Clear Sky Science · it
Diagnosi automatica della degenerazione maculare legata all’età mediante tecniche di machine learning e elaborazione delle immagini
Perché questo è importante per la vista
Con l’aumentare dell’aspettativa di vita, sempre più persone sono interessate dalla degenerazione maculare legata all’età (AMD), una patologia che erode lentamente la visione centrale e può rendere difficile o impossibile leggere, guidare o riconoscere volti. I medici oftalmologi possono individuare segnali di allarme precoci nelle fotografie della parte posteriore dell’occhio, ma esaminare manualmente migliaia di pazienti richiede tempo e competenze specializzate. Questo studio esplora come uno strumento trasparente basato sul machine learning possa aiutare a intercettare l’AMD precocemente dalle foto di routine, senza fare affidamento su fragili e poco interpretabili “scatole nere” di deep learning.
Cercare i problemi nella zona di visione più acuta
L’AMD colpisce la macula, una piccola area scura vicino al centro della retina che garantisce la visione nitida e dettagliata. Molti sistemi automatici cercano di individuare minuscoli depositi grassi chiamati drusen nell’immagine dell’occhio intero, ma le drusen possono essere facilmente confuse con altre macchie chiare come piccoli sanguinamenti e variano molto per forma e dimensione. Questo le rende difficili da rilevare in modo affidabile al computer, e anche gli esperti devono spesso controllare con attenzione i risultati. Gli autori seguono un approccio diverso: invece di cercare direttamente le drusen su tutta la retina, si concentrano sulla regione maculare e misurano come la sua texture e il colore cambiano in presenza di AMD.
Dalla fotografia grezza all’“impronta” della macula
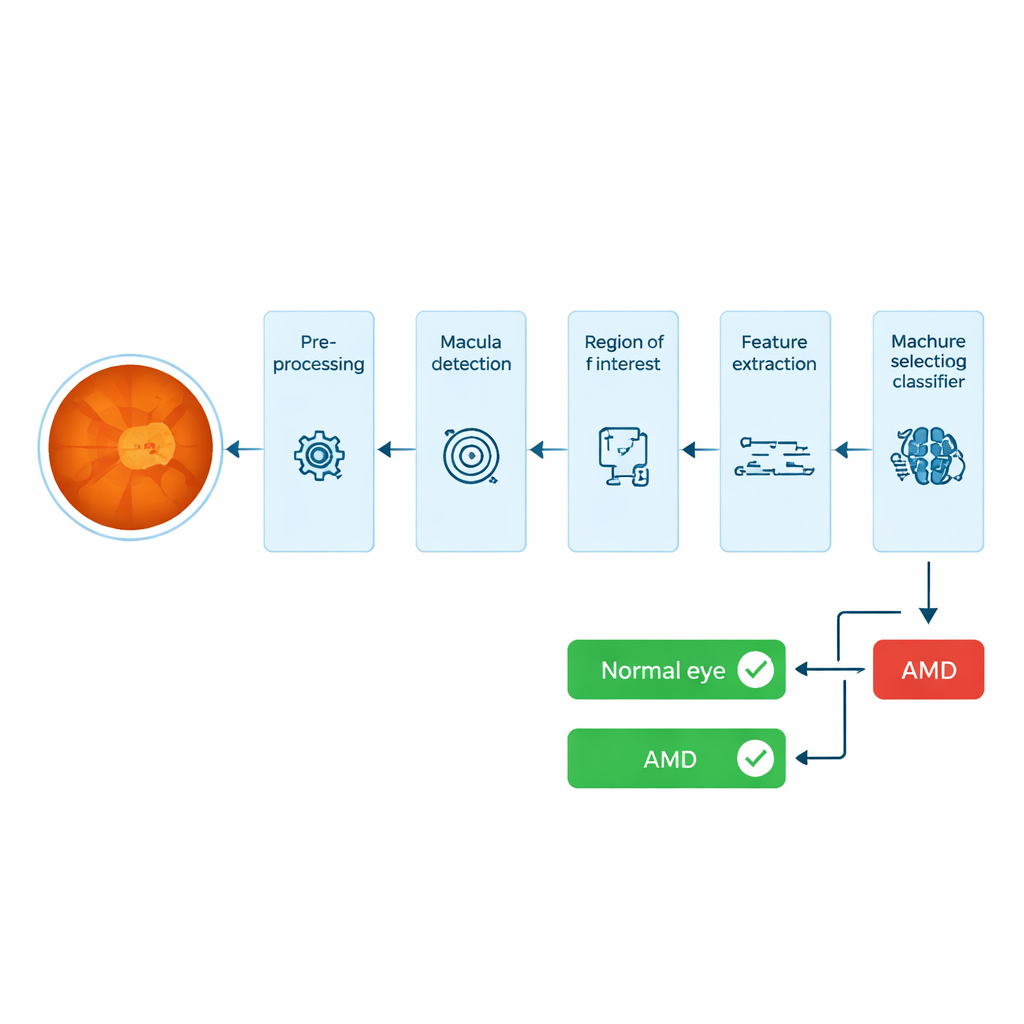
Il sistema parte da una fotografia a colori della parte posteriore dell’occhio, chiamata immagine del fundus. Innanzitutto migliora il contrasto usando passaggi standard di elaborazione delle immagini in modo che le aree scure e chiare siano più facili da distinguere. Successivamente localizza automaticamente il disco ottico — l’area circolare luminosa da cui escono i nervi — e sfrutta la sua relazione geometrica nota con la macula per cercare lungo una stretta striscia dell’immagine la regione più scura che corrisponde alle dimensioni e alla posizione attese della macula. Intorno a questo punto il sistema ritaglia un piccolo rettangolo: questa è la regione di interesse, che contiene il tessuto più probabile a rivelare danni precoci associati all’AMD.
Trasformare pattern e colori in numeri
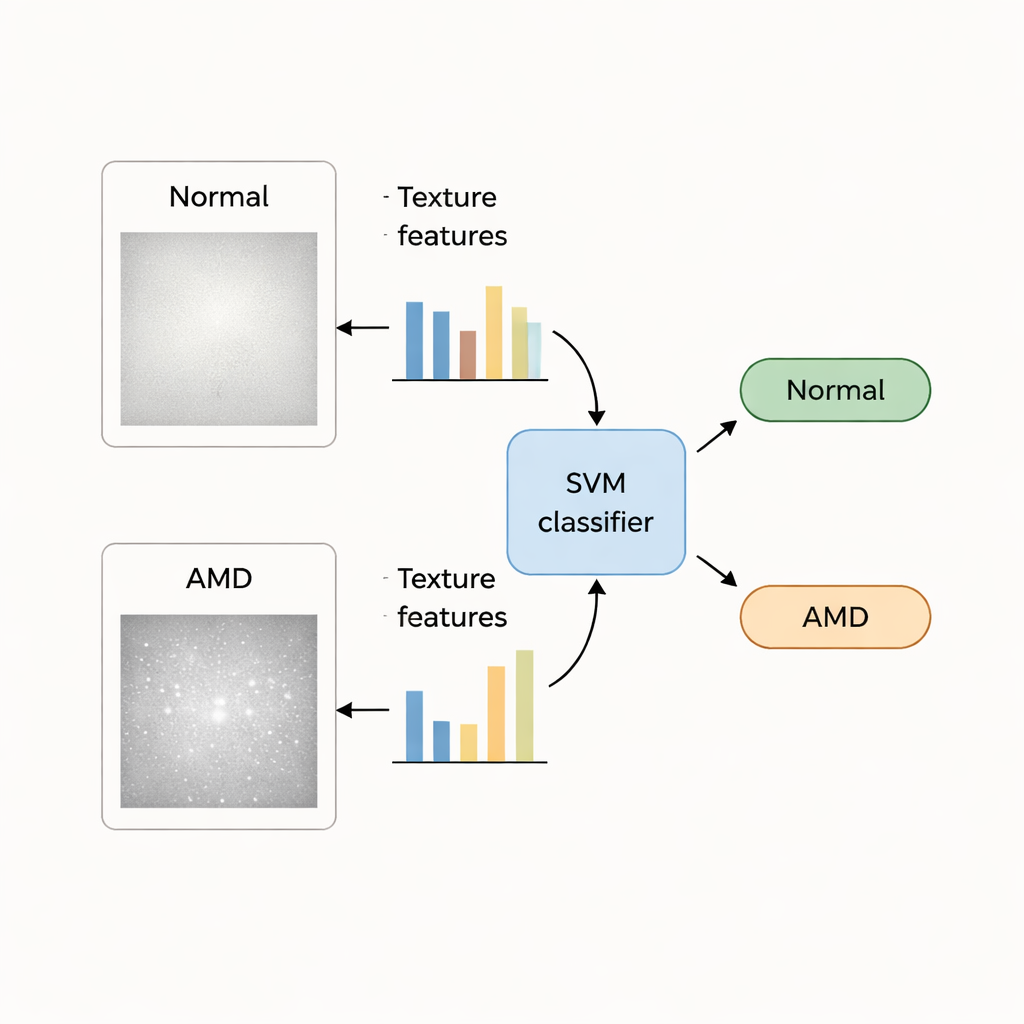
All’interno di questo frammento maculare, i ricercatori calcolano un ampio insieme di descrittori numerici, o “feature artigianali”. Le feature di texture catturano come sono disposte le intensità dei pixel — se la superficie appare liscia, macchiata o irregolare — mentre le feature di colore registrano spostamenti di luminosità e tonalità che possono riflettere cambiamenti nel pigmento e nello stato dei tessuti. In totale vengono misurate 140 feature di texture e 48 di colore per ciascuna immagine oculare. Poiché non tutti questi numeri sono ugualmente informativi, il team applica test statistici e un metodo di classificazione delle feature per selezionare un sottoinsieme più piccolo che separi al meglio occhi sani e affetti da AMD, eliminando misurazioni ridondanti o rumorose.
Addestrare le macchine a dire “AMD” o “normale”
Con queste feature selezionate, gli autori addestrano diversi classificatori noti nel machine learning — Support Vector Machine (SVM), k‑Nearest Neighbor, Naïve Bayes e una semplice rete neurale — per apprendere la differenza tra occhi normali e affetti da AMD. Utilizzano due raccolte pubbliche di immagini retiniche: il dataset STARE, che include 35 immagini normali e 74 con AMD, e il più ampio dataset ODIR, con centinaia di casi etichettati. Per testare l’affidabilità dividono ripetutamente ciascun dataset in porzioni di training e test, ruotando le immagini in modo che ogni occhio sia testato almeno una volta, quindi misurano accuratezza, tasso di errore e quanto spesso l’AMD viene rilevata correttamente.
Risultati chiari e ragionamenti più trasparenti
In tutti i test il classificatore SVM che utilizza le feature di texture della regione maculare si distingue. Sul dataset STARE distingue correttamente AMD da occhi normali in quasi il 99% dei casi; su ODIR l’accuratezza è circa del 95%. Le informazioni di texture si rivelano più potenti del solo colore, e la combinazione di entrambi i tipi di feature non supera le prestazioni della sola texture. Sebbene alcuni sistemi di deep learning in letteratura raggiungano risultati comparabili o leggermente superiori, essi richiedono grandi quantità di dati etichettati e forniscono scarse indicazioni sui segnali visivi su cui si basano. Al contrario, le feature artigianali di texture e colore in questo studio corrispondono a strutture riconoscibili della retina, rendendo il sistema più interpretabile per i clinici.
Cosa significa per i pazienti
In termini pratici, lo studio dimostra che un programma relativamente semplice e trasparente può analizzare una foto oculare standard, ingrandire la macula e — con elevata affidabilità — segnalare se probabilmente è presente AMD, senza dover prima tracciare ogni piccolo deposito. Uno strumento del genere potrebbe aiutare cliniche oftalmiche e programmi di screening a ordinare rapidamente un gran numero di immagini, facendo in modo che i pazienti con malattia precoce siano visitati prima dagli specialisti, e fornendo inoltre ai medici una visione più chiara dei pattern visivi che la macchina utilizza per formulare il suo giudizio.
Citazione: Agarwal, D., Bhargava, A., Alsharif, M.H. et al. Automatic diagnosis of age-related macular degeneration using machine learning and image processing techniques. Sci Rep 16, 5037 (2026). https://doi.org/10.1038/s41598-026-35428-2
Parole chiave: degenerazione maculare legata all’età, imaging retinico, machine learning, rilevamento precoce delle malattie, analisi di immagini medicali