Clear Sky Science · it
Un approccio di deep reinforcement learning per l'analisi del movimento nella danza
Insegnare ai computer a guardare la danza come facciamo noi
Dal balletto all'hip-hop, la danza è piena di sottili variazioni di ritmo e postura che l'occhio umano coglie all'istante—ma che i computer faticano a vedere. Questo studio introduce un nuovo modo per far “guardare” i video di danza all'intelligenza artificiale più come un esperto umano, scorrendo oltre i passi routinari per concentrarsi su brevi momenti rivelatori che definiscono ogni stile. Il risultato è un sistema che riconosce i generi di danza con maggiore accuratezza guardando molto meno video, un potenziale vantaggio per archivi digitali, tecnologia per lo sport e l'intrattenimento.
Perché i video di danza sono difficili per le macchine
A prima vista, addestrare un computer a riconoscere gli stili di danza sembra semplice: inserire video e lasciare che il deep learning trovi i pattern. In realtà, la maggior parte dei sistemi esistenti spreca risorse. I modelli video standard o elaborano ogni fotogramma o campionano clip a intervalli fissi, assumendo che tutti i momenti siano ugualmente importanti. Ma gli stili di danza spesso si distinguono per dettagli minuti—come ruota il piede, quando un partner ruota o il timing di una piroetta—più che per un movimento continuo. Ciò significa che molti fotogrammi sono ripetitivi o privi di informazioni rilevanti, e pose chiave possono cadere tra i punti di campionamento fissi, portando a confusione tra, per esempio, un valzer e un foxtrot.
Un modo più intelligente per scorrere il video
I ricercatori propongono un framework chiamato Reinforcement-based Attentive Temporal Sampling, o RATS, che tratta l'analisi video come una ricerca attiva anziché una visione passiva. Invece di procedere fotogramma per fotogramma, il sistema spezza il video di danza in brevi clip e prima converte ciascuna clip in una descrizione compatta del movimento usando una rete convoluzionale 3D specializzata. Questi riassunti di movimento vengono poi memorizzati. Su questa base, un agente decisionale scorre la sequenza di clip, scegliendo se avanzare con un piccolo salto, un salto più grande, o fermarsi ed emettere una previsione di stile. In pratica, il sistema impara come navigare nel tempo, indugiando sui pattern significativi e saltando tratti meno utili.
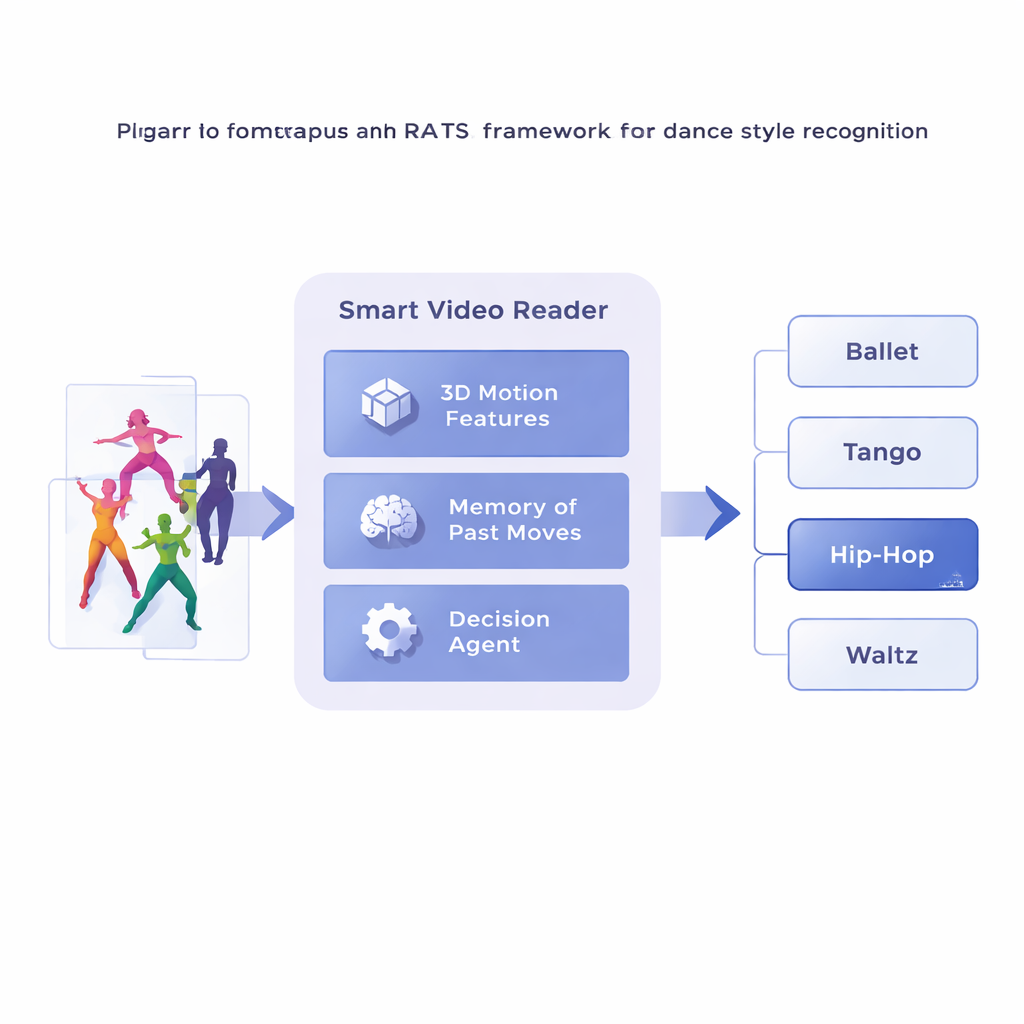
Imparare quando guardare e quando decidere
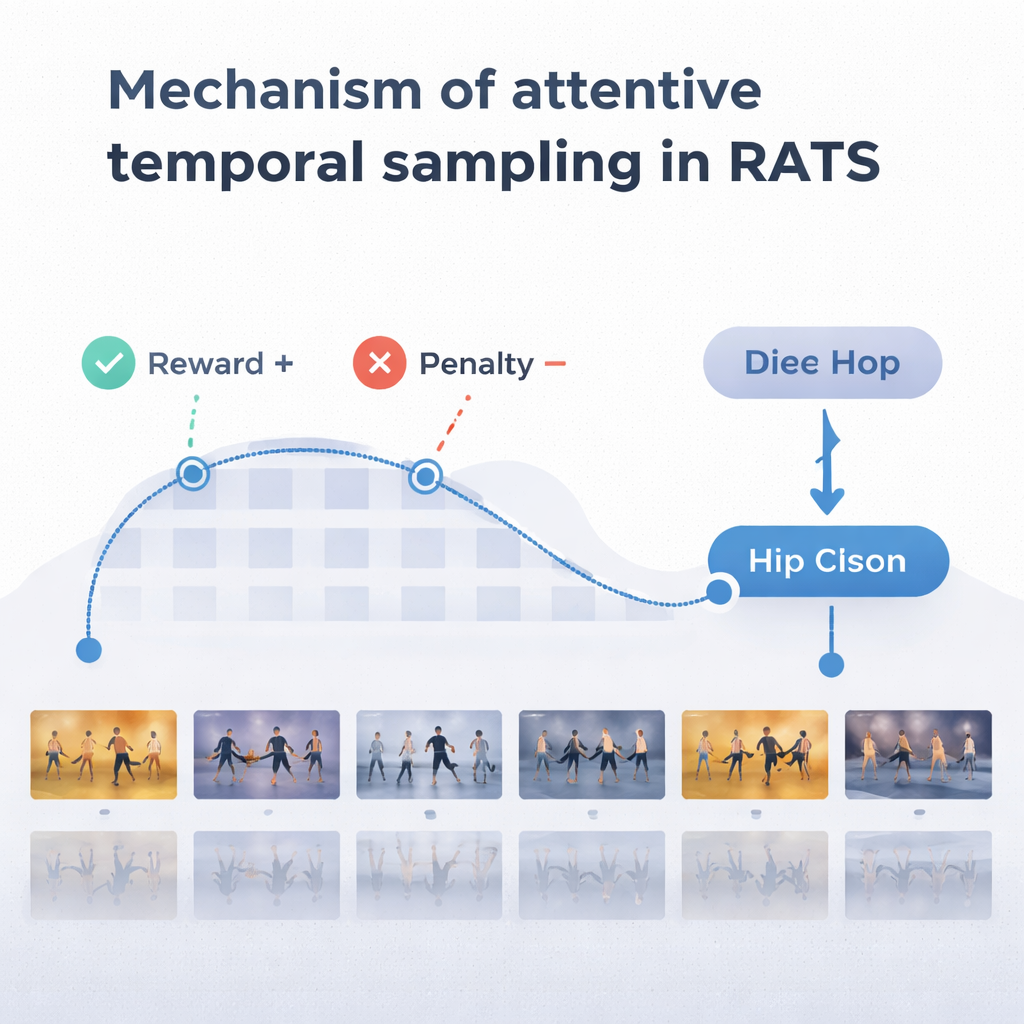
Per prendere decisioni sensate, l'agente si appoggia a una forma di memoria ispirata a come ricordiamo sia i movimenti passati sia quelli emergenti. Una rete ricorrente bidirezionale tiene traccia di ciò che il sistema ha già “visto” e di come le clip correnti si relazionano a quella storia. Ad ogni passo, l'agente pondera tre opzioni: fare un breve balzo per ispezionare dettagli fini come i movimenti dei piedi, compiere un salto più lungo oltre movimenti ripetitivi, o fermarsi e classificare la danza. Il sistema viene addestrato con ricompense e penalità: guadagna un grande punteggio positivo per una decisione corretta, un grande punteggio negativo per una sbagliata, e una piccola penalità ogni volta che salta in avanti. Questo equilibrio incoraggia l'agente a essere sia accurato sia efficiente—ad aspettare finché non ha abbastanza prove, ma senza attraversare l'intero video.
Superare i classificatori di danza convenzionali
Il team ha testato RATS sul dataset Let’s Dance, una raccolta impegnativa di 1.000 video che coprono dieci stili, dal Flamenco e Tango allo Swing e alla Square dance. Rispetto a diversi metodi esistenti, comprese reti profonde standard e altri modelli focalizzati sulla danza, RATS ha ottenuto l'accuratezza più alta—circa il 92%—e il miglior bilancio complessivo tra precisione e richiamo. Si è inoltre dimostrato statisticamente migliore di forti concorrenti, non solo leggermente diverso per caso. Importante, il sistema ha raggiunto questi risultati analizzando, in media, solo circa il 38% dei fotogrammi del video. Il campionamento uniforme ogni pochi fotogrammi era più veloce ma perdeva momenti cruciali e riduceva le prestazioni; elaborare ogni fotogramma era più lento e comunque meno accurato rispetto all'approccio mirato.
Che cosa significa oltre la pista da ballo
Per un non specialista, il messaggio principale è semplice: i computer possono fare un lavoro migliore quando imparano a essere selettivi nella visione. Insegnando a un'IA a concentrarsi sui “momenti d'oro” nel tempo, questo lavoro dimostra che le macchine possono riconoscere movimenti umani complessi con maggiore accuratezza usando meno risorse. Sebbene lo studio si concentri sulla danza, la stessa idea potrebbe aiutare i sistemi a individuare elementi chiave in routine sportive, filmati di sicurezza o in qualsiasi video lungo dove gli eventi importanti sono brevi e sparsi. In altre parole, guardare in modo più intelligente—non guardare di più—potrebbe essere il futuro della comprensione video.
Citazione: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
Parole chiave: riconoscimento della danza, analisi video, deep learning, reinforcement learning, movimento umano