Clear Sky Science · it
Modelli di deep learning compatti per l’istopatologia del colon: sfide di prestazione e generalizzazione
Perché questa ricerca è importante per pazienti e medici
Il cancro del colon è uno dei tumori più letali al mondo, eppure la sua diagnosi dipende ancora dall’ispezione dettagliata di immagini al microscopio da parte di specialisti, un compito lento e soggetto a disaccordi. Questo studio esplora se modelli di intelligenza artificiale (IA) molto piccoli ed efficienti possano aiutare a segnalare tessuto colonico canceroso con accuratezza sufficiente per essere utili nelle cliniche quotidiane, anche in quelle con risorse di calcolo limitate. Lo studio mette inoltre in luce una debolezza nascosta: modelli che sembrano quasi perfetti durante lo sviluppo possono comunque fallire in modo drastico su dati reali e nuovi.
Insegnare ai computer a leggere le immagini al microscopio
Quando si esegue una biopsia del colon, i patologi esaminano fette sottili e colorate di tessuto al microscopio. Il tessuto canceroso mostra ghiandole deformate, forme cellulari irregolari e infiltrazione nelle strutture circostanti, mentre il tessuto sano presenta pattern ordinati e regolari. Gli autori hanno utilizzato una raccolta pubblica di 24.000 immagini digitali di queste fette, equamente divise tra adenocarcinoma del colon e tessuto benigno. Hanno ridimensionato tutte le immagini a un formato standard ridotto e applicato modifiche realistiche—piccole rotazioni, ribaltamenti, zoom e leggere variazioni di colore—per mimare la naturale variabilità nel taglio, nella colorazione e nella scansione dei vetrini. Questa preparazione attenta aiuta i modelli di IA a concentrarsi sui pattern tissutali significativi anziché su dettagli superficiali come l’orientamento o la luminosità esatti.
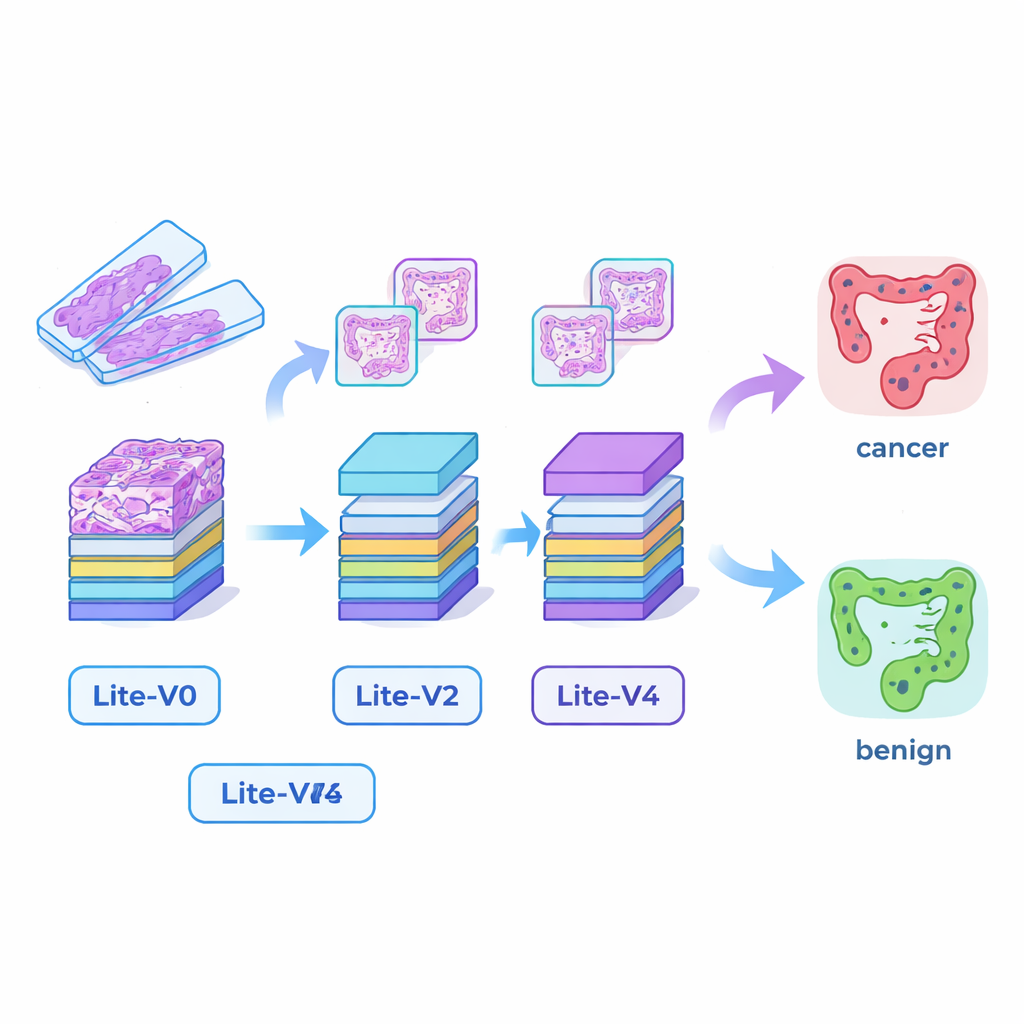
Costruire “occhi” IA piccoli ma capaci
Molti sistemi di IA medica di successo si basano su modelli di deep learning molto grandi che richiedono potenti schede grafiche e molta memoria, rendendoli difficili da distribuire in ospedali più piccoli o al letto del paziente. Per colmare questo divario, i ricercatori hanno progettato quattro reti neurali convoluzionali compatte—Lite‑V0, Lite‑V1, Lite‑V2 e Lite‑V4. Ognuna analizza le stesse porzioni di immagine in ingresso, ma differisce nel numero di layer e filtri usati per rilevare caratteristiche visive come bordi, texture e forme ghiandolari. Tutte e quattro condividono un design semplice e trasparente: blocchi ripetuti di convoluzione standard, normalizzazione e pooling, seguiti da una piccola “testa decisionale” che fornisce la probabilità di tessuto canceroso o benigno. L’obiettivo era verificare quanta accuratezza si potesse ottenere con modelli abbastanza piccoli da poter essere eseguiti agevolmente su hardware clinico di base.
Risultati impressionanti in laboratorio
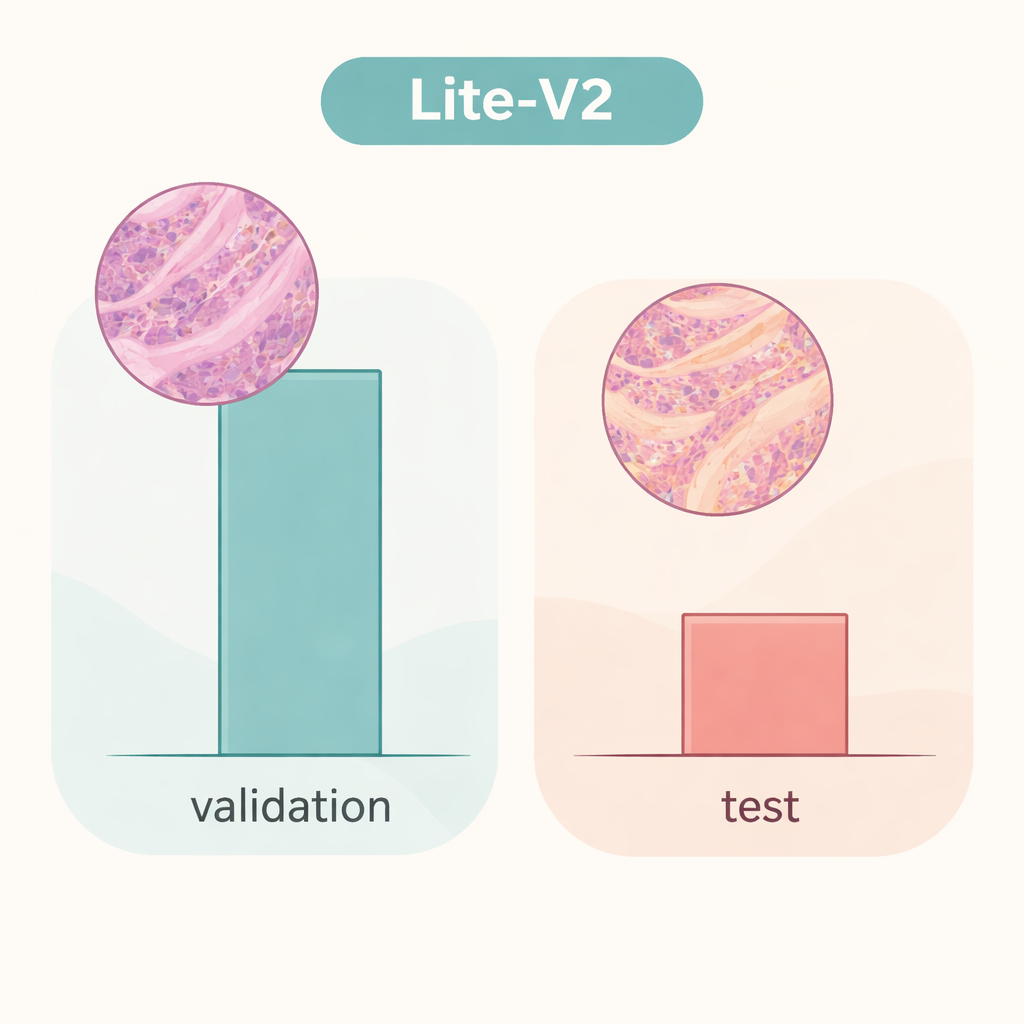
Il team ha addestrato e confrontato tutti e quattro i modelli su una suddivisione fissa del dataset, usando metriche ampiamente accettate: accuratezza, F1‑score bilanciato che pesa gli errori di entrambe le classi allo stesso modo, matrici di confusione e grafici diagnostici come curve ROC e precision–recall. Un modello di dimensioni medie, Lite‑V2, si è rivelato il più performante. Pur essendo di circa 1,5 megabyte e con all’incirca 128.000 parametri allenabili, ha ottenuto prestazioni quasi perfette sul set di validazione interno, con un F1‑score macro intorno a 0,999 e sensibilità e specificità quasi perfette. In altre parole, in questo ambiente accuratamente preparato Lite‑V2 riusciva quasi sempre a distinguere tessuto canceroso da tessuto benigno del colon, rimanendo al contempo rapido e leggero abbastanza per l’uso su computer modesti.
Quando la variabilità del mondo reale rompe l’incantesimo
Tuttavia, la situazione cambia drasticamente quando lo stesso modello Lite‑V2 viene testato su un set indipendente di immagini che differiscono in modo sottile, come accade passando a vetrini provenienti da un altro laboratorio—quello che i ricercatori chiamano “domain shift”. Su questo set di test non visto, l’accuratezza complessiva è scesa intorno al 50% e l’F1‑score bilanciato è calato a circa 0,33. Il modello ha continuato a riconoscere molti campioni cancerosi ma ha avuto grandi difficoltà con il tessuto benigno, etichettandone una larga parte come maligna. Ciò dimostra che la rete aveva appreso dettagli strettamente legati alla fonte originale dei dati—come lo stile di colorazione o le caratteristiche dello scanner—invece di firme robuste e trasferibili della malattia. Il lavoro evidenzia come risultati brillanti sulla validazione interna possano dare un falso senso di sicurezza se i modelli non vengono messi alla prova con dati veramente diversi.
Cosa significa questo per gli strumenti diagnostici IA futuri
Per il lettore generale, la conclusione è duplice. Primo, i sistemi IA compatti possono davvero raggiungere prestazioni a livello di esperto su immagini del tessuto colonico pur rimanendo piccoli ed efficienti abbastanza da permetterne una diffusione ampia, aprendo la strada a screening più rapidi e a un supporto per i patologi sovraccarichi. Secondo, e altrettanto importante, un modello che sembra “perfetto” sul proprio dataset domestico può fallire gravemente quando incontra immagini provenienti da un nuovo ospedale. Gli autori sostengono che i lavori futuri debbano concentrarsi nel rendere questi modelli leggeri più robusti ai cambiamenti di colorazione, scanner e popolazioni di pazienti—adottando strategie come addestramento robusto alle variazioni di colorazione, adattamento di dominio e dataset multi‑centro più ampi. Fino ad allora, l’IA dovrebbe essere vista come un assistente promettente piuttosto che come un decisore autonomo nella diagnosi del cancro.
Citazione: Hanif, F., Raza, A. & Mohammed, H.A. Compact deep learning models for colon histopathology focusing performance and generalization challenges. Sci Rep 16, 5489 (2026). https://doi.org/10.1038/s41598-026-35119-y
Parole chiave: cancro del colon, istopatologia, deep learning, CNN leggera, spostamento di dominio