Clear Sky Science · it
Combinare frammentazione dei parametri e mescolamento di gruppo per difendersi dal server non affidabile nel federated learning
Perché è importante proteggere i modelli condivisi
I nostri telefoni, gli ospedali e le banche sono sempre più alimentati dall’intelligenza artificiale. Spesso molte organizzazioni vorrebbero addestrare insieme un modello condiviso, ma le leggi e il buon senso impediscono di mettere i dati grezzi in un unico luogo. Il federated learning è nato per risolvere questa tensione: ogni partecipante allena sul proprio dispositivo e condivide solo gli aggiornamenti del modello. Ma questo articolo mostra che anche quegli aggiornamenti possono perdere informazioni private se il server centrale è curioso o disonesto — e presenta quindi un nuovo modo per mantenere più al sicuro sia i nostri dati sia le nostre identità.
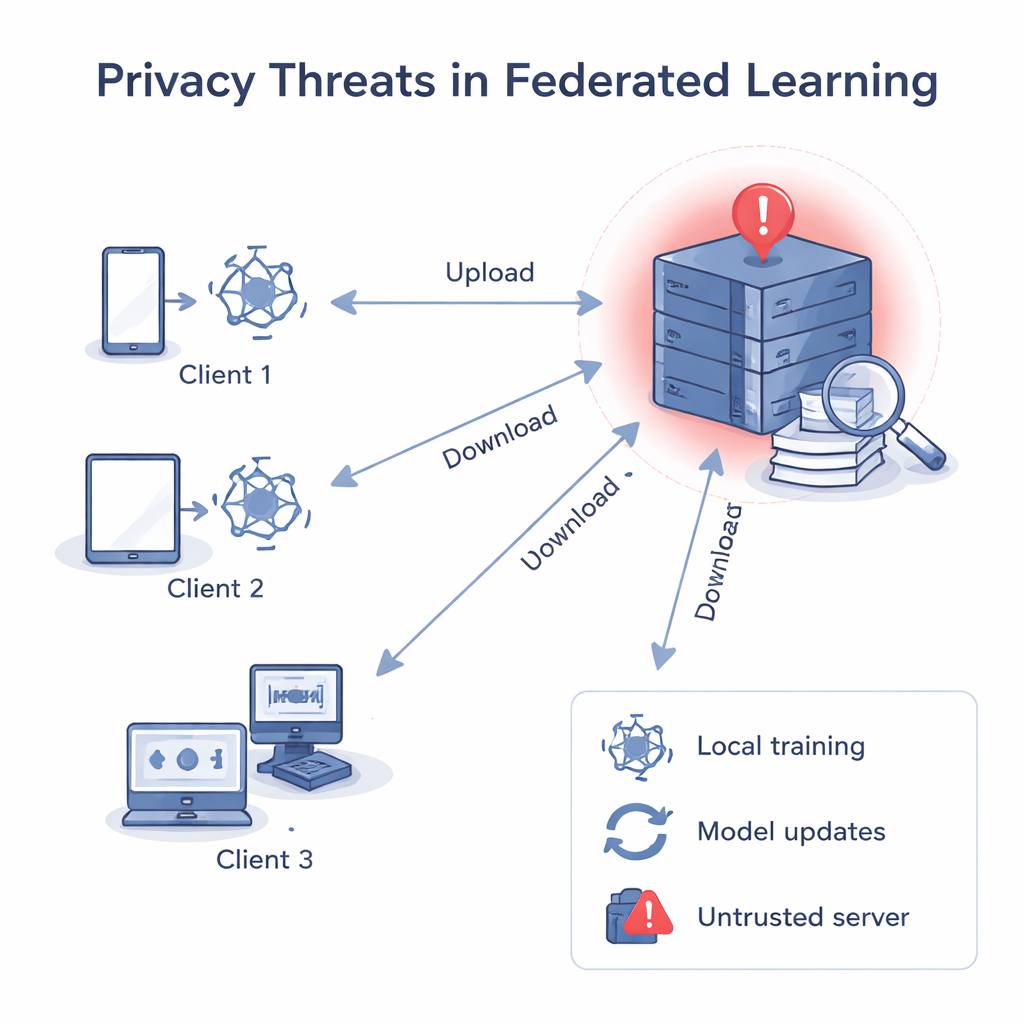
Quando il server non dovrebbe essere considerato affidabile
Nel federated learning classico, un server centrale distribuisce un modello comune, ogni client lo migliora usando i propri dati e poi invia il modello aggiornato indietro. Il server media questi aggiornamenti in un modello globale migliore. Anche se i dati grezzi non lasciano mai i dispositivi, ricerche precedenti hanno mostrato che gradienti e pesi — i numeri all’interno del modello — possono essere “invertiti” per ricostruire dati privati, come immagini o testi, oppure per indovinare se una specifica registrazione è stata usata nell’addestramento. Se il server centrale non è affidabile, può analizzare singolarmente l’aggiornamento di ogni client, apprendere sui dati locali di quel client e persino collegare un aggiornamento a una persona o organizzazione specifica.
Spezzare gli aggiornamenti in pezzi innocui
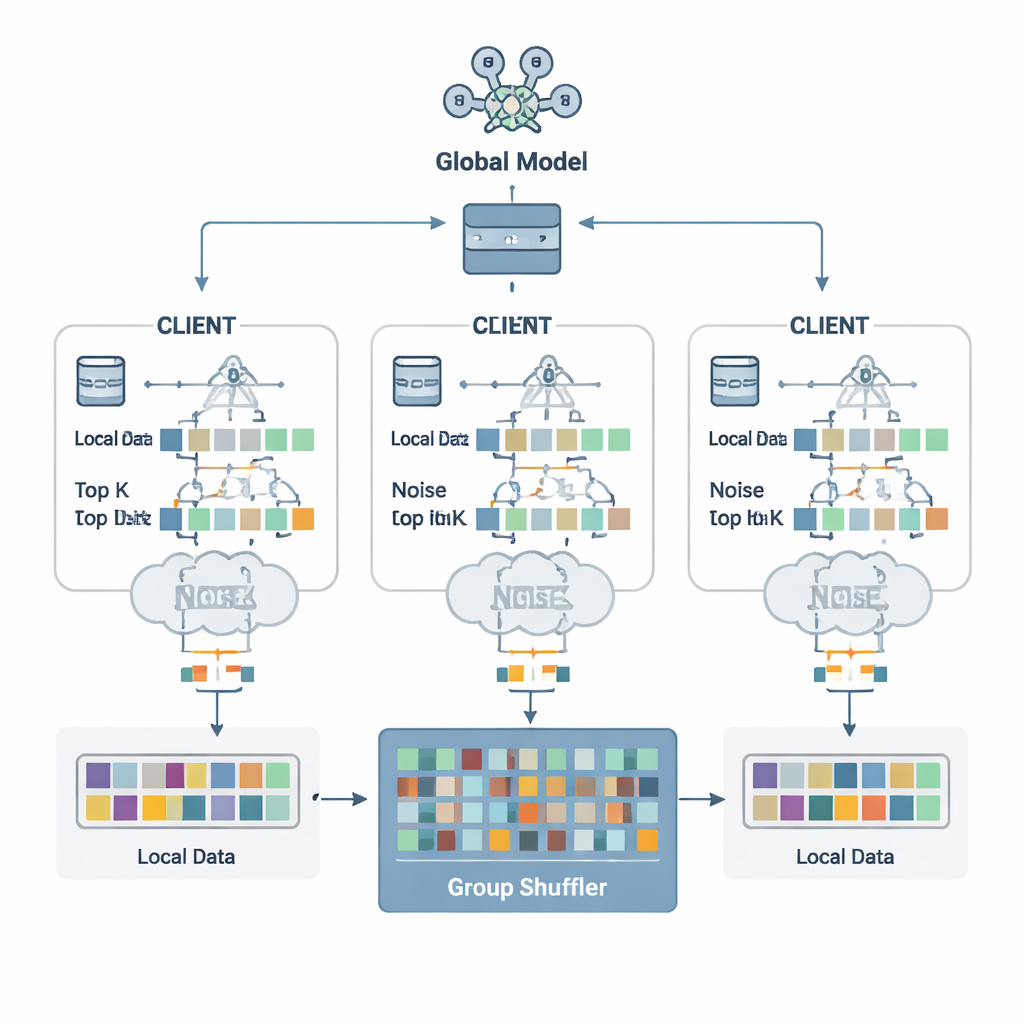
Gli autori propongono uno schema di difesa chiamato Security Defense based on Parameter Fragmentation Group Shuffling (SDPFGS). La prima idea è semplice ma potente: non inviare mai un aggiornamento completo. Invece, ogni client divide il proprio aggiornamento del modello in diversi “frammenti” artificiali. La maggior parte di questi è riempita con numeri casuali, e solo l’ultimo viene aggiustato in modo che tutti i frammenti sommati restituiscano il vero aggiornamento. Qualsiasi frammento singolo, o anche diversi di essi, sembra rumore e rivela quasi nulla sui dati originali. Questo trucco matematico è simile alla condivisione segreta: solo combinando tutte le parti si può ricostruire il tutto.
Aggiungere rumore e mescolare il tutto
Inviare molti frammenti potrebbe comunque essere inefficiente e, se esaminati insieme, potrebbe permettere a un attaccante di inferire di più. Per evitarlo, ogni client seleziona solo i valori di frammento più importanti — le Top‑K voci che contano di più per l’apprendimento — e vi aggiunge rumore casuale calibrato secondo i principi della privacy differenziale. Questo rumore rende statisticamente difficile stabilire se i dati di una singola persona hanno influenzato un dato valore. Poi entra in gioco il secondo ingrediente chiave: il mescolamento di gruppo. Invece di inviare i frammenti direttamente al server, i client li inoltrano a uno “shuffler” fidato che mescola frammenti provenienti da molti client in gruppi prima di inoltrarli. Dopo questo mescolamento, il server non può più dire quale frammento proviene da quale client, interrompendo il collegamento tra aggiornamenti e identità.
Mantenere l’accuratezza riducendo le fughe di informazioni
Il team ha testato SDPFGS su benchmark standard per immagini e testi, inclusi cifre scritte a mano (MNIST), foto di abbigliamento (Fashion‑MNIST) e immagini a colori (CIFAR‑10 e CIFAR‑100), oltre a un compito di classificazione di notizie. Hanno confrontato il loro metodo con diverse tecniche di privacy all’avanguardia che usano solo rumore, solo mescolamento o una semplice compressione dei gradienti. In tutti questi esperimenti, SDPFGS ha costantemente eguagliato o superato l’accuratezza dei metodi concorrenti, usando al contempo meno comunicazione e tempo di addestramento rispetto a molti di essi. In particolare, sotto attacchi di inversione del modello — dove un avversario cerca di ricostruire esempi di addestramento — SDPFGS ha mostrato il tasso di successo dell’attacco più basso, ossia ha perduto meno informazioni sui dati sottostanti.
Cosa significa per gli utenti di tutti i giorni
Per un lettore non esperto, il messaggio principale è che «nascondere i dati» non basta; dobbiamo anche nascondere ciò che i nostri dispositivi inviano durante l’addestramento. SDPFGS lo fa trasformando ogni aggiornamento del modello in frammenti rumorosi e mescolati che da soli sono inutili ma che, combinati, producono comunque un modello globale di alta qualità. Il risultato è una barriera più solida contro un server curioso o compromesso, con solo un costo minimo in termini di accuratezza ed efficienza. Man mano che il federated learning si diffonde in sanità, finanza e dispositivi intelligenti, tecniche come SDPFGS potrebbero aiutare a garantire che le persone beneficino di potenti modelli condivisi senza consegnare le chiavi della loro vita privata.
Citazione: Guo, H., Chen, W., Li, J. et al. Combining parameter fragmentation and group shuffling to defend against the untrustworthy server in federated learning. Sci Rep 16, 5097 (2026). https://doi.org/10.1038/s41598-026-35420-w
Parole chiave: federated learning, privacy dei dati, privacy differenziale, attacchi di inversione del modello, aggregazione sicura