Clear Sky Science · it
Primato dell’ingegneria delle feature rispetto alla complessità architetturale per la previsione della domanda intermittente
Perché prevedere vendite rare è importante
Dietro ogni officina o magazzino ricambi si nasconde un problema silenzioso: quanti pezzi di ricambio a lenta rotazione tenere a scaffale? Questi articoli si vendono raramente e in modo imprevedibile, ma devono essere disponibili quando un veicolo si guasta. Ordinare troppo significa denaro bloccato in scorte polverose; ordinare troppo poco significa clienti in attesa mentre i ricambi vengono fatti arrivare d’urgenza. Questo articolo affronta quel problema quotidiano ma costoso ponendo una domanda semplice: è meglio usare modelli predittivi sempre più complessi, oppure alimentare i modelli esistenti con segnali più intelligenti e progettati con cura a partire dai dati?
Da lunghi periodi di nulla a picchi improvvisi
In molte catene di approvvigionamento, specialmente per i ricambi automobilistici, la domanda non è costante come per latte o pane. Piuttosto, ci sono lunghi periodi di mesi con vendite nulle, interrotti da ordini improvvisi di poche unità. Gli autori analizzano più di 56.000 combinazioni concessionario–pezzo, per un totale di circa 1,4 milioni di record mensili, e trovano che la maggior parte delle serie è estremamente scarna: in media ci sono molti mesi a zero per ogni mese con una vendita, e le dimensioni degli ordini oscillano fortemente. Metodi statistici tradizionali come l’approccio di Croston e le sue rifiniture sono stati pensati per questo tipo di domanda “on–off” e forniscono previsioni stabili e interpretabili, ma trattano ogni pezzo in isolamento e non possono facilmente sfruttare informazioni aggiuntive come prezzi o attributi di prodotto. I moderni sistemi di machine learning possono, in linea di principio, usare tutte queste informazioni, ma tendono a faticare quando i dati sono per lo più zeri e solo occasionalmente informativi.
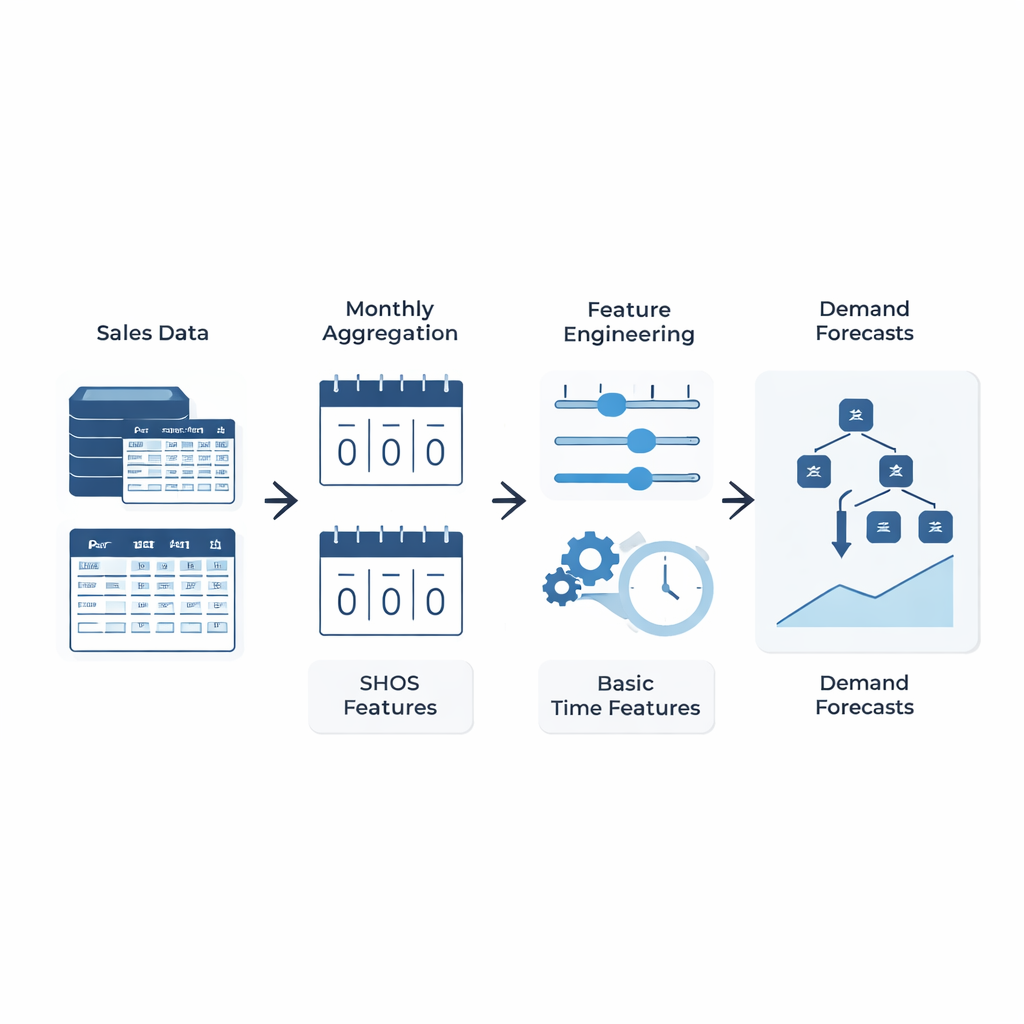
Un’idea semplice: insegnare al modello ciò che conta davvero
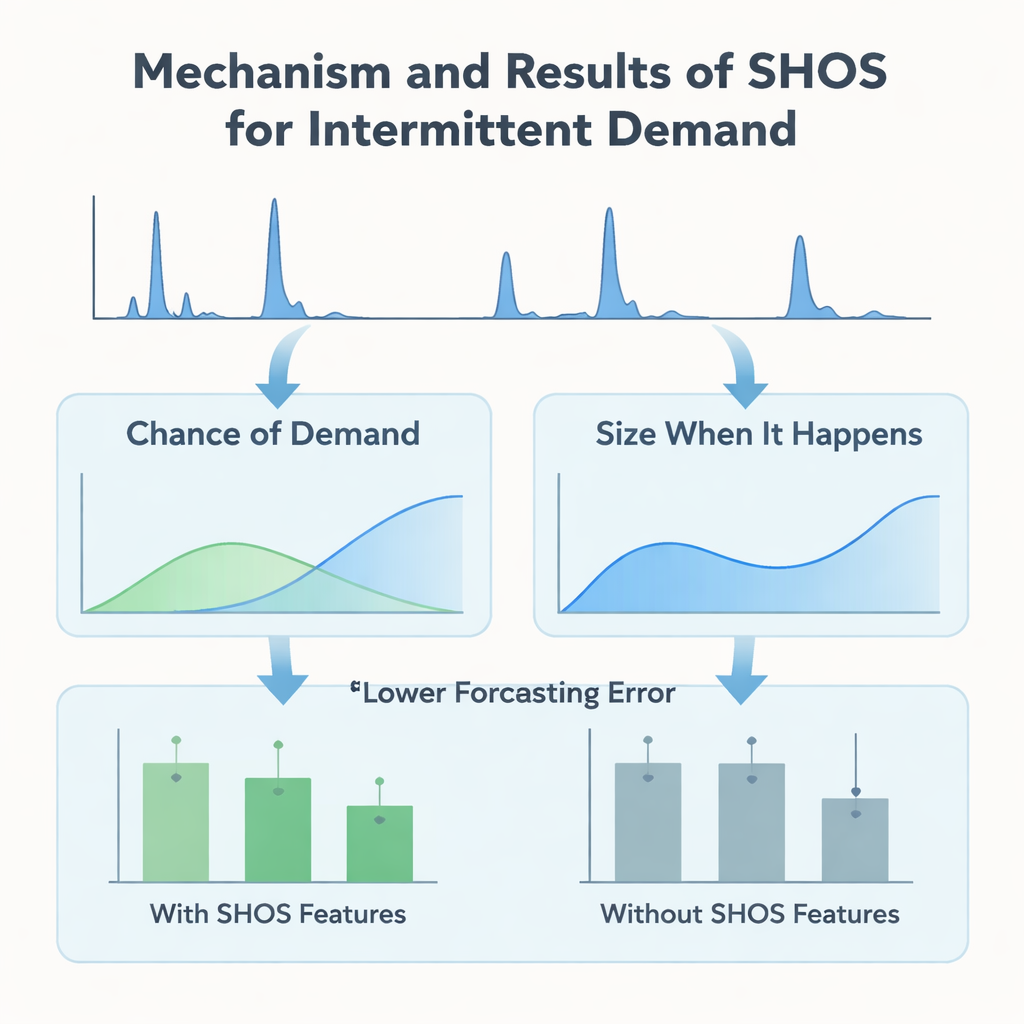
Invece di progettare architetture di machine learning sempre più intricate, gli autori si concentrano su ciò che viene fornito al modello. Introducono il framework Smoothed Hybrid Occurrence–Size (SHOS), una routine statistica leggera che scorre ogni storia di domanda. Ogni mese, SHOS produce due numeri: la probabilità stimata che si verifichi domanda il mese successivo, e la dimensione tipica di quella domanda se avviene. Lo fa lisciando con cura zeri e non zeri passati, adattando il suo comportamento per serie molto scarse e reagendo più rapidamente quando la domanda ritorna improvvisamente dopo una lunga pausa. Fondamentalmente, SHOS non è il modello finale di previsione. I suoi output diventano feature aggiuntive per algoritmi standard di machine learning, insieme a elementi semplici come vendite recenti, medie mobili e dettagli statici del prodotto.
Mettere la qualità delle feature davanti alla complessità del modello
Per verificare se questo “pre-processing” statistico aiuta davvero, i ricercatori costruiscono un esperimento controllato. Confrontano una gamma di modelli popolari—gradient-boosted tree, random forest e metodi lineari—con e senza le feature SHOS, tutti addestrati sullo stesso pannello mensile con zeri e valutati usando uno schema rigoroso a finestre mobili che imita il dispiegamento reale. Testano anche modelli a due stadi più elaborati, i cosiddetti modelli “hurdle”, che prevedono separatamente se la domanda si verificherà e quanto sarà grande. Su 11 finestre di validazione, l’aggiunta delle feature SHOS quasi dimezza l’errore medio di previsione per gli articoli altamente intermittenti e riduce una metrica chiave di business, l’errore percentuale assoluto medio pesato, di oltre il 40%. Sorprendentemente, le architetture a due stadi, pur essendo più complesse e su misura per questo tipo di dati, non superano un singolo regressore semplice che si limita ad assorbire i segnali SHOS.
Capire come il modello prende le sue decisioni
Il team va oltre l’accuratezza complessiva e indaga come i modelli utilizzano effettivamente le informazioni a disposizione. Usando SHAP, uno strumento standard per interpretare le previsioni di machine learning, mostrano che le feature basate su SHOS—“probabilità di domanda” e “dimensione quando avviene”—figurano costantemente tra gli input più influenti. Durante lunghi periodi di domanda nulla, una bassa probabilità SHOS spinge le previsioni verso zero, evitando accumuli di scorte spurie. Quando compare un’ondata di domanda dopo un periodo di siccità, un aggiustamento per recency in SHOS aumenta rapidamente le stime di probabilità e dimensione, permettendo al modello di rispondere senza reagire eccessivamente a un singolo picco. Questi comportamenti si osservano sia nel semplice modello a stadio unico sia nelle versioni hurdle più complesse, sottolineando che il guadagno principale deriva dalla qualità dei segnali, non da stratagemmi architetturali.
Cosa significa per le decisioni quotidiane di inventario
Per i professionisti che cercano di mantenere i pezzi giusti a scaffale, il messaggio è pratico e rassicurante. Lo studio mostra che feature progettate con cura e fondate su basi statistiche possono offrire miglioramenti rilevanti nella previsione di vendite rare e irregolari senza ricorrere a soluzioni fragili e difficili da mantenere. Un albero potenziato (gradient-boosted tree) modesto e ben tarato dotato di feature SHOS batte o eguaglia pipeline più elaborate pur restando più semplice da distribuire e monitorare su decine di migliaia di articoli. In termini semplici, fornire al sistema di previsione riassunti migliori su quanto spesso e quanto i clienti è probabile che ordinino può contare più dell’aggiornamento all’algoritmo più recente e complesso. Questo accento su blocchi semplici e interpretabili rende l’approccio attraente per catene di approvvigionamento su larga scala e suggerisce che strategie simili incentrate sulle feature potrebbero essere vantaggiose anche in altri settori che affrontano domanda intermittente.
Citazione: Nathan, B.S., Aravinth, P.M., Reddy, B.V.S. et al. Primacy of feature engineering over architectural complexity for intermittent demand forecasting. Sci Rep 16, 4792 (2026). https://doi.org/10.1038/s41598-026-35197-y
Parole chiave: domanda intermittente, previsione ricambi, feature engineering, analisi della catena di approvvigionamento, apprendimento automatico