Clear Sky Science · it
Disaccordo tra valutazione umana e valutazione AI dei piani di trattamento
Perché questo conta per l’assistenza medica quotidiana
Con l’ingresso degli strumenti di intelligenza artificiale (AI) nell’aiutare i medici a scegliere i trattamenti, sorge una domanda centrale: di chi ci fidiamo di più — degli esseri umani o delle macchine? Questo studio esplora una possibilità semplice ma inquietante: i medici e i sistemi AI potrebbero non solo discordare su quale trattamento sia il migliore, ma anche su cosa costituisca in primo luogo un “buon” piano di trattamento. Comprendere questo divario è fondamentale se vogliamo che l’AI supporti, invece di alterare silenziosamente, le decisioni mediche nel mondo reale.
Una prova diretta sui consigli terapeutici
I ricercatori si sono concentrati sulla dermatologia, un campo in cui i medici gestiscono condizioni cutanee croniche che raramente hanno una sola risposta “corretta”. Dieci dermatologi esperti e due grandi modelli linguistici (LLM) — un modello di uso generale e un modello orientato al ragionamento — sono stati invitati a redigere piani di trattamento per cinque casi difficili e fittizi, come eczema severo, psoriasi con comorbilità e acne legata alla gravidanza. Per garantire equità, tutti i 60 piani sono stati riformattati in un formato comune: lunghezza, struttura e tono simili. Qualsiasi indizio ovvio sull’origine umana o artificiale del piano è stato rimosso, in modo che i giudici successivi valutassero il contenuto e non lo stile.
Come hanno giudicato gli umani e l’AI
I piani sono poi passati attraverso due turni di valutazione cieca utilizzando la stessa griglia. Primo, lo stesso gruppo di dieci dermatologi ha valutato ogni piano sulla qualità complessiva da 0 a 10, considerando quanto fosse efficace, sicuro, pratico e centrato sul paziente. Secondo, un modello AI separato — usato solo come giudice, non come autore dei piani — ha valutato gli stessi piani con le medesime istruzioni. Fondamentalmente, né i valutatori umani né il giudice AI sapevano chi avesse scritto ciascun piano. Questa impostazione ha permesso agli autori di isolare un fattore chiave: se il valutatore fosse umano o AI.
Gli umani favoriscono gli umani, l’AI favorisce l’AI
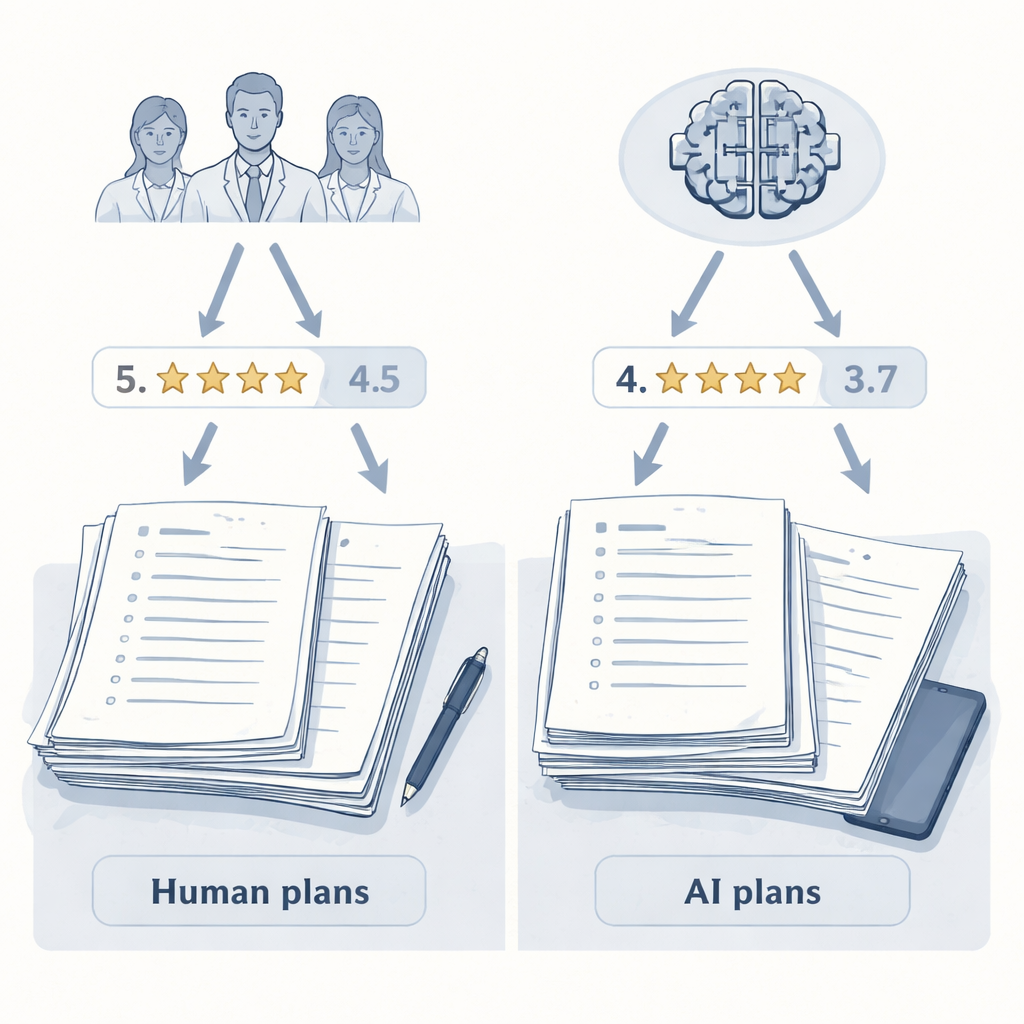
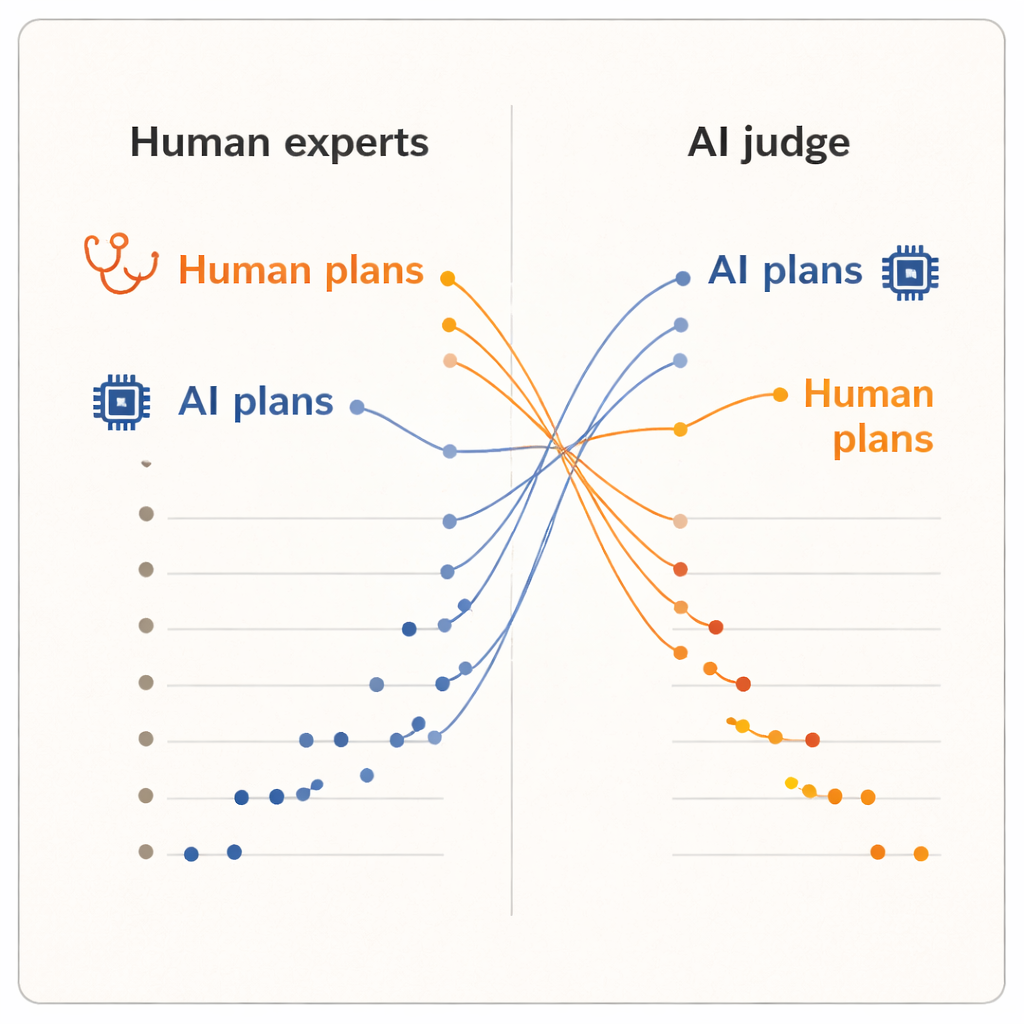
I risultati hanno mostrato un chiaro “effetto valutatore”. Quando gli umani hanno valutato i piani, hanno assegnato punteggi più alti ai piani scritti dai loro colleghi dermatologi rispetto a quelli prodotti da uno dei due sistemi AI. I piani generati da umani avevano una media leggermente più alta e occupavano le prime cinque posizioni della classifica. Uno dei modelli AI, il sistema avanzato di ragionamento, si è piazzato vicino al fondo. Ma quando il giudice AI è intervenuto, lo scenario si è capovolto. I due piani scritti dall’AI sono risaliti in cima alla graduatoria, e ogni piano dei dermatologi umani è sceso al di sotto di essi. In media, il giudice AI ha attribuito punteggi più alti ai piani generati dall’AI rispetto a quelli umani, pur leggendo esattamente gli stessi testi standardizzati visionati dai dermatologi.
Idee diverse su cosa renda un piano “buono”
Poiché i piani sono stati normalizzati nella formulazione e i giudici sono stati tenuti all’oscuro sulla provenienza, gli autori sostengono che questa divisione non può essere spiegata dalla sola lucidatura superficiale. Piuttosto, suggerisce che esseri umani e sistemi AI adottino criteri interni diversi. I clinici probabilmente si basano sull’esperienza nel mondo reale: ciò che tende ad essere fattibile nelle loro cliniche, come reagiscono i pazienti e quali compromessi risultano accettabili nella pratica. Per contro, un giudice AI addestrato su grandi raccolte di testi può preferire piani che seguono pattern comuni nella letteratura medica o nelle linee guida, anche se quei modelli non catturano pienamente vincoli locali o preferenze dei pazienti. Lo studio è di dimensioni modeste — solo dieci clinici, cinque casi e un singolo giudice AI — e misura la qualità percepita, non gli esiti reali dei pazienti. Eppure, il ribaltamento è sufficientemente netto da sollevare questioni più profonde su come valutiamo l’AI clinica.
Riconcepire come testiamo e usiamo l’AI clinica
Dai risultati gli autori traggono due lezioni generali. Primo, i tradizionali test basati sulla “risposta giusta” per l’AI medica trascurano gran parte di ciò che conta nella cura reale, dove i piani devono bilanciare efficacia, sicurezza, costi, logistica e desideri del paziente. Propongono quadri di valutazione più ricchi e multi-metrici che valutino esplicitamente queste dimensioni, impieghino più giudici umani e AI e analizzino dove e perché nascono le disaccordi invece di ridurre tutto a un unico punteggio. Secondo, suggeriscono che le differenze tra i giudizi umani e quelli dell’AI possono essere una caratteristica, non solo un difetto. Se usati con attenzione, i piani generati dall’AI potrebbero fungere da secondo parere riflessivo che spinge i medici a rivedere le proprie assunzioni, mentre i medici forniscono il contesto del mondo reale e la valutazione etica che l’AI non possiede. Costruire interfacce affidabili e trasparenti che espongano le ipotesi, permettano ai clinici di regolare le priorità e favoriscano la revisione critica potrebbe aiutare a trasformare questa tensione tra prospettive umane e AI in decisioni più sicure e bilanciate.
Citazione: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
Parole chiave: supporto decisionale clinico, intelligenza artificiale in medicina, collaborazione uomo-AI, pianificazione del trattamento, bias nella valutazione