sostanzialmente meno accurati. Gli autori hanno visualizzato queste tensioni usando frontiere di Pareto, identificando combinazioni di modelli che bilanciano precisione, numero di entità corrette, costo e tempo di elaborazione: per esempio, GPT-4o Mini è emerso come particolarmente interessante quando sia l’accuratezza che il basso costo sono priorità.
Perché gli umani restano necessari nel processo
Nonostante le buone prestazioni, lo studio mette in luce limitazioni importanti. I modelli a volte confondevano informazioni sull’articolo pubblicato con dettagli che non erano veramente pertinenti al dataset sottostante che gli utenti futuri potrebbero voler riutilizzare. Questa confusione riflette una sfida più ampia nell’estrazione automatica di testi: gli articoli scientifici discutono molto più di quanto finisca in un dataset condiviso. Gli autori raccomandano pertanto che esperti umani continuino a revisionare le annotazioni generate dall’IA prima della loro pubblicazione. Segnalano inoltre che la loro valutazione copre solo sei articoli di nefrologia, quindi sono necessari test più ampi in altri ambiti. Col tempo, un flusso di lavoro di routine “human-in-the-loop” potrebbe costruire un set di riferimento condiviso, rendendo possibile misurare non solo la precisione ma anche quante entità l’IA ha omesso.
Cosa significa per la condivisione futura dei dati biomedici
Lo studio mostra che, se guidati e ancorati a database affidabili, gli LLM moderni possono aiutare in modo affidabile ad annotare gli articoli biomedici, riducendo notevolmente l’onere manuale per i ricercatori. I migliori modelli si avvicinano a una precisione di livello esperto offrendo una gamma di compromessi tra accuratezza, costo e velocità. Per ora la revisione umana rimane essenziale per garantire che le annotazioni corrispondano veramente ai dataset e al contesto di ricerca. Ma man mano che gli strumenti e i modelli open source maturano, flussi di lavoro come questo potrebbero diventare la spina dorsale standard per trasformare l’odierna inondazione di articoli medici nei dati organizzati e riutilizzabili di domani.
Citazione: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
Parole chiave: estrazione di testi biomedici, large language model, annotazione dei metadati, IA con fondamento, ricerca in nefrologia