Clear Sky Science · it
Predizione di proteine associate alle radici usando un modello linguistico proteico e reti di convoluzione ipergrafiche
Perché le radici e i loro aiutanti nascosti contano
Quando pensiamo a mantenere le colture in salute, immaginiamo di solito foglie e frutti. Ma gran parte del successo di una pianta avviene fuori dalla vista, nel suolo. Lì, proteine speciali associate alle radici aiutano le piante ad assorbire acqua e nutrienti e a far fronte a stress come siccità o suoli poveri. Individuare queste proteine cruciali solo con esperimenti di laboratorio è lento e costoso. Questo studio presenta un potente modello computazionale, chiamato Hypergraph-Root, che può analizzare rapidamente sequenze proteiche e prevedere quali sono probabilmente associate alle radici, offrendo una via più veloce verso colture più robuste e raccolti migliori.
Operai nascosti nel suolo
Le radici delle piante fanno più che ancorare la pianta al terreno. Rilevano continuamente l’ambiente, assorbono minerali e comunicano con i microrganismi del suolo. Le proteine associate alle radici sono centrali in tutto questo, determinando come le radici crescono, come rispondono a calore, siccità o carenze nutritive e come interagiscono con microrganismi utili. Poiché queste proteine influenzano fortemente resa e resilienza, agricoltori e miglioratori le considerano importanti anche se non le vedono direttamente. Tuttavia molte di queste proteine restano ancora scoperte, in gran parte perché i metodi tradizionali—come la proteomica e gli studi di espressione genica—richiedono strumenti costosi, analisi complesse ed esperimenti laboriosi.
Trasformare le sequenze proteiche in indizi
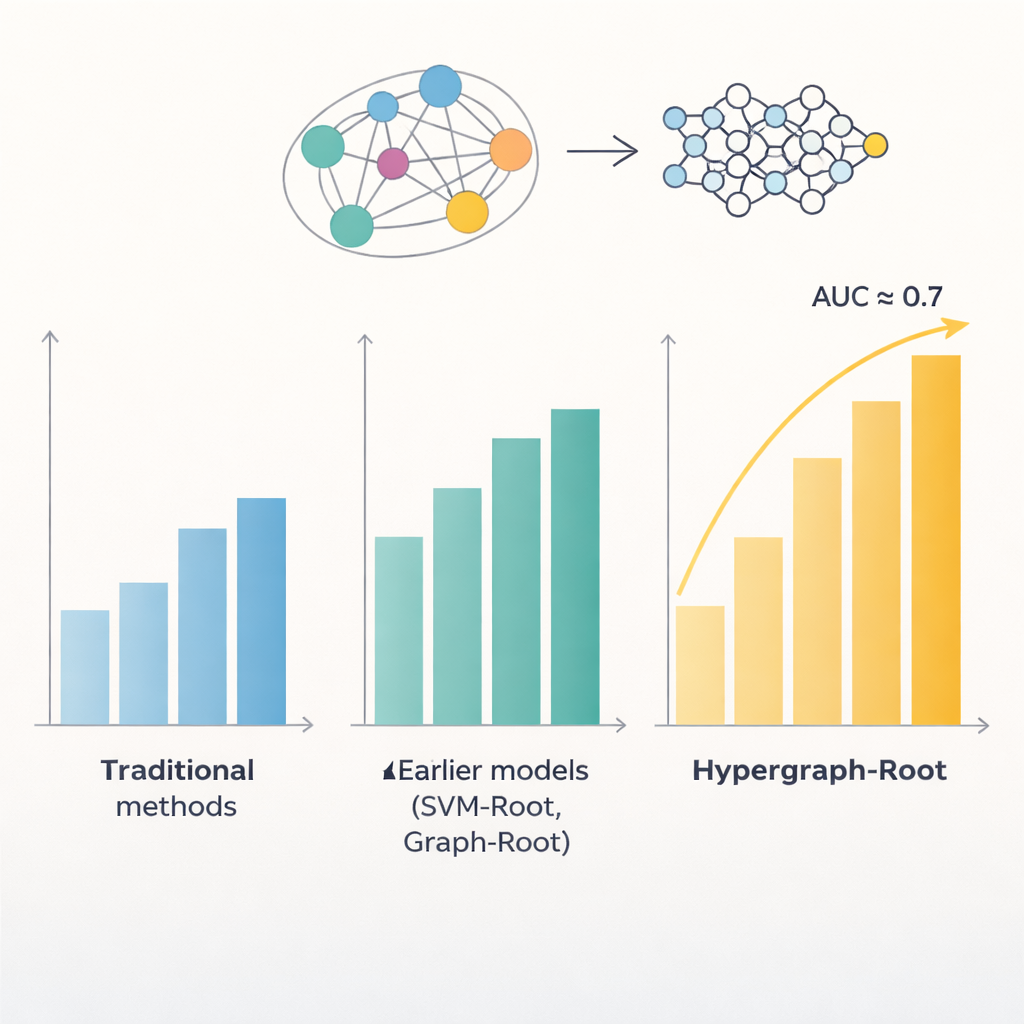
Le proteine sono costruite da catene di amminoacidi, e i modelli in queste catene spesso rivelano dove una proteina opera nella pianta e cosa fa. Modelli computazionali precedenti hanno cercato di sfruttare questi schemi per individuare proteine associate alle radici, ma si fermavano a accuratezze inferiori all’80 percento. Un problema è che trattavano le relazioni tra amminoacidi in modo abbastanza semplice, di solito come coppie. Un altro è che si basavano su tipi limitati di caratteristiche estratte dalle sequenze. Gli autori hanno ragionato che rappresentazioni più ricche di ogni proteina, insieme a modi più intelligenti di modellare le relazioni fra amminoacidi, potessero scoprire schemi più sottili legati alle funzioni radicolari.
Prendere in prestito trucchi dal linguaggio e dalle reti
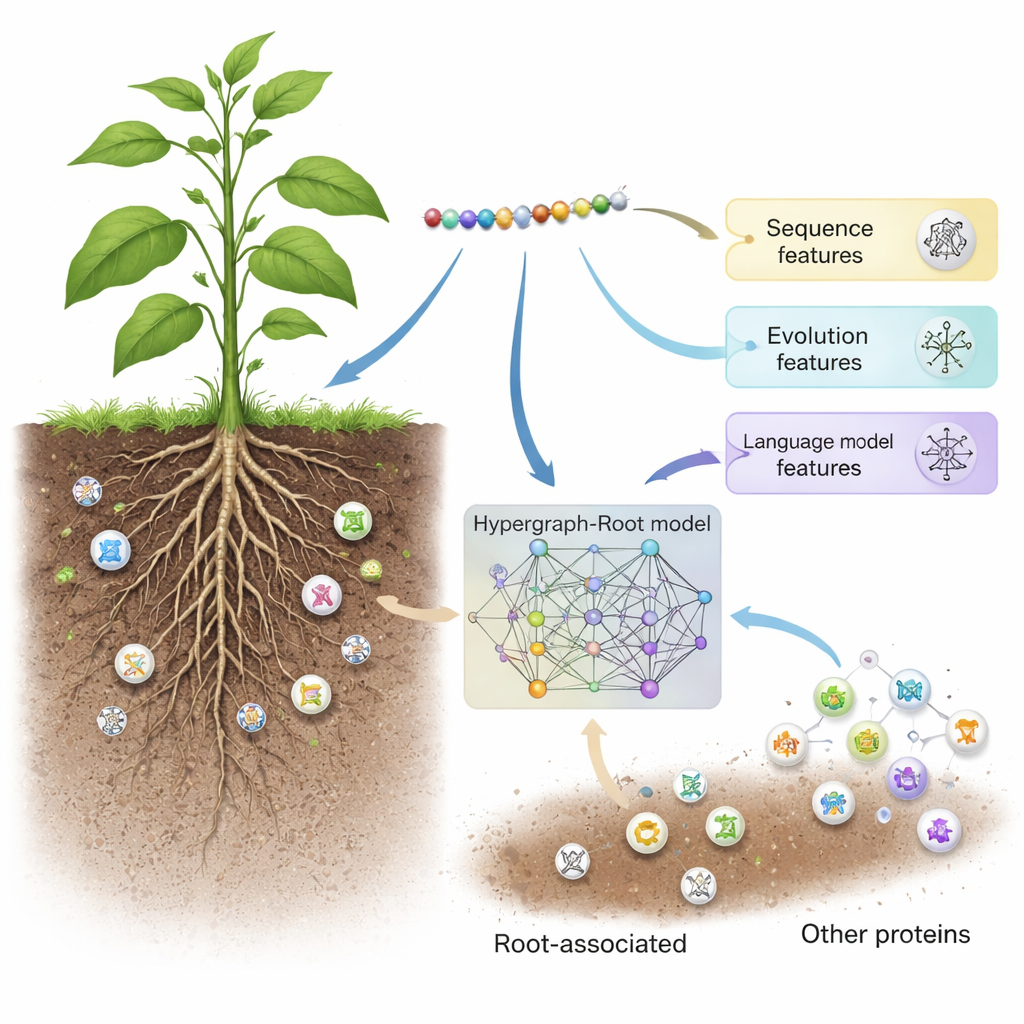
Hypergraph-Root inizia descrivendo ogni proteina in tre modi complementari. Usa schemi di punteggio di sequenza tradizionali (BLOSUM62 e matrici di punteggio posizione-specifiche) che catturano come gli amminoacidi tendono a sostituirsi l’un l’altro nell’evoluzione. Aggiunge poi una terza descrizione, più moderna, proveniente da un modello linguistico per proteine chiamato ProtT5—software addestrato su milioni di sequenze proteiche, simile a come un motore di predizione del testo viene addestrato sul linguaggio umano. ProtT5 produce un ricco “embedding” numerico per ogni amminoacido che codifica indizi strutturali e funzionali. Insieme, queste tre visuali forniscono un’impronta dettagliata di ogni proteina nello studio.
Mappare connessioni complesse all’interno delle proteine
Per andare oltre semplici confronti a coppie, i ricercatori hanno predetto quanto siano vicini gli amminoacidi nella struttura 3D di una proteina e hanno usato queste informazioni per costruire un ipergrafo—una rete in cui una singola connessione può unire più di due amminoacidi contemporaneamente. Una rete neurale specializzata, la rete di convoluzione ipergrafica, elabora questa rete consapevole della struttura e affina le impronte delle proteine in caratteristiche di livello superiore. Un modulo di attenzione multi-testa impara quindi quali parti della proteina portano i segnali più utili per decidere se è associata alle radici. Infine, un classificatore standard trasforma queste caratteristiche distillate in un punteggio di probabilità: associata alle radici o no. Su molte sessioni di addestramento e su set di test sia bilanciati sia sbilanciati, Hypergraph-Root ha raggiunto accuratezze superiori all’83 percento e un’area sotto la curva ROC (AUC) intorno a 0,9, superando chiaramente i modelli precedenti.
Ciò che il modello rivela e perché è importante
Oltre all’accuratezza grezza, il modello ha fornito intuizioni su quali informazioni contano di più. Le caratteristiche provenienti dal modello linguistico ProtT5 hanno contribuito più delle caratteristiche tradizionali di sequenza ed evolutive, suggerendo che i grandi modelli pre-addestrati possono catturare segnali biologici sottili che i metodi più datati perdono. Anche il componente ipergrafico si è dimostrato importante: rimuoverlo o sostituirlo con un modello a grafo più semplice ha ridotto le prestazioni. Quando i ricercatori hanno applicato Hypergraph-Root a proteine non precedentemente etichettate come associate alle radici, ha messo in evidenza un piccolo gruppo le cui funzioni note—come il trasporto attraverso le membrane e l’etichettatura proteica nelle radici—suggeriscono fortemente un ruolo nella biologia radicale. Questi candidati offrono ora a biologi sperimentali liste mirate da testare in laboratorio.
Da previsioni intelligenti a colture più forti
In termini pratici, Hypergraph-Root è come un bibliotecario esperto per la biologia delle piante: date solo le “lettere” di una proteina, stima se quella proteina lavora probabilmente nelle radici. Combinando intuizioni dal modello linguistico, la storia evolutiva e relazioni strutturali complesse, migliora notevolmente gli strumenti di predizione precedenti. Pur non sostituendo gli esperimenti, può restringere migliaia di possibilità a poche maneggevoli, risparmiando tempo e denaro. A lungo termine, questi modelli potrebbero accelerare la scoperta di proteine associate alle radici che aiutano le colture a sopravvivere a calore, siccità o suoli poveri—un passo importante verso un’agricoltura più resiliente in un clima che cambia.
Citazione: Chen, L., Xun, X. & Zhou, B. Root-associated protein prediction using a protein large language model and hypergraph convolutional networks. Sci Rep 16, 4876 (2026). https://doi.org/10.1038/s41598-026-35110-7
Parole chiave: proteine associate alle radici, bioinformatica vegetale, deep learning, modelli linguistici per proteine, resilienza delle colture