Clear Sky Science · it
Selezione ibrida delle caratteristiche con un nuovo modello di deep learning per la previsione del rischio COVID-19
Perché prevedere il rischio COVID-19 conta ancora
Anche se il mondo impara a convivere con il COVID-19, il virus non è scomparso. Continuano a emergere nuove varianti, gli ospedali possono ancora essere sotto pressione e le persone vulnerabili restano a maggior rischio di malattia grave o di morte. I medici hanno quindi bisogno di modi rapidi e affidabili per stimare quanto sia probabile che un paziente infetto sviluppi una forma grave. Questo articolo presenta un nuovo modello computazionale che utilizza dati ospedalieri e intelligenza artificiale avanzata per prevedere il rischio COVID-19 in modo più accurato, aiutando potenzialmente i clinici a decidere chi necessita di monitoraggio più stretto, trattamento precoce o cure intensive.
Dai record grezzi dei pazienti a segnali utilizzabili
Lo studio parte da un dataset clinico molto ampio: più di un milione di pazienti anonimi, ciascuno descritto da 21 caratteristiche semplici, per lo più binarie, come fascia di età, patologie pregresse e altri fattori di rischio. I dati reali degli ospedali sono disordinati, quindi il primo passo è «pulirli». Gli autori applicano un trucco matematico chiamato scala logaritmica, che comprime i valori estremi ed espande i raggruppamenti di valori molto piccoli. Questa trasformazione rende i dati più stabili e più facili da gestire per gli algoritmi, riducendo la probabilità che numeri insoliti o indicatori scarsi fuorviino il modello.
Scegliere i segnali più significativi
Non tutte le variabili registrate sono ugualmente utili per la previsione, e troppe caratteristiche deboli possono in realtà confondere un sistema di intelligenza artificiale. I ricercatori quindi eseguono una selezione delle feature, un processo che filtra le informazioni meno utili e conserva i fattori più informativi. Il loro approccio ibrido combina due idee: una misura valuta quanto una caratteristica separa i pazienti ad alto rischio da quelli a basso rischio, e un’altra verifica quanto le caratteristiche si sovrappongono tra loro. Bilanciando questi due punti di vista su una scala comune, il metodo favorisce le feature che sono sia potenti sia non ridondanti. Questo sfoltimento accelera l’addestramento, riduce l’overfitting e concentra il modello sui pattern clinicamente più rilevanti.
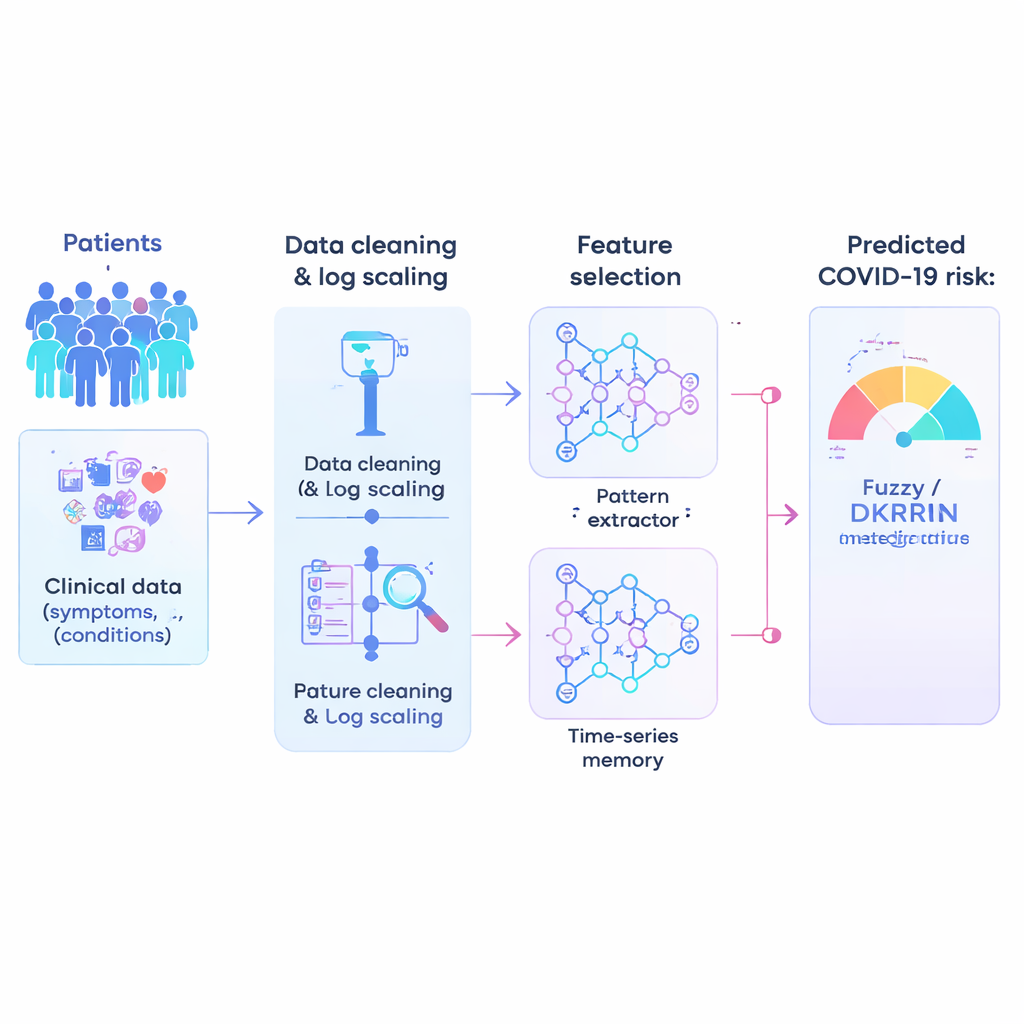
Fondere riconoscimento di pattern e ragionamento fuzzy
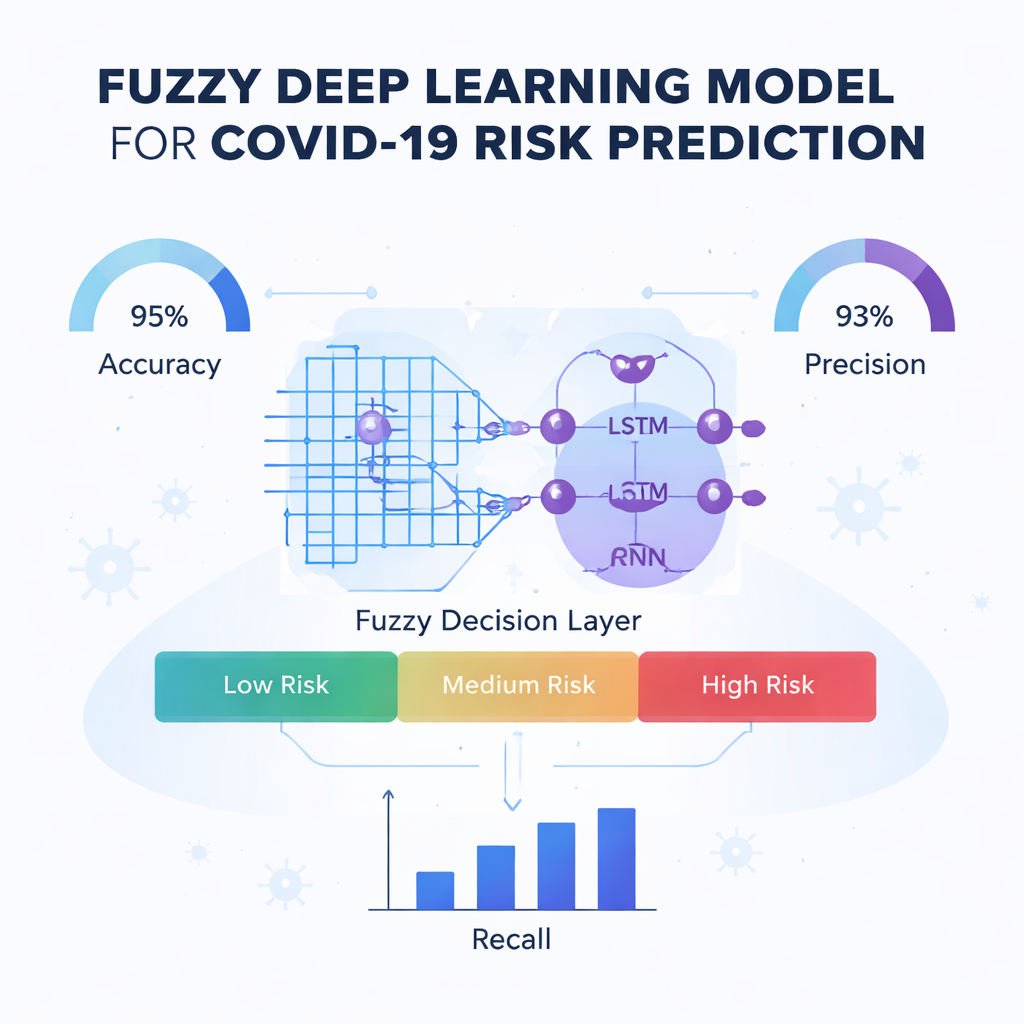
Il nucleo dell’articolo è un nuovo motore predittivo chiamato Fuzzy-Deep Kronecker Recurrent Neural Network, o Fuzzy-DKRNN. Mescola diverse tecniche complementari. Un componente, una Deep Kronecker Network, è progettato per scoprire pattern compatti e strutturati nascosti nei dati clinici. Un altro componente, una rete ricorrente profonda, è adatta a catturare dipendenze e tendenze, per esempio quando una combinazione di fattori nel tempo influenza il rischio. Su questi strati, gli autori sovrappongono un sistema di logica fuzzy. Invece di prendere solo decisioni nette sì/no, le regole fuzzy esprimono enunciati come «se diversi indicatori di rischio sono moderatamente elevati, il paziente è probabilmente ad alto rischio». Ogni regola porta un grado di certezza, permettendo al modello di gestire l’incertezza e le aree grigie comuni in medicina.
Quanto bene si comporta il modello?
Gli autori testano rigorosamente il loro modello Fuzzy-DKRNN rispetto a diverse alternative allo stato dell’arte, inclusi sistemi basati su radiografie toraciche, machine learning tradizionale e altri approcci di deep learning. Utilizzando misure standard come accuratezza, precisione, richiamo e F1-score, il loro metodo si posiziona costantemente avanti. Nella sua migliore configurazione, il modello classifica correttamente circa il 91% dei casi nel complesso, con alta capacità sia di rilevare i pazienti che diventeranno gravemente ammalati sia di evitare falsi allarmi in chi non lo sarà. Questi miglioramenti resistono quando si variano la quantità di dati di addestramento e le impostazioni di validazione interna, suggerendo che l’approccio è robusto e non finemente sintonizzato su uno scenario specifico.
Cosa significa questo per pazienti e ospedali
In termini semplici, questo lavoro mostra che combinare una pulizia accurata dei dati, una selezione intelligente dei fattori di rischio chiave e un ibrido di deep learning con logica fuzzy può produrre previsioni del rischio COVID-19 più affidabili a partire da informazioni cliniche di routine. Tale strumento non sostituirà i medici, ma potrebbe fungere da assistente di allerta precoce—segnalando i pazienti che meritano una sorveglianza più attenta, guidando l’allocazione di risorse scarse come i posti in terapia intensiva e, in ultima analisi, contribuendo a ridurre decessi evitabili. La stessa strategia potrebbe essere adattata anche ad altre malattie in cui la rilevazione precoce del rischio da dati clinici complessi è cruciale.
Citazione: P, G.S., Kathiravan, M., Shanthi, S. et al. Hybrid feature selection with novel deep learning model for COVID-19 risk prediction. Sci Rep 16, 4106 (2026). https://doi.org/10.1038/s41598-026-35013-7
Parole chiave: Previsione del rischio COVID-19, deep learning, logica fuzzy, supporto alle decisioni cliniche, modelli di IA medica