Clear Sky Science · it
Previsione del prezzo del carbonio RF-LSTM basata sulla scomposizione CEEMDAN e sulla ricostruzione mediante entropia multiscala
Perché i prezzi del carbonio interessano tutti
Quando governi e imprese pagano per il diritto di emettere anidride carbonica, il prezzo di quelle emissioni incide silenziosamente sulle bollette energetiche, sugli investimenti in tecnologie pulite e persino sul ritmo dell'azione climatica. I prezzi del carbonio, però, oscillano in modo complesso, guidati dalla politica, dal meteo e dai mercati. Questo studio presenta un nuovo metodo per prevedere i prezzi del carbonio con maggiore accuratezza, aiutando decisori politici, imprese e investitori a pianificare meglio per un futuro a basse emissioni.
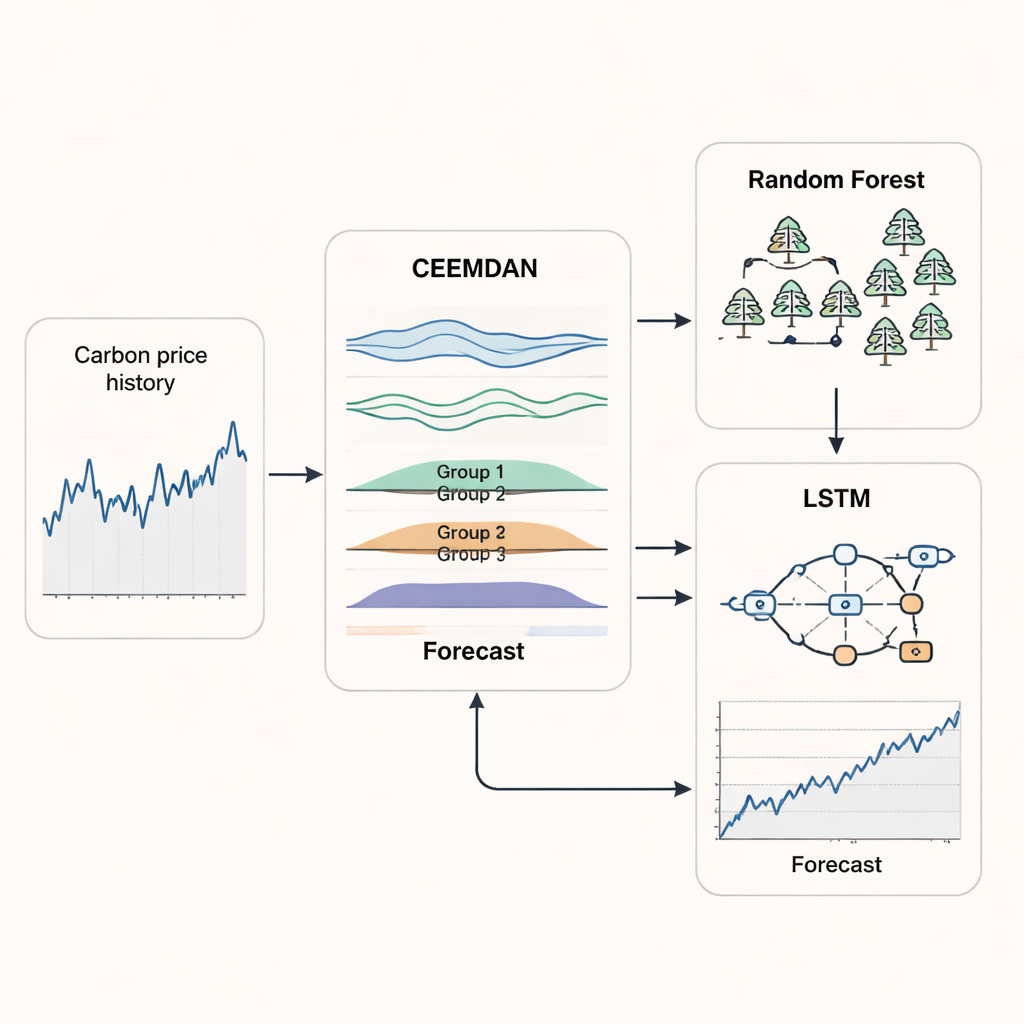
Districare un mercato climatico rumoroso
I sistemi di scambio delle emissioni, come il sistema dell'Unione Europea (EU ETS) e i progetti pilota regionali in Cina, sono stati creati per ridurre i gas serra al minor costo possibile. In pratica, i loro prezzi sono tutt'altro che uniformi: reagiscono a regole in evoluzione, cicli economici e aspettative mutevoli. I modelli statistici tradizionali faticano con questo tipo di comportamento erratico e non stazionario. Anche gli strumenti moderni di intelligenza artificiale, come le reti neurali standard, possono perdere pattern importanti o diventare instabili quando i prezzi oscillano bruscamente. Gli autori sostengono che per comprendere questi dati sia necessario prima scomporre la storia dei prezzi in blocchi più semplici, prima di applicare strumenti di previsione avanzati.
Separare i prezzi in ritmi nascosti
Il primo pilastro del nuovo approccio è un metodo chiamato CEEMDAN, che prende una curva del prezzo del carbonio frastagliata e la scompone in diversi componenti più regolari, ciascuno rappresentante un ritmo di movimento diverso — dalle rapide scosse giorno per giorno alle tendenze lente e di lungo periodo. Invece di trattare ciascuno di questi componenti separatamente, i ricercatori utilizzano una misura chiamata entropia multiscala per valutare quanto complesso sia ogni componente su differenti scale temporali. I componenti con complessità simile vengono raggruppati e ricostruiti in pochi segnali più chiari. Questo passaggio riduce rumore e ridondanza, permettendo al modello di concentrarsi sui pattern che contano davvero per la previsione, invece di essere distratto da fluttuazioni casuali.
Affiancare due cervelli di machine learning
Una volta che la serie dei prezzi del carbonio è stata pulita e ricomposta, lo studio combina due metodi di apprendimento automatico che eccellono in compiti differenti. Un modello random forest — un ensemble di molti semplici alberi decisionali — è assegnato al gruppo ad alta frequenza, dove i prezzi saltano rapidamente e in modo imprevedibile. Le random forest sono brave a catturare movimenti netti e di breve termine senza overfitting. Per i gruppi più regolari che catturano tendenze a medio e lungo termine, gli autori usano una rete LSTM (long short-term memory), un tipo di rete ricorrente progettata per ricordare pattern nel tempo. Lasciando che ogni metodo si specializzi e ricombinando poi i loro output, il sistema ibrido RF–LSTM mira a seguire sia le svolte immediate sia la direzione più ampia del mercato del carbonio.
Adattarsi al mercato e testare le prestazioni
Per riflettere il modo in cui funziona la previsione nel mondo reale, gli autori adottano uno schema a finestra temporale mobile. Il modello viene addestrato su un tratto iniziale di dati storici, effettua una previsione a breve termine, quindi sposta la finestra in avanti ripetendo il ciclo fino a raggiungere la fine della serie. Questo evita che il modello "sbiri" i dati futuri e gli permette di adattarsi a cambiamenti strutturali del mercato. Il framework è testato su lunghe serie temporali provenienti dal mercato del carbonio di Hubei in Cina e dal sistema UE, utilizzando misure di errore standard e un indice di precisione direzionale che conta quante volte il modello indovina correttamente la direzione del prezzo — verso l'alto o verso il basso. Il modello ibrido produce costantemente errori più piccoli e una precisione direzionale più alta rispetto a una serie di metodi di riferimento, inclusi strumenti classici per serie temporali e progetti di deep learning più recenti come Transformer e reti basate su attention.
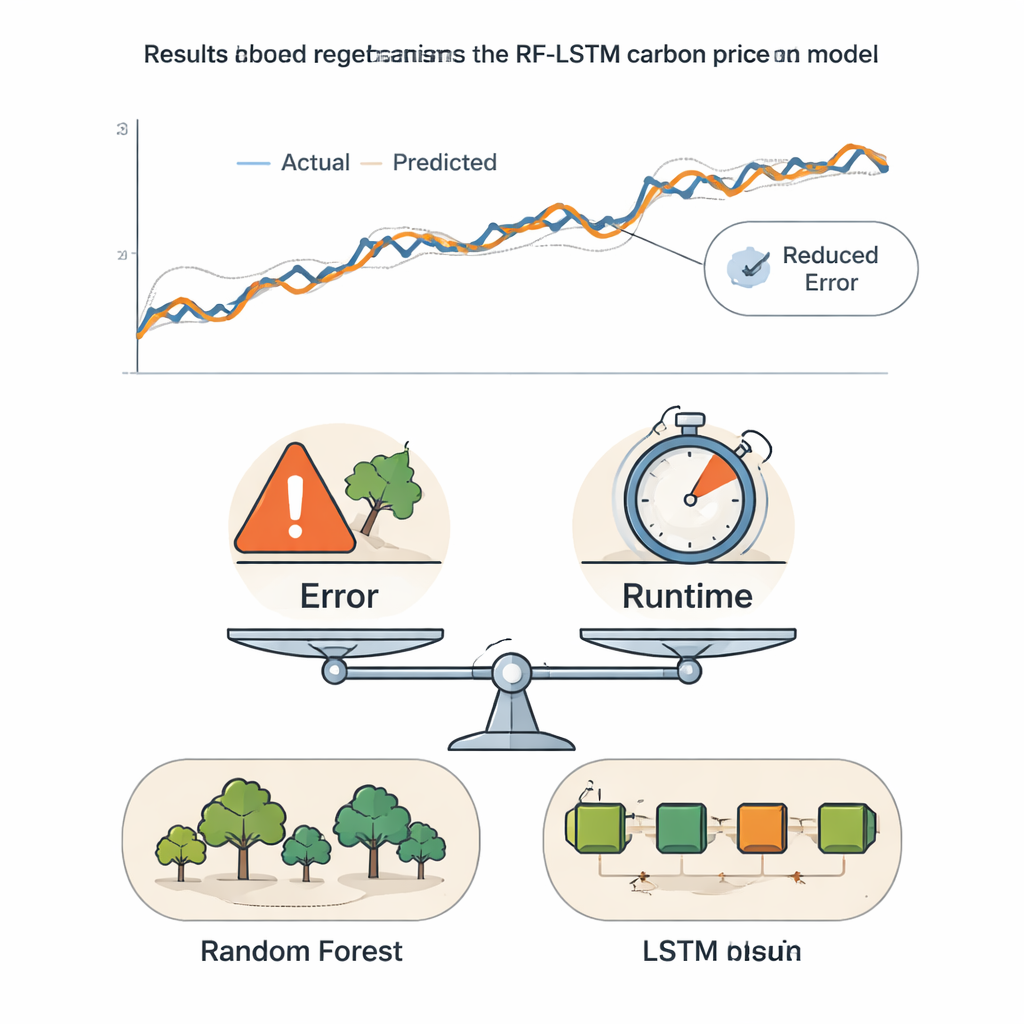
Bilanciare accuratezza e velocità per decisioni reali
Poiché i modelli estremamente accurati possono anche essere lenti e costosi da eseguire, gli autori introducono un punteggio composito che fonde l'errore di previsione con il tempo di calcolo. Variando quanto peso venga dato all'accuratezza rispetto alla velocità, mostrano quando modelli più semplici possono essere sufficienti e quando l'approccio ibrido più sofisticato rende davvero vantaggioso. Sia nei mercati di Hubei che in quello UE, non appena all'accuratezza viene assegnato anche un peso moderato, il nuovo framework RF–LSTM risulta il migliore. Per i lettori non specialisti, la conclusione principale è che questo metodo offre una "previsione meteo" più affidabile per i prezzi del carbonio, fornendo a operatori di mercato e regolatori uno strumento più netto, ma comunque pratico, per guidare investimenti, gestire il rischio e progettare politiche climatiche.
Citazione: Wang, H., Li, Y. RF-LSTM carbon price prediction based on CEEMDAN decomposition and multiscale entropy reconstruction. Sci Rep 16, 5230 (2026). https://doi.org/10.1038/s41598-026-35085-5
Parole chiave: prezzo del carbonio, scambio di emissioni, apprendimento automatico, previsione di serie temporali, politica climatica