Clear Sky Science · it
Rilevamento efficiente di abstract scientifici generati da IA con un trasformatore leggero
Perché è importante individuare testi scientifici scritti da IA
Con il migliorare delle capacità delle intelligenze artificiali nella scrittura, oggi possono redigere sintesi scientifiche che risultano quasi indistinguibili da quelle umane. Questo solleva questioni complesse: come possono riviste, università e lettori accertarsi che un abstract rifletta veramente il lavoro di uno scienziato e non l’invenzione di una macchina? Questo articolo affronta il problema costruendo uno strumento rapido e compatto che può segnalare con grande affidabilità gli abstract scientifici generati da IA, offrendo una difesa pratica per l’integrità accademica.
Costruire un banco di prova di abstract reali e sintetici
Per misurare e migliorare il rilevamento di testo IA, gli autori hanno prima bisogno di dati affidabili. Hanno raccolto 5.000 abstract scientifici dal server di preprint online arXiv, coprendo cinque aree: visione artificiale, elaborazione del segnale, biologia quantitativa, fisica e altri argomenti di informatica. Per ogni abstract scritto da un umano, hanno usato un grande modello linguistico per generare una versione IA a partire dal titolo del paper, controllando accuratamente la presenza di testi quasi duplicati e rimuovendo indizi ovvi come indirizzi web o frammenti di codice. Hanno inoltre fatto in modo che i testi IA e umani avessero lunghezze simili, così che il rilevatore non potesse basarsi su statistiche grossolane come il numero di parole.
Un modello compatto tarato per il mondo reale
Invece di usare un modello enorme e costoso, i ricercatori hanno scelto un sistema più piccolo noto come DistilBERT, una versione snellita di un popolare modello linguistico. Lo hanno messo a punto per decidere, per ogni abstract, se fosse stato scritto da una persona o generato da IA. Il modello legge fino a 256 token—più o meno qualche paragrafo—e produce un punteggio tra zero e uno, interpretato come la probabilità che il testo sia stato scritto da una macchina. Addestramento e valutazione hanno seguito un protocollo rigoroso: i dati sono stati suddivisi in insiemi di training, validazione e test senza sovrapposizioni, e il team ha riportato non solo l’accuratezza ma anche il comportamento del modello quando il tasso di falsi positivi è mantenuto molto basso, un regime che conta quando si accusano autori reali di aver usato IA.
Quanto bene funziona il rilevatore
Negli abstract di visione artificiale, il banco di prova principale, il rilevatore si è dimostrato notevolmente accurato. Ha etichettato correttamente 499 su 500 testi scritti da IA e 495 su 500 testi umani, raggiungendo circa il 99,4% di accuratezza e un punteggio quasi perfetto su una curva di performance standard. Quando gli autori hanno imposto al sistema di commettere al massimo un’accusa errata ogni cento casi, ha comunque intercettato circa il 90% dei testi IA; con una tolleranza leggermente più alta di cinque falsi allarmi su cento, ne ha intercettato circa il 97%. Rispetto a una serie di alternative—inclusi strumenti statistici più semplici e altri modelli transformer—il rilevatore compatto è risultato costantemente superiore, specialmente negli scenari più esigenti.
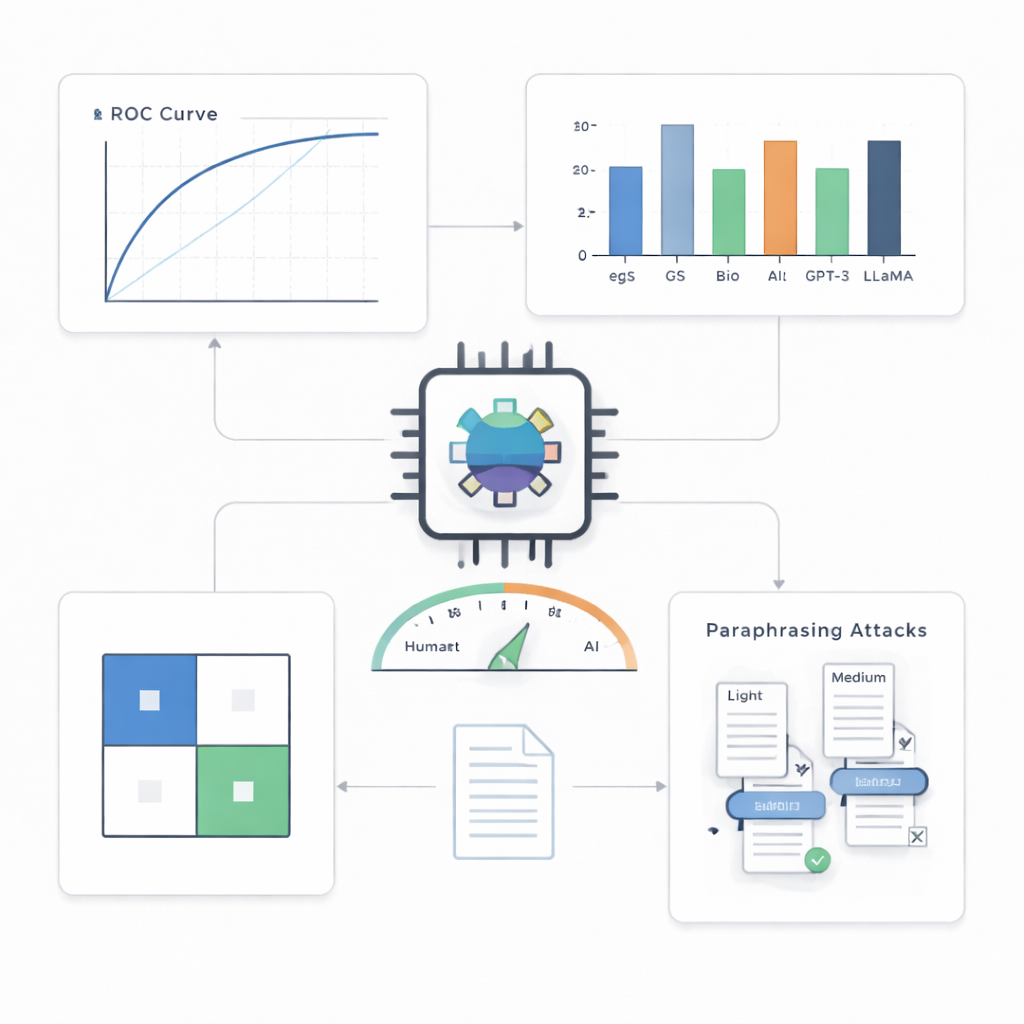
Oltre un campo, un modello e semplici stratagemmi
Una domanda chiave è se un tale rilevatore possa gestire stili di scrittura e sistemi IA mai incontrati prima. Gli autori lo hanno testato su abstract di altri campi scientifici e su testi prodotti da diversi modelli linguistici avanzati. Attraverso i domini, le prestazioni sono rimaste solide, con solo cali modesti, suggerendo che il sistema cattura pattern generali della scrittura IA più che particolarità di un’area tematica. Contro modelli IA non visti durante l’allenamento, si è comportato comunque bene, seppure meno perfettamente rispetto al contesto di origine. La sfida più dura è venuta dagli attacchi di parafrasi: quando un’altra IA riscriveva gli abstract generati da macchina per farli suonare diversi pur mantenendo il significato, la rilevazione diventava visibilmente più difficile. Con riscritture a forza media, la quota di testi IA che sfuggivano è salita a quasi il 30%, rivelando che anche rilevatori sofisticati possono essere ingannati da un’offuscazione deliberata.
Cosa significa per la scienza e le sue salvaguardie
Lo studio mostra che, per ora, gli abstract scientifici scritti da IA lasciano ancora tracce sottili che un modello ben progettato può cogliere, anche quando quel modello è abbastanza piccolo da girare su hardware modesto. Questo rende fattibile per editori, conferenze e università esaminare grandi volumi di sottomissioni senza costi di calcolo enormi. Allo stesso tempo, la vulnerabilità alle parafrasi sottolinea che tali strumenti non sono una soluzione definitiva. Gli autori sostengono che il rilevamento del testo IA dovrebbe essere combinato con altre salvaguardie—come il giudizio editoriale, controlli di plagio e requisiti di trasparenza—per proteggere l’affidabilità della comunicazione scientifica man mano che i sistemi IA continuano a migliorare.
Citazione: Zhang, C., Zhou, W. Efficient detection of AI-generated scientific abstracts with a lightweight transformer. Sci Rep 16, 4975 (2026). https://doi.org/10.1038/s41598-026-35203-3
Parole chiave: rilevamento testo IA, abstract scientifici, integrità accademica, grandi modelli linguistici, testo generato da macchina