Clear Sky Science · it
Modello cinese di estrazione delle relazioni spaziali integrando caratteristiche semantiche geografiche
Insegnare ai computer a capire dove si trovano i luoghi
Ogni giorno descriviamo localizzazioni con frasi semplici: una città si trova a sud di un fiume, un parco è vicino a un’università, un’autostrada attraversa una provincia. Trasformare questo tipo di linguaggio quotidiano in conoscenza digitale precisa è fondamentale per mappe intelligenti, app di navigazione e ricerche geografiche. Questo articolo presenta un nuovo metodo, chiamato PURE‑CHS‑Attn, che aiuta i computer a leggere testi cinesi e a determinare automaticamente le relazioni spaziali tra i luoghi con maggiore accuratezza rispetto al passato.
Perché il linguaggio spaziale è importante
Le relazioni spaziali sono parole e frasi che indicano come i luoghi sono connessi nello spazio, come “dentro”, “accanto a”, “a nord di” o “a 30 chilometri da”. Esse creano un ponte tra il mondo reale che vediamo sulle mappe e i concetti che usiamo nella mente. Nei sistemi informativi geografici (GIS), queste relazioni costituiscono la base per l’organizzazione, la ricerca e l’analisi dei dati. Sono inoltre centrali in altri ambiti: per esempio, nel combinare immagini satellitari, nel tracciamento di movimenti nei video, nella pianificazione di insediamenti industriali o nello studio di come clima e morfologia influenzino la biodiversità. Poiché gran parte di queste informazioni è scritta in linguaggio naturale, disporre di strumenti affidabili che possano leggere testi ed estrarre automaticamente relazioni spaziali è sempre più importante.
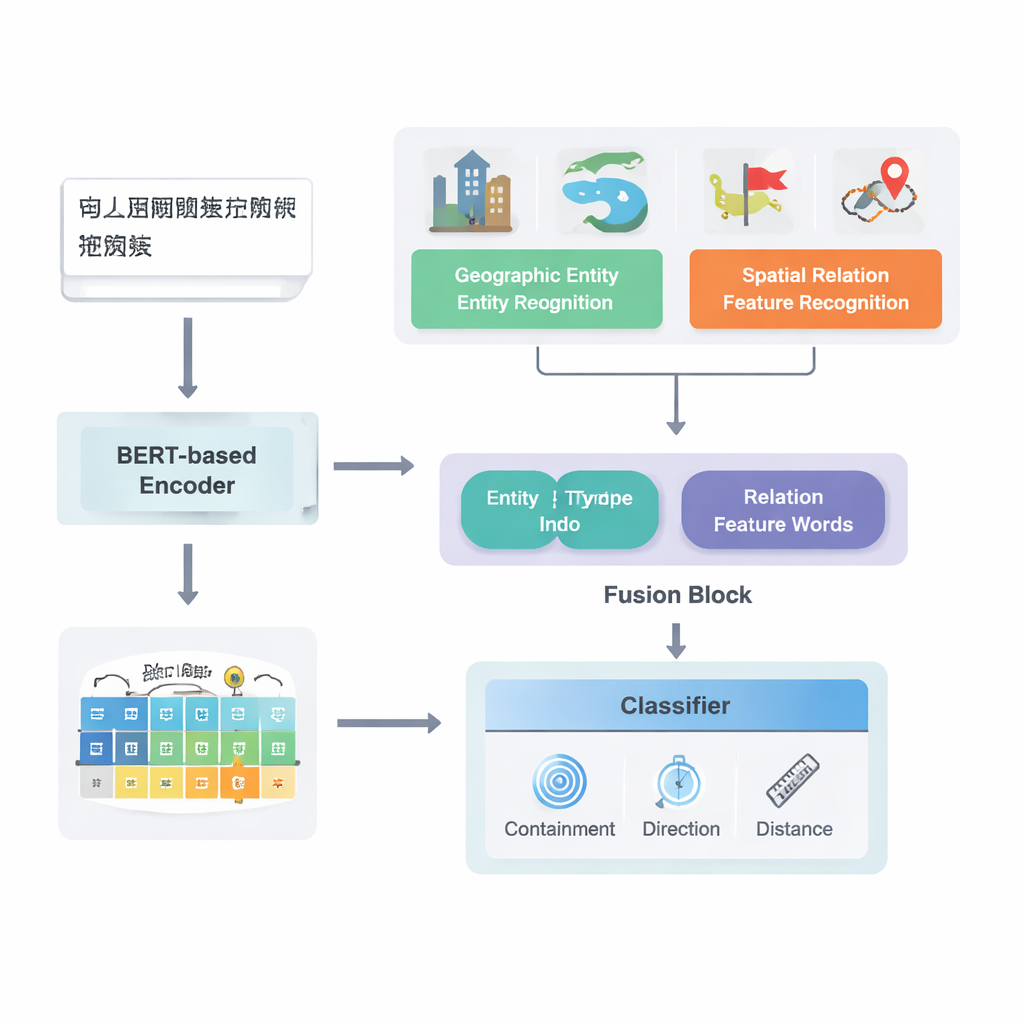
Dal testo grezzo alle relazioni mappate
Gli autori si concentrano sui testi in cinese e si basano su un solido modello di pipeline di deep learning esistente noto come PURE. Il loro modello migliorato, PURE‑CHS‑Attn, opera in più fasi. Per prima cosa scansiona le frasi per individuare entità geografiche come montagne, fiumi, città e regioni amministrative, etichettandole con un tipo (per esempio, superficie terrestre, corpo idrico, struttura pubblica, sito storico o divisione amministrativa). Successivamente rileva le “parole‑segnale” di relazioni spaziali come “confina”, “attraversa”, “a sud di” o “vicino a”, che indicano come due luoghi sono correlati. Un potente modello linguistico, BERT‑wwm‑ext, trasforma i caratteri di ogni frase in vettori numerici che catturano il loro significato e contesto. Questi vettori alimentano componenti separate che riconoscono entità e parole di relazione e quindi trasferiscono i risultati a un modulo di fusione.
Fondere la conoscenza umana con l’apprendimento automatico
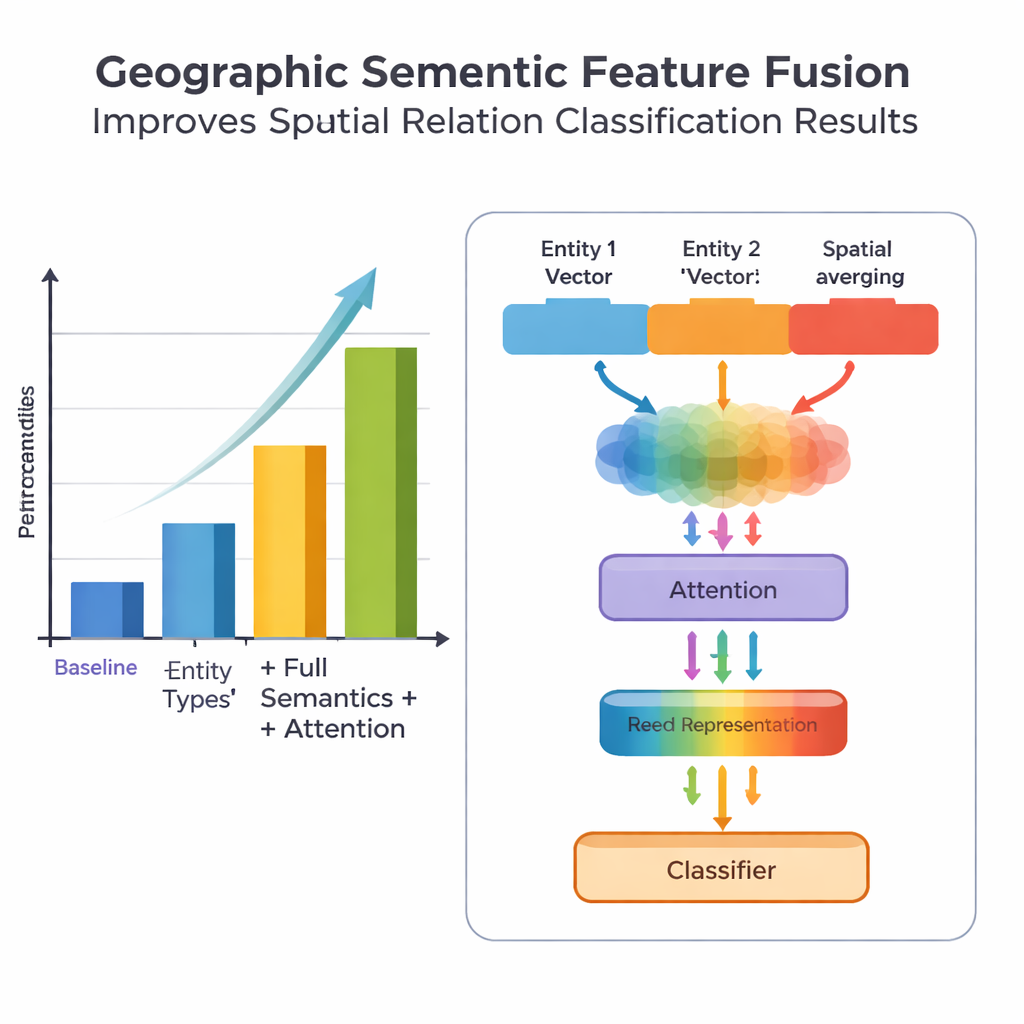
Una novità chiave del lavoro riguarda il modo in cui fonde la conoscenza geografica con i pattern testuali appresi. Invece di trattare ogni parola allo stesso modo, il modello sfrutta due tipi di informazioni semantiche che gli umani usano naturalmente: il tipo di ciascuna entità geografica e le parole‑segnale spaziali specifiche che le collegano. Il modulo di fusione combina prima i vettori delle due entità usando pesi che dipendono da quanto spesso diversi tipi di luoghi (per esempio due divisioni amministrative rispetto a un fiume e una contea) partecipano a diversi tipi di relazione. Poi integra i vettori delle parole‑segnale spaziali. Oltre a questa “fusione di base”, gli autori aggiungono un meccanismo di attenzione che permette al modello di concentrarsi dinamicamente sulle parti più informative della combinazione entità‑parola. La rappresentazione finale fusa viene passata a un classificatore, il quale può assegnare uno o più tipi di relazione—topologiche (come contenimento o adiacenza), direzionali (nord, sud, ecc.) o basate sulla distanza—tra ogni coppia di luoghi nella frase.
Mettere il modello alla prova
Per valutare il loro approccio, il team ha assemblato e annotato con cura un dataset tratto dall’Encyclopedia of China: Chinese Geography, contenente 1381 frasi e 368 coppie di relazioni spaziali. Hanno confrontato diverse versioni del modello: un baseline che usa solo informazioni di posizione grossolane, una versione con tipi di entità più dettagliati, una versione che aggiunge anche le parole‑segnale spaziali, e il loro modello completo PURE‑CHS‑Attn con il nuovo design di fusione e attenzione. Sulla base di metriche standard di precisione, richiamo e F1, PURE‑CHS‑Attn ha migliorato le prestazioni di circa il 7% in precisione, il 6,5% in richiamo e il 6,7% in F1 rispetto al baseline. Si è dimostrato particolarmente efficace nel riconoscere relazioni topologiche e direzionali, e ha gestito meglio dei modelli più semplici tipi di relazione rari o “few‑shot”. Confrontato con tre recenti sistemi all’avanguardia, incluso uno basato su grandi modelli linguistici, PURE‑CHS‑Attn si è classificato al secondo posto a breve distanza pur rimanendo molto più leggero e facile da distribuire.
Sfide e direzioni future
Nonostante questi progressi, il modello fatica ancora con le relazioni di distanza, soprattutto quando esistono solo pochi esempi di addestramento. Gli autori mostrano che il loro dataset contiene pochissimi casi di questo tipo, il che limita ciò che qualsiasi metodo che richiede molti dati può apprendere. Notano anche che una media ingenua di molte parole‑segnale spaziali in una frase può introdurre rumore, che il loro meccanismo di attenzione aiuta ma non risolve completamente. Guardando avanti, suggeriscono due percorsi promettenti: espandere e bilanciare i dati di addestramento tramite data augmentation, e combinare la loro fusione semantica geografica con tecniche derivate dai grandi modelli linguistici e dall’apprendimento basato su prompt per migliorare ulteriormente le prestazioni in scenari poveri di dati mantenendo il sistema efficiente.
Cosa significa questo per la mappatura quotidiana
In termini pratici, questa ricerca insegna ai computer a leggere le descrizioni spaziali in cinese in modo più simile agli esseri umani, prestando attenzione ai tipi di luoghi menzionati e a come sono formulate esattamente le loro relazioni. Il modello PURE‑CHS‑Attn dimostra che mescolare conoscenza geografica strutturata con il moderno deep learning porta a un’estrazione più accurata e robusta del “chi è dove, rispetto a cosa” dal testo. Ciò apre la strada a sistemi GIS più intelligenti e automatizzati, grafi di conoscenza geografica più ricchi e strumenti migliori per esplorare come lo spazio viene descritto nella scienza, nelle politiche e nella comunicazione quotidiana.
Citazione: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
Parole chiave: estrazione di relazioni spaziali, AI geospaziale, semantica geografica, text mining cinese, automazione GIS