Clear Sky Science · it
Un approccio di apprendimento multimodale e simulazione per la percezione nei sistemi di guida autonoma
Auto a guida autonoma più intelligenti
Le auto a guida autonoma promettono strade più sicure e meno traffico, ma soltanto se riescono davvero a comprendere l’ambiente che le circonda. Questo articolo esplora un nuovo modo per aiutare i veicoli autonomi a “vedere”, “sentire” e “anticipare” l’ambiente in modo più simile a un guidatore umano attento—combinando diversi sensori, testando in sicurezza una copia virtuale del mondo reale e rendendo le decisioni dell’auto più trasparenti per le persone.
Vedere la strada con molti “sensi”
La maggior parte dei sistemi di assistenza alla guida oggi si affida fortemente alle telecamere, che funzionano bene con buona illuminazione ma faticano in presenza di nebbia, pioggia o di notte. Questo studio combina tre tipi di sensori—telecamere, scanner laser (LiDAR) e radar—così che l’auto non dipenda da un’unica fonte di informazione fragile. Le telecamere catturano colore e dettagli ricchi, il LiDAR costruisce un’immagine 3D precisa della scena e il radar rimane affidabile con maltempo. Gli autori fondono i tre flussi in una visione unificata del traffico, offrendo al veicolo una comprensione più completa e affidabile di strade, pedoni e altri veicoli.
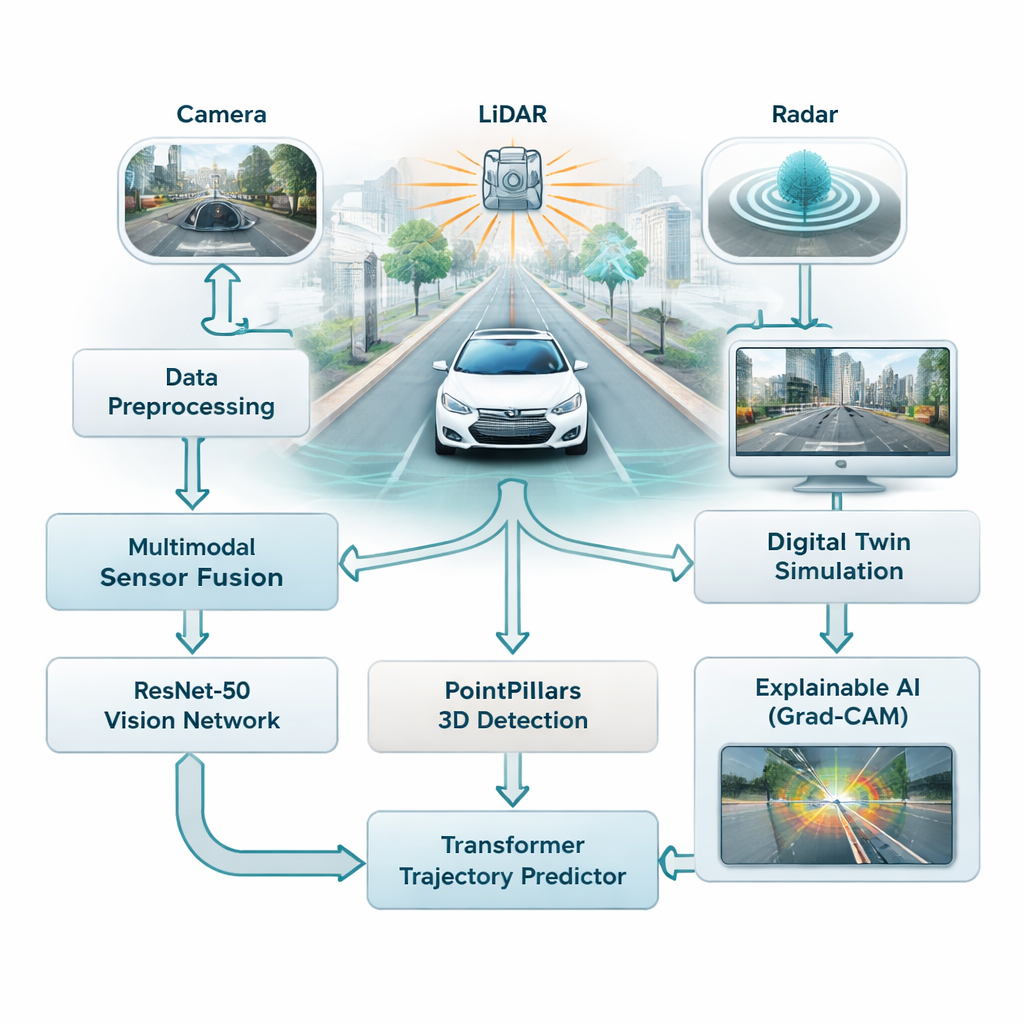
Insegnare all’auto a riconoscere e anticipare
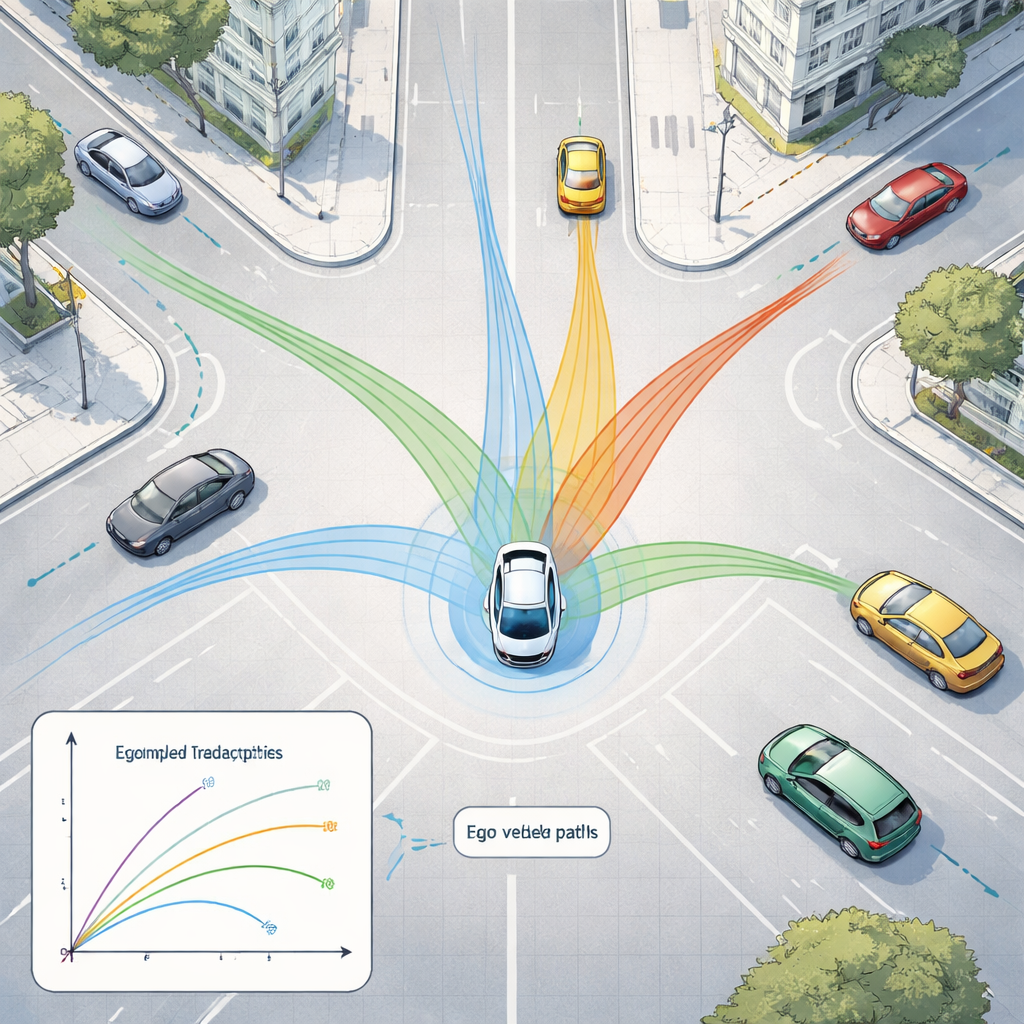
Per interpretare questo flusso di dati, il framework utilizza due famiglie di modelli di IA moderni. Innanzitutto, una rete profonda per immagini chiamata ResNet-50 analizza le immagini delle telecamere per cogliere la situazione complessiva—quanto è affollata la strada, dove sono visibili le corsie e come è organizzata la scena. Allo stesso tempo, un modello 3D chiamato PointPillars elabora le nuvole di punti LiDAR per localizzare veicoli e altri oggetti in tre dimensioni. Questi segnali vengono poi alimentati in un Transformer, un tipo di IA originariamente progettato per il linguaggio, che eccelle nel comprendere come le cose cambiano nel tempo. Qui impara a prevedere come i veicoli vicini e gli altri oggetti in movimento tenderanno a muoversi nei secondi successivi, tenendo conto sia del loro movimento passato sia della struttura della strada.
Costruire una pista di prova virtuale sicura
Invece di testare situazioni rischiose direttamente sulle strade pubbliche, i ricercatori collegano il loro sistema a un digital twin—una replica virtuale delle strade cittadine reali basata su un ampio dataset pubblico di Boston e Singapore. In questo mondo simulato, i sensori dell’auto, i suoi movimenti e l’ambiente vengono riprodotti e modificati a piacimento, mentre l’IA prova a tracciare gli oggetti e a prevederne i percorsi futuri. Il sistema può eseguire questi scenari “what if?” in tempo reale, con tempi di risposta inferiori ai 50 millisecondi, permettendo agli ingegneri di esplorare casi limite come frenate improvvise, curve strette o incroci affollati senza mettere in pericolo nessuno.
Uno sguardo dentro la “scatola nera” dell’IA
Una critica frequente del deep learning è che può essere difficile capire perché il modello ha preso una determinata decisione. Per affrontare questo problema, gli autori usano un metodo chiamato Grad-CAM, che evidenzia le parti di un’immagine che più hanno influenzato l’output del modello. Queste mappe di calore mostrano, per esempio, se la rete si sta concentrando su un’altra auto, su un pedone o su una segnaletica della corsia quando stima le traiettorie. Sebbene questo passaggio esplicativo venga eseguito offline e non nel ciclo in tempo reale dell’auto, aiuta gli ingegneri e i revisori della sicurezza a verificare che il sistema presti attenzione agli indizi giusti, elemento cruciale per costruire fiducia pubblica.
Quanto guida meglio?
Quando testato su centinaia di scene urbane di guida, il framework proposto rileva oggetti 3D con precisione e predice i movimenti più accuratamente rispetto a regole fisiche semplici che assumono velocità costante o accelerazione stabile. I suoi errori di previsione—quanto le posizioni previste si discostano dalla realtà—sono significativamente più piccoli rispetto a tali baseline e vicini a un solido modello ricorrente di IA, pur rimanendo sufficientemente veloce per l’uso in tempo reale. Esperimenti accurati che confrontano diversi design di rete mostrano che un modello di immagini più profondo e un rilevatore 3D di profondità media raggiungono il miglior compromesso tra accuratezza e velocità, e che il sistema può essere distribuito su computer di bordo più piccoli dopo la compressione del modello.
Cosa significa per gli automobilisti di tutti i giorni
Per i non specialisti, il messaggio è che auto a guida autonoma più sicure e più affidabili probabilmente nasceranno da un approccio che combina sensori multipli, prevede come evolverà la scena e viene testato a fondo in mondi virtuali realistici. Unendo percezione, predizione, simulazione e spiegazioni comprensibili dall’uomo in un unico progetto, questo lavoro avvicina i veicoli autonomi al comportamento di partner di guida cauti e trasparenti piuttosto che a macchine misteriose.
Citazione: Almadhor, A., Al Hejaili, A., Alsubai, S. et al. A multimodal learning and simulation approach for perception in autonomous driving systems. Sci Rep 16, 5505 (2026). https://doi.org/10.1038/s41598-026-35095-3
Parole chiave: guida autonoma, fusione di sensori, predizione di traiettoria, rilevamento di oggetti 3D, simulazione digital twin