Clear Sky Science · it
Predizione della sopravvivenza oncologica tra tumori diversi usando modelli di machine learning
Perché conta prevedere la sopravvivenza del cancro in modi nuovi
I pazienti oncologici e le loro famiglie spesso pongono una domanda semplice ma angosciante: “Quanto tempo mi resta?” I medici provano a rispondere basandosi sulla loro esperienza e sui dati passati, ma per molti tumori rari non esistono abbastanza casi simili per fornire previsioni precise. Questo studio esplora se i moderni programmi informatici possono “prendere in prestito l’esperienza” dai tumori più comuni per aiutare a prevedere la sopravvivenza in quelli meno frequenti, offrendo potenzialmente a più pazienti aspettative più chiare e cure meglio personalizzate. 
Usare i pazienti passati per orientare le cure future
I ricercatori hanno lavorato con un ampio archivio di dati real-world provenienti dai registri tumorali ospedalieri di São Paulo, Brasile. Queste cartelle comprendono più di un milione di pazienti trattati tra il 2000 e il 2019 e includono dettagli come età, stadio del tumore, terapie ricevute e se la persona era ancora in vita tre anni dopo la diagnosi. Concentrarsi su quel traguardo dei tre anni ha permesso al team di confrontare tumori con aspettative di vita molto diverse evitando dati estremamente sbilanciati, in cui quasi tutti o quasi nessuno sopravvive.
Insegnare ai computer a riconoscere i pattern di sopravvivenza
Per trasformare questo registro in uno strumento predittivo, gli autori hanno utilizzato due metodi di machine learning diffusi, XGBoost e LightGBM. Questi metodi non cercano di comprendere la biologia in modo diretto; piuttosto setacciano migliaia di storia cliniche per trovare pattern che colleghino caratteristiche come lo stadio della malattia e i tempi dei trattamenti alla sopravvivenza successiva. Inizialmente, il team ha costruito modelli “specialisti”, ciascuno addestrato solo su un tipo di tumore, come seno, polmone o stomaco. Successivamente hanno verificato quanto bene questi modelli riuscivano a prevedere la sopravvivenza a tre anni per nuovi pazienti con lo stesso tumore, usando misure standard che bilanciano l’identificazione corretta dei sopravvissuti e dei non sopravvissuti.
Un tumore può aiutare a prevederne un altro?
Il nucleo dello studio pone una domanda audace: un modello addestrato su un tipo di tumore può prevedere con successo la sopravvivenza in un tumore diverso? Per verificarlo, i ricercatori hanno raggruppato i tumori in due modi: i tumori più comuni (cute, seno, prostata, colon-retto, polmone e cervice) e i tumori del sistema digestivo (cavità orale, orofaringe, esofago, stomaco, intestino tenue, colon-retto e ano). In una prima fase, hanno addestrato modelli separati per ciascun tumore e li hanno testati sugli altri, selezionando solo gli accoppiamenti in cui sia la sopravvivenza sia la non-sopravvivenza venivano predette con un equilibrio ragionevole. Nelle fasi successive hanno unito i dati dei tumori selezionati in set di addestramento condivisi, creando modelli più generali che attingevano a pattern comuni tra neoplasie correlate. 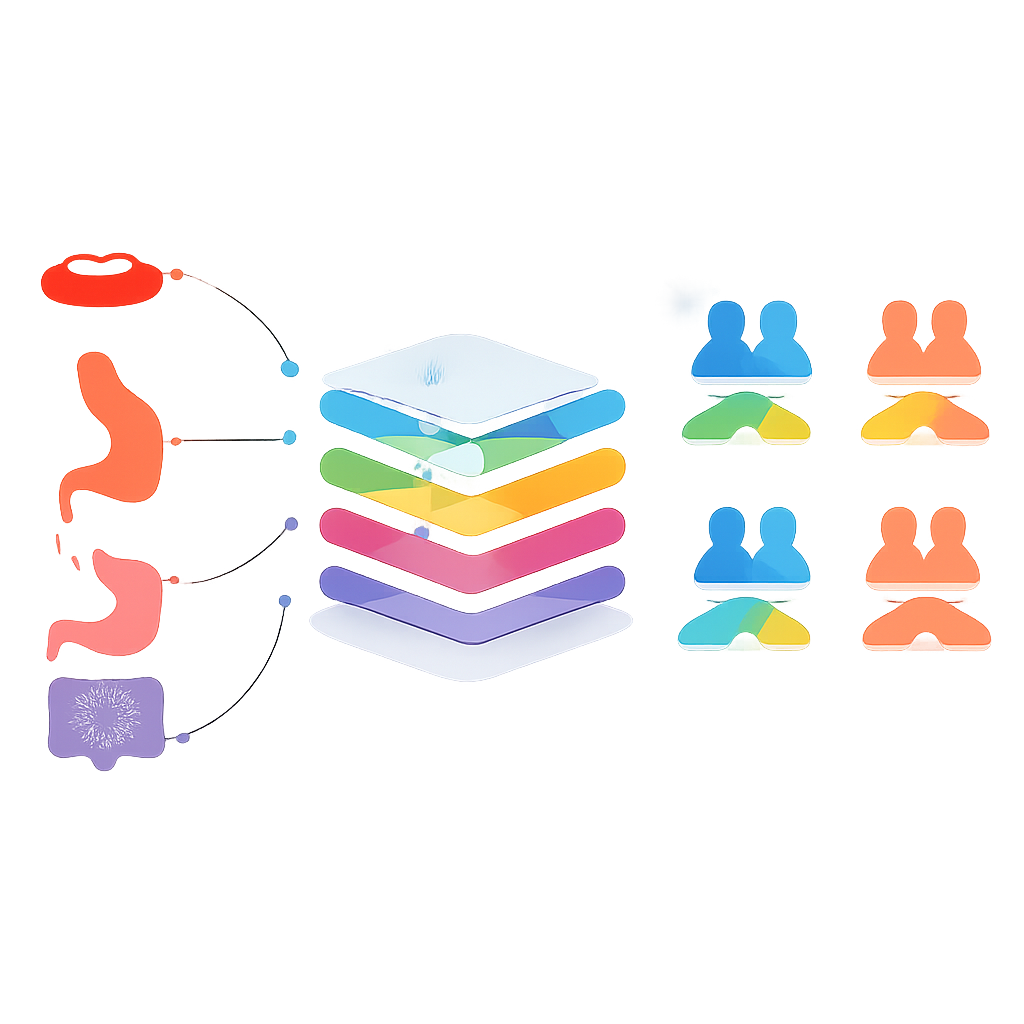
Dove l’apprendimento cross-cancer aiuta — e dove no
Per i tumori comuni, la combinazione dei dati tra i diversi tipi non ha superato i migliori modelli specialistici. Un singolo modello addestrato su tutti e sei i tumori comuni, per esempio, ha predetto meno accuratamente rispetto ai modelli tarati su ciascun tumore singolarmente. La situazione è stata diversa per alcuni tumori del sistema digestivo. Quando i dati di cavità orale, esofago e stomaco sono stati raggruppati, il modello risultante ha predetto la sopravvivenza a tre anni per il tumore dello stomaco leggermente meglio del modello specifico per lo stomaco, con un’accuratezza bilanciata poco oltre l’80 percento. Tuttavia, i test statistici hanno mostrato che questo miglioramento non era chiaramente diverso dal caso, il che significa che il modello condiviso e il modello specialista erano sostanzialmente equivalenti. Risultati simili di “quasi ma non del tutto meglio” sono emersi per cavità orale, intestino tenue e colon-retto, spesso con compromessi tra l’identificazione corretta dei sopravvissuti e dei non-sopravvissuti.
Cosa significa per i pazienti con tumori rari
Anche se i modelli cross-cancer raramente hanno superato i migliori modelli specifici per malattia, spesso si sono avvicinati — usando solo informazioni prese in prestito da altri tipi di tumore. Per i tumori rari che mancano di grandi dataset di qualità, questo è un segnale incoraggiante: in futuro i medici potrebbero appoggiarsi a modelli addestrati su tumori più comuni per offrire stime di sopravvivenza utili quando non è possibile costruire strumenti specialistici. Gli autori avvertono che questi metodi non sono ancora pronti per l’uso clinico di routine e che devono essere testati in altre regioni e combinati con dati biologici più approfonditi. Tuttavia, il lavoro indica una direzione in cui nessun paziente resti senza orientamento semplicemente perché il suo tumore è poco comune.
Citazione: Cardoso, L.B., Egydio, J.E., Toporcov, T.N. et al. Cross-cancer survival prediction using machine learning models. Sci Rep 16, 9623 (2026). https://doi.org/10.1038/s41598-025-34133-w
Parole chiave: predizione sopravvivenza cancro, machine learning in oncologia, modellizzazione tra tumori, tumori rari, registri clinici