Clear Sky Science · it
Una segmentazione accurata in tempo reale di oggetti subacquei usando YOLOv11-UOS dual-domain migliorato con potenziamento adattivo guidato dalla fisica e attenzione potenziata
Immergersi più a fondo con occhi digitali più nitidi
I nostri oceani sono sempre più esplorati non solo da sub e sommergibili, ma anche da telecamere intelligenti montate su robot subacquei. Queste telecamere aiutano a cercare relitti, ispezionare condotte offshore e monitorare barriere coralline e popolazioni ittiche. Tuttavia le immagini subacquee sono spesso torbide, tendenti al blu‑verde e ricche di disturbi visivi, rendendo difficile anche per gli esseri umani — figuriamoci per i computer — distinguere gli oggetti. Questo articolo presenta un nuovo sistema di visione artificiale che ripulisce le immagini subacquee e poi individua e delimita gli oggetti al loro interno, con velocità sufficiente per guidare missioni robotiche in tempo reale.
Perché vedere sott’acqua è così difficile
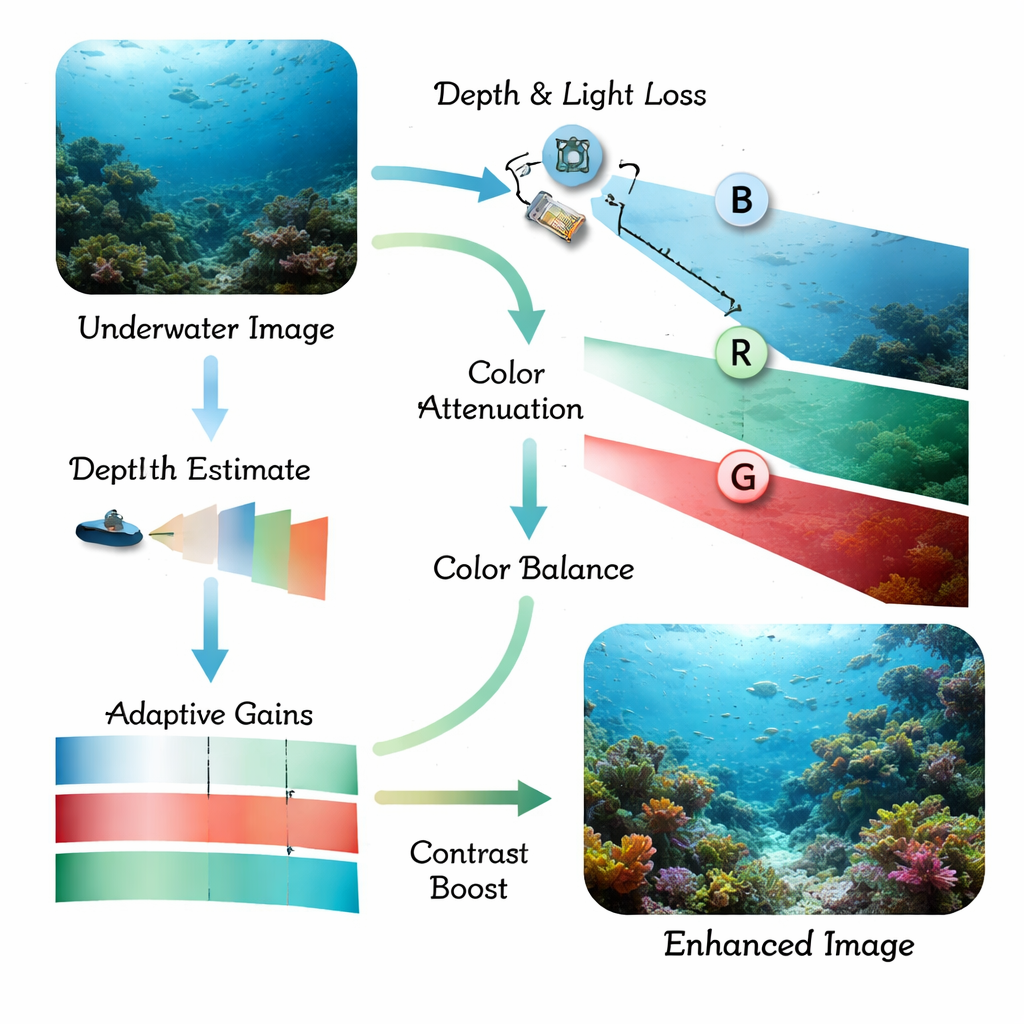
La luce si comporta in modo molto diverso in acqua rispetto all’aria. Man mano che la luce solare penetra, le tonalità rosse scompaiono per prime, poi il verde, lasciando una dominante bluastra e scene spente a basso contrasto. Minuscole particelle sospese nell’acqua diffondono la luce, creando foschia che sfuma i contorni e nasconde i dettagli minuti. I tradizionali programmi di rilevamento oggetti, e persino i modelli deep‑learning più avanzati, faticano con queste immagini distorte: i pesci si confondono con i coralli, le strutture artificiali si perdono nello sfondo e le scene a bassa illuminazione diventano quasi illeggibili. Ricerche precedenti affrontavano di solito solo il miglioramento dell’immagine o solo il rilevamento, lasciando spesso il sistema finale troppo lento, troppo fragile o ancora cieco in acque particolarmente torbide.
Una strategia in due fasi: pulire prima, poi concentrare
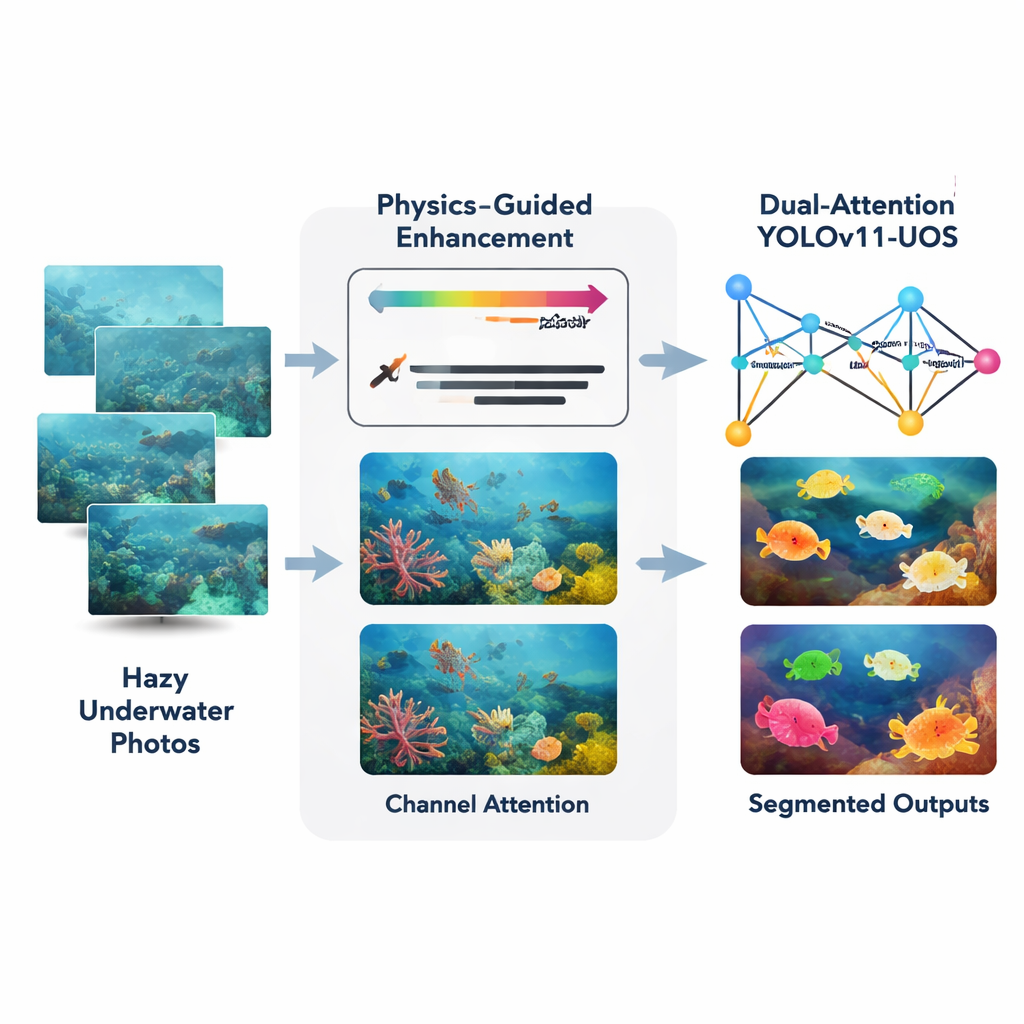
Gli autori propongono un approccio combinato costruito attorno a un rilevatore in tempo reale recente chiamato YOLOv11, qui personalizzato per scene subacquee e per la segmentazione di istanze (delineando un contorno preciso per ciascun oggetto). Prima, un modulo front‑end denominato Potenziamento Adattivo Guidato dalla Fisica riceve le foto subacquee grezze e le corregge usando un modello fisico semplificato di come la luce viene assorbita e diffusa in acqua. Stima la distanza di ciascuna parte della scena dalla camera, quindi compensa la perdita più marcata della luce rossa rispetto al verde e al blu. Questo ripristina colori più naturali e aumenta il contrasto locale, mentre un passaggio attento basato sull’istogramma affila i bordi senza amplificare il rumore, anche nelle regioni scure o torbide.
Insegnare alla rete dove guardare
Una volta che l’immagine è stata ripulita, viene passata a un backbone YOLOv11 aggiornato e dotato di meccanismi di attenzione. Questi moduli aggiunti funzionano un po’ come un riflettore e un filtro colore. L’attenzione spaziale indica alla rete di prestare maggiore attenzione alle regioni importanti — come il profilo di un pesce o il bordo di un manufatto sommerso — e di ignorare sfondi distraenti come sabbia o piante ondeggianti. L’attenzione sui canali regola l’importanza attribuita a diversi pattern di colore e texture, in modo che gli indizi visivi utili vengano enfatizzati mentre quelli irrilevanti vengono attenuati. Insieme, queste due fasi di attenzione aiutano la rete a costruire rappresentazioni interne più nitide prima di decidere dove si trovano gli oggetti e cosa sono.
Test sugli oceani reali e in condizioni difficili
Per valutare l’efficacia pratica del sistema, i ricercatori lo hanno addestrato e testato su diverse raccolte pubbliche di immagini subacquee oltre a un nuovo dataset personalizzato di oltre 7.000 foto accuratamente etichettate provenienti da acque costiere con profondità e torbidità variabili. Hanno misurato metriche standard di rilevamento e segmentazione e confrontato il loro metodo con modelli largamente usati come U‑Net, DeepLab, segmentatori basati su transformer e un sistema YOLOv11 di base senza i nuovi moduli. Il design combinato di potenziamento più attenzione ha migliorato l’accuratezza media di rilevamento di circa 6,5 punti percentuali rispetto al baseline YOLOv11, con contorni degli oggetti visibilmente più puliti e meno elementi mancati o rilevati erroneamente. È importante che il sistema funzioni ancora a circa 38 fotogrammi al secondo su una moderna GPU, abbastanza veloce per un uso quasi in tempo reale su piattaforme robotiche.
Cosa significa per i robot oceanici e la ricerca
In termini semplici, lo studio dimostra che un pre‑processing intelligente e un’attenzione mirata permettono ai computer di «vedere» molto meglio sott’acqua. Prima annullando alcune delle trasformazioni fisiche che degradano le foto subacquee e poi guidando la rete di rilevamento a concentrarsi sulle regioni e i colori più informativi, il metodo fornisce contorni più nitidi e affidabili di pesci, coralli e strutture artificiali. Questo può aiutare veicoli autonomi subacquei a navigare in sicurezza, monitorare ecosistemi marini fragili e ispezionare infrastrutture sottomarine critiche senza supervisione umana. Restano sfide in acque estremamente torbide o in scenari molto profondi privi di luce rossa, ma il quadro proposto rappresenta un passo pratico verso una visione subacquea robusta e in tempo reale che può supportare futuri rilievi 3D e esplorazioni multisensore dell’oceano.
Citazione: Deluxni, N., Sudhakaran, P., Alroobaea, R. et al. An accurate realtime underwater object segmentation using improved dual-domain YOLOv11-UOS with physics guided adaptive enhancement and attention-boosting. Sci Rep 16, 4804 (2026). https://doi.org/10.1038/s41598-026-35001-x
Parole chiave: visione subacquea, robotica marina, miglioramento delle immagini, segmentazione degli oggetti, visione artificiale