Clear Sky Science · it
Approccio di machine learning per l'identificazione delle varietà di grano usando immagini di singoli semi
Perché una selezione dei semi più intelligente è importante
Per gli agricoltori e le aziende sementiere, distinguere una varietà di grano da un'altra è cruciale. Seminare il tipo sbagliato può significare rese inferiori, minore resistenza alle malattie e colture non adatte al suolo o al clima locale. Eppure, a occhio nudo, le diverse varietà di grano appaiono quasi identiche. Questo studio esplora come l'intelligenza artificiale e le foto digitali di singoli semi possano distinguere in modo affidabile varietà molto affini, aprendo la strada a controlli della qualità dei semi più rapidi, economici e oggettivi.
Dall'occhio esperto ai controlli con la fotocamera
Oggi molti sistemi di ispezione dei semi dipendono ancora da esperti umani che giudicano visivamente varietà e purezza. Questo processo è lento, costoso e soggetto a discrepanze, soprattutto perché molte cultivar di grano differiscono solo per sottili variazioni di forma o di pattern superficiale. Gli autori hanno voluto sostituire questo approccio soggettivo con un sistema automatizzato che utilizza immagini di singoli granelli scattate in una piccola scatola a illuminazione controllata. Standardizzando accuratamente illuminazione, distanza e colore dello sfondo, hanno creato un archivio visivo pulito di sei comuni varietà di grano iraniano, generando decine di migliaia di foto di semi per addestrare e testare i modelli computazionali.
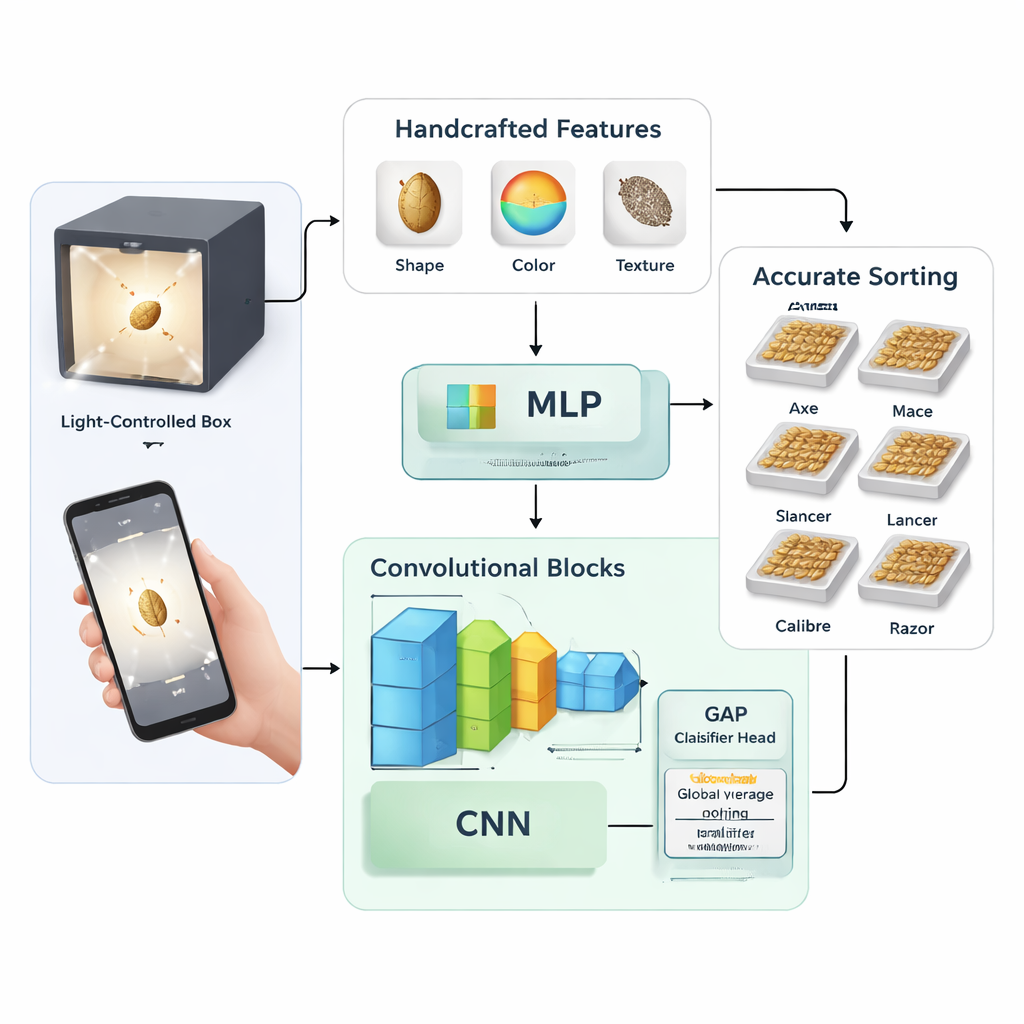
Due modi per insegnare a una macchina a vedere i semi
Lo studio confronta due strategie generali per insegnare a una macchina a riconoscere le varietà di grano. Nella prima, i ricercatori hanno ricavato manualmente 58 misure numeriche da ogni immagine del seme, incluse caratteristiche di base della forma (come lunghezza e area), statistiche di colore su diversi spazi cromatici e schemi di texture. Hanno poi usato un'analisi in componenti principali per condensare queste misure in 27 caratteristiche chiave, che sono state immesse in una rete neurale tradizionale chiamata perceptrone multistrato. Nella seconda strategia, hanno saltato la progettazione manuale delle caratteristiche e hanno addestrato reti neurali convoluzionali — modelli di IA focalizzati sulle immagini — per apprendere direttamente dai pixel grezzi pattern utili.
Costruire un modello deep-learning snello ma potente
L'approccio deep-learning è stato testato in diverse varianti. Gli autori hanno progettato una propria rete relativamente piccola con due-quattro blocchi convoluzionali impilati e hanno sperimentato varie impostazioni di addestramento, come tassi di apprendimento, livelli di dropout e dimensioni dei batch. Hanno inoltre confrontato due modi di completare la rete: uno strato “fully connected” classico contro un metodo più compatto chiamato global average pooling, che sostituisce ampi strati densi con un semplice passo di media prima della classificazione finale. Per confronto, hanno messo a punto due architetture pesanti e ampiamente usate — Inception-ResNet-v2 ed EfficientNet-B4 — sullo stesso dataset di grano per vedere come un modello piccolo e dedicato si confronta con reti profonde e generali.
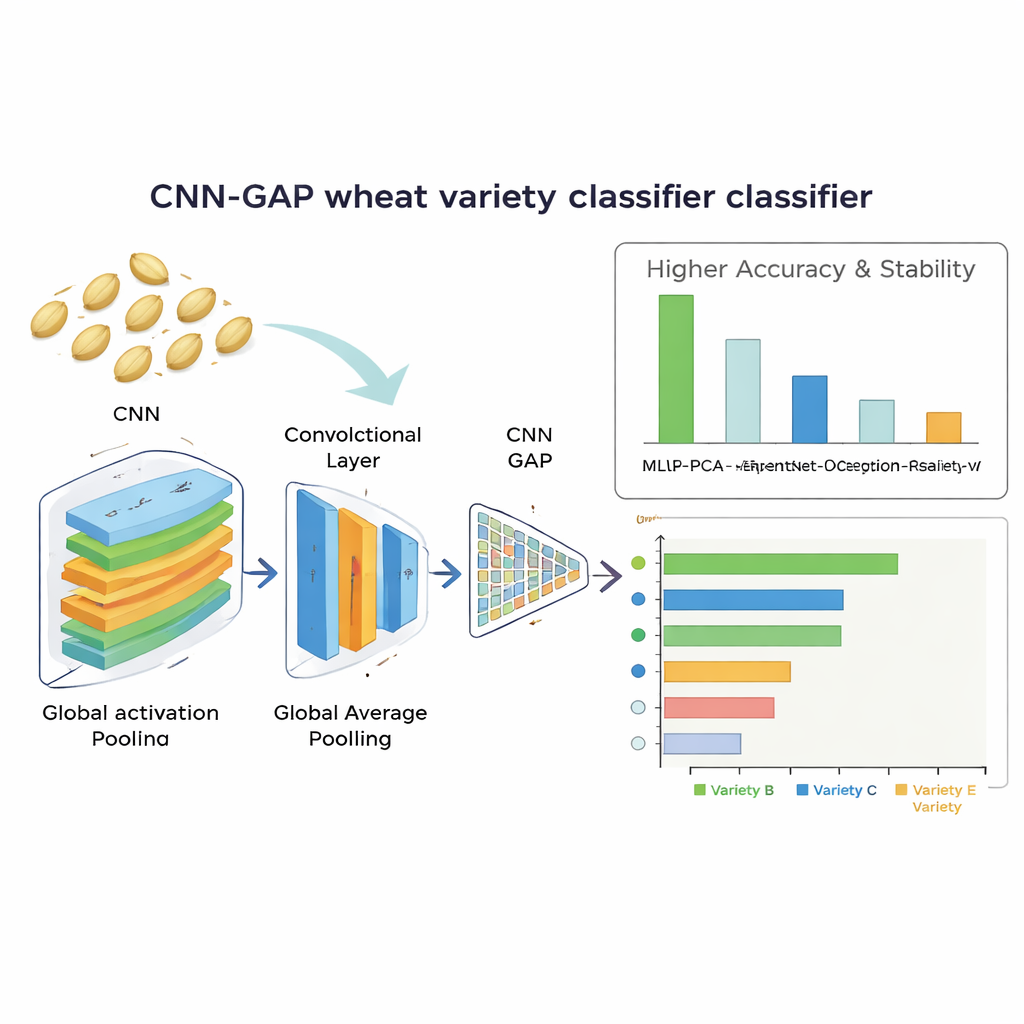
Quanto bene il sistema legge il granello
Il migliore è risultato essere la rete convoluzionale personalizzata che utilizzava il global average pooling. Ha identificato correttamente le varietà di grano in circa il 92% dei casi e ha mostrato risultati molto stabili tra ripetute sessioni di addestramento. Questo modello non solo ha superato le grandi reti pre-addestrate, ma ha anche battuto l'approccio basato su caratteristiche costruite a mano, che aveva raggiunto circa l'86% di accuratezza dopo la riduzione di dimensionalità. L'analisi delle confusioni ha mostrato che il modello più leggero era particolarmente efficace nel separare varietà molto simili, mentre i modelli profondi con transfer learning tendevano a sovradattarsi sul dataset limitato. Importante, la rete vincente era efficiente: processava ogni immagine di seme in circa 13,6 millisecondi e conteneva solo circa 2,1 milioni di parametri regolabili, rendendola realistica per l'uso in apparecchiature di selezione in tempo reale a basso costo.
Limiti, uso nel mondo reale e prospettive
Quando lo stesso modello è stato testato su una coltura completamente diversa — semi di ceci — la sua accuratezza è crollata, evidenziando che un sistema tarato sulle differenze fini tra cariossidi di grano non si generalizza automaticamente ad altre specie. Allo stesso modo, poiché tutte le immagini di addestramento provengono da una camera attentamente controllata, le prestazioni potrebbero diminuire in condizioni di illuminazione variabile sul campo o con semi parzialmente nascosti. Nonostante ciò, il lavoro dimostra che un modello deep-learning compatto e ben progettato, alimentato con immagini standardizzate di singoli semi, può distinguere in modo affidabile varietà di grano quasi indistinguibili a occhio nudo. Con dati di addestramento più ampi e condizioni di imaging più varie, sistemi simili potrebbero diventare strumenti pratici per la certificazione automatizzata dei semi, aiutando gli agricoltori a ottenere lotti di semi più puri e raccolti più prevedibili.
Citazione: Bagherpour, H., Shamohammadi, S. Machine learning approach for wheat variety identification using single-seed imaging. Sci Rep 16, 6472 (2026). https://doi.org/10.1038/s41598-026-35252-8
Parole chiave: semi di grano, deep learning, classificazione basata su immagini, qualità dei semi, agricoltura di precisione