Clear Sky Science · it
Un modello predittivo ibrido per la concentrazione di PM2.5 basato su IMF ad alta e bassa frequenza con decomposizione EMD
Perché previsioni dell’aria più pulita contano nella vita quotidiana
Le particelle fini nell’aria, note come PM2.5, sono così piccole da penetrare in profondità nei polmoni e persino entrare nel flusso sanguigno. Nel Nord della Cina, dove si concentrano industrie pesanti e il riscaldamento invernale, queste particelle raggiungono spesso livelli che possono attivare allerte sanitarie, interrompere i trasporti e perfino chiudere fabbriche e scuole. Questo studio pone una domanda molto pratica: è possibile prevedere con maggiore accuratezza i livelli orari di PM2.5, in modo che città e abitanti ricevano avvisi più tempestivi e affidabili prima che l’aria diventi pericolosa?
Uno sguardo più attento all’aria sporca del Nord della Cina
I ricercatori si sono concentrati su sei grandi città del Nord della Cina: Pechino, Tianjin, Shijiazhuang, Taiyuan, Jinan e Zhengzhou. Queste città rappresentano aree densamente popolate e industrializzate dove gli episodi di inquinamento sono frequenti, specialmente in inverno. Utilizzando dati ufficiali di monitoraggio, il team ha raccolto letture orarie di PM2.5 per l’intero anno 2021, ottenendo 8.760 punti dati per ciascuna città. Hanno scoperto che i livelli di inquinamento variano ampiamente tra le città; per esempio, Taiyuan presentava il valore medio di PM2.5 più elevato, mentre Pechino il più basso. Gli eventi estremi sono stati impressionanti: a Taiyuan le concentrazioni sono salite fino a 652 microgrammi per metro cubo durante un episodio di polvere e inquinamento a marzo, portando l’indice di qualità dell’aria al livello massimo, un chiaro segno di aria gravemente inquinata.
Perché prevedere il PM2.5 è così difficile
I livelli di PM2.5 sono influenzati contemporaneamente da molte forze: emissioni locali del traffico e delle industrie, trasporto regionale di polvere e fumo, velocità del vento, umidità e altro ancora. Di conseguenza, la serie storica dell’inquinamento si comporta meno come una curva liscia e più come un battito cardiaco irregolare. Strumenti statistici tradizionali o anche reti neurali moderne possono avere difficoltà con questo tipo di dati: possono cogliere la tendenza generale ma perdere picchi improvvisi, oppure funzionare in una città ma fallire in un’altra. Studi precedenti hanno cercato di migliorare le previsioni aggiungendo più dettaglio fisico (come i modelli di trasporto chimico) o affidandosi esclusivamente a metodi avanzati di apprendimento automatico. Questo articolo invece combina diversi metodi, ciascuno scelto per gestire un “ritmo” diverso nei dati.
Separare il segnale in ritmi veloci e lenti
Il passaggio chiave è una tecnica chiamata decomposizione empirica delle modalità (EMD), che suddivide la serie temporale originale di PM2.5 in più componenti più semplici. Alcune di queste componenti oscillano rapidamente e catturano picchi a breve termine e rumore; altre cambiano lentamente e riflettono la tendenza sottostante. Gli autori raggruppano le prime cinque componenti come parti «ad alta frequenza» e le restanti, insieme a un residuo di tendenza, come parti «a bassa frequenza». Le porzioni ad alta frequenza, più irregolari e fortemente non lineari, vengono alimentate in una rete LSTM (long short‑term memory), un tipo di modello di deep learning adatto ad apprendere schemi nel tempo. Le componenti più regolari e a bassa frequenza sono invece affidate a un metodo classico di serie temporali noto come ARIMA, efficace quando i dati si comportano in modo più regolare e approssimativamente lineare.
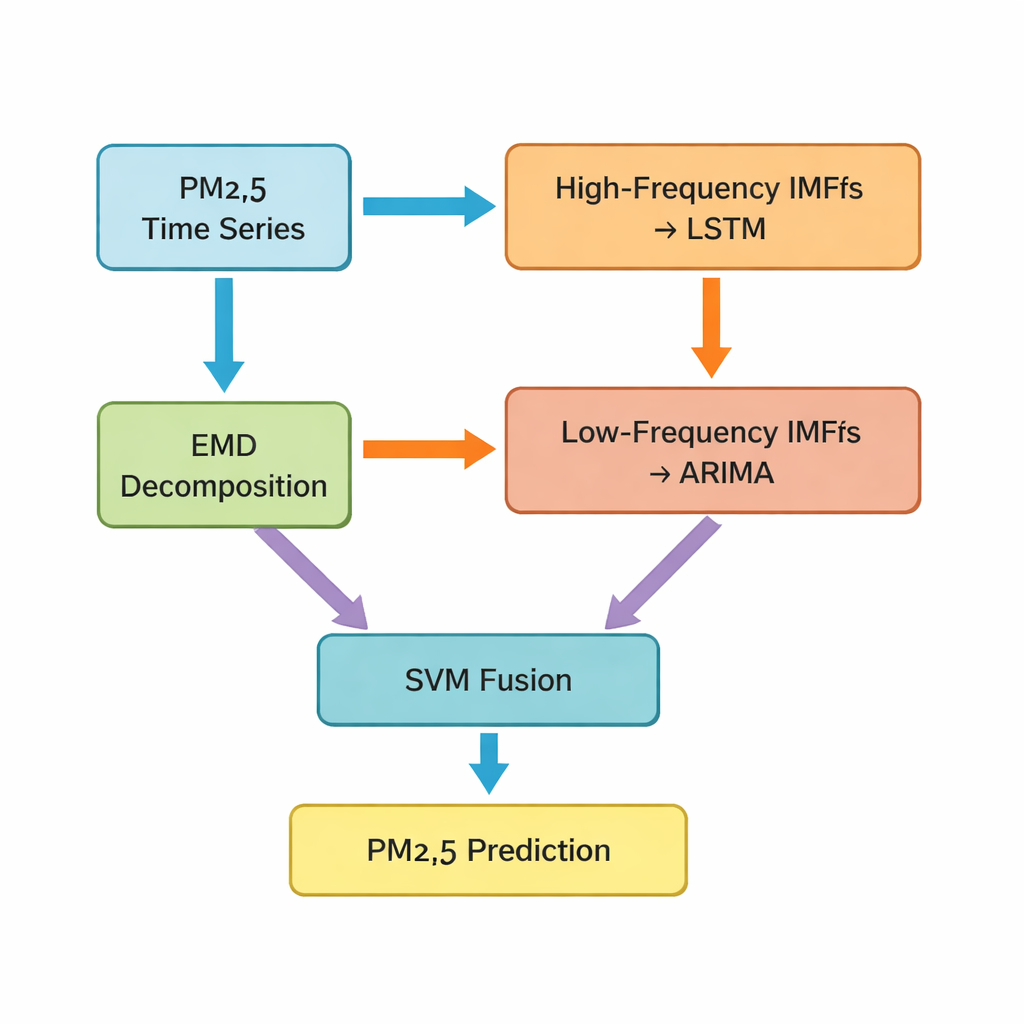
Fondere modelli diversi in un’unica previsione più intelligente
Dopo che LSTM e ARIMA hanno prodotto le loro previsioni parziali, lo studio affronta ancora una sfida: come unire queste previsioni separate in un unico valore finale di PM2.5 per l’ora successiva. Per questo gli autori utilizzano una support vector machine (SVM), un altro metodo di apprendimento automatico che impara come pesare e combinare i due input. In pratica, la SVM funge da arbitro, decidendo quando la visione «veloce» (i pattern ad alta frequenza) ha più peso e quando deve prevalere la visione «lenta» (le tendenze a lungo termine). Il sistema combinato, che gli autori chiamano Hybrid‑EMDHL, viene quindi valutato usando diversi indicatori di performance, tra cui l’errore medio, quanto le previsioni corrispondono ai valori osservati e quanto bene il modello indovina la direzione del cambiamento—se i livelli stanno salendo o scendendo.
Allerte più chiare e una pianificazione migliore
Il modello ibrido supera ciascuno dei suoi componenti principali usati da soli in tutte e sei le città. Non solo riduce gli errori medi e quadratici, ma migliora notevolmente anche la capacità di prevedere correttamente se il PM2.5 aumenterà o diminuirà nell’ora successiva—una caratteristica cruciale per emettere avvisi sanitari tempestivi. In molti casi, l’approccio ibrido dimezza le misure di errore rispetto a un singolo modello a rete neurale, e la sua «accuratezza di direzione» supera 0,69, il che significa che in ben oltre due terzi dei casi di prova predice correttamente la tendenza. Per un lettore non specialista, questo si traduce in previsioni della qualità dell’aria più nitide e più affidabili. Per i pianificatori urbani e le autorità sanitarie, offre uno strumento pratico per supportare azioni mirate e anticipate—come la regolazione delle attività industriali o del traffico—prima che un episodio di inquinamento raggiunga il picco, aiutando a ridurre l’esposizione e a proteggere la vita quotidiana in alcune delle aree urbane più inquinate della Cina.
Citazione: Wang, P., Wu, Q. & Zhang, G. A hybrid prediction model for PM2.5 concentration based on high-frequency and low-frequency IMFs with EMD decomposition. Sci Rep 16, 4969 (2026). https://doi.org/10.1038/s41598-026-35386-9
Parole chiave: Previsione PM2.5, inquinamento atmosferico, Norda Cina, apprendimento automatico, decomposizione di serie temporali