Clear Sky Science · it
Calcolo del punteggio di similarità tra frasi tramite apprendimento profondo ibrido con particolare attenzione alle frasi con negazione
Perché il significato delle parole conta per una valutazione equa
Quando gli studenti rispondono alle domande con parole proprie, i sistemi che aiutano gli insegnanti nella valutazione devono comprendere più della semplice corrispondenza di parole chiave. Una piccola parola come “non” può ribaltare il significato di una frase e, se i sistemi automatici non rilevano questo ribaltamento, gli studenti possono essere valutati ingiustamente. Questo articolo affronta il problema progettando un nuovo metodo per confrontare i significati delle frasi prestando particolare attenzione a come le parole di negazione modificano ciò che viene detto.
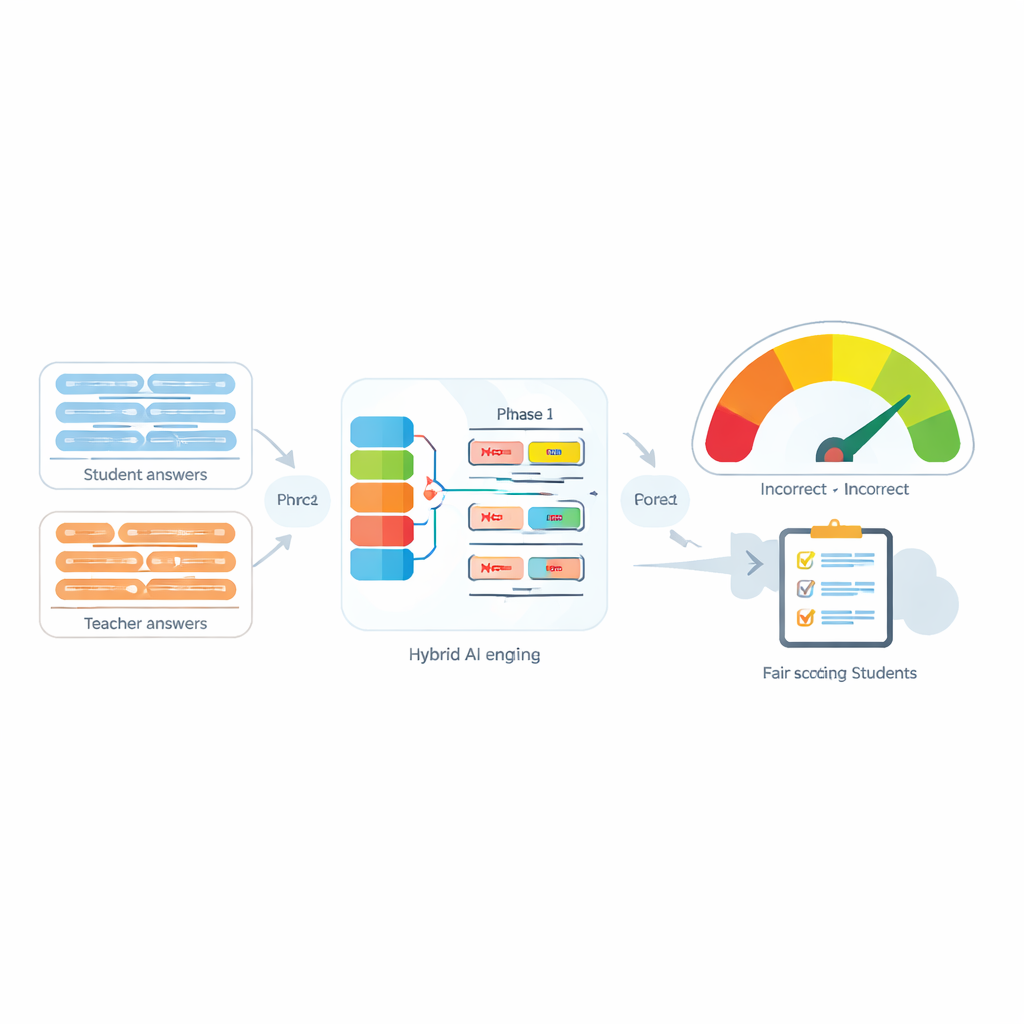
La sfida delle parole piccole ma di grande impatto
I Sistemi di Valutazione Automatica sono sempre più usati per alleggerire il carico di lavoro degli insegnanti confrontando la risposta di uno studente con la risposta modello dell’insegnante. Molti strumenti moderni fanno questo trasformando ogni frase in un “impronta” numerica e quindi misurando quanto quelle impronte siano vicine. Questi strumenti funzionano ragionevolmente bene quando non c’è negazione, ma spesso falliscono quando compaiono parole come “non”, “mai” o “nessuno”. Per esempio, “Il metodo è accurato” e “Il metodo non è accurato” possono risultare sorprendentemente simili per il computer, pur avendo significati opposti. Gli autori mostrano che non è solo la presenza della negazione, ma anche il numero di parole di negazione e la loro posizione nella frase a poter cambiare completamente il significato inteso.
Costruire un dataset che insegna la sfumatura
Per addestrare un sistema che capisca davvero la negazione, gli autori avevano prima bisogno di dati che mettessero in evidenza questi casi difficili. Hanno creato il Negation-Sentence-Similarity Dataset, contenente 8.575 coppie di frasi provenienti da quattro domini dell’informatica: sistemi operativi, basi di dati, reti di calcolatori e apprendimento automatico. Per ogni coppia, annotatori umani hanno assegnato un punteggio di similarità che tiene già conto della negazione. Il dataset registra anche quante parole di negazione usa ciascuna frase e quale tipo di pattern di negazione segue, come una singola “non”, un numero pari o dispari di negazioni, o casi più complessi in cui la negazione interagisce con connettivi come “perché” o “ma”. Questa etichettatura dettagliata fornisce al modello indizi espliciti su come la negazione modelli il significato.
Un motore ibrido che fonde molti punti di vista
Il cuore del sistema proposto, chiamato Negation-Aligned Similarity Scorer, è un motore in due fasi. Nella prima fase, il sistema passa ogni frase attraverso diversi modelli linguistici, ognuno dei quali cattura aspetti leggermente diversi del significato. Le loro uscite vengono combinate e poi elaborate da una rete ricorrente bidirezionale che considera la frase nel suo insieme, tenendo conto dell’ordine delle parole e del contesto locale. Questo produce un riassunto compatto di ogni frase, meglio tarato sulle sfumature di formulazione, inclusa la posizione delle parole di negazione rispetto alle altre parole.
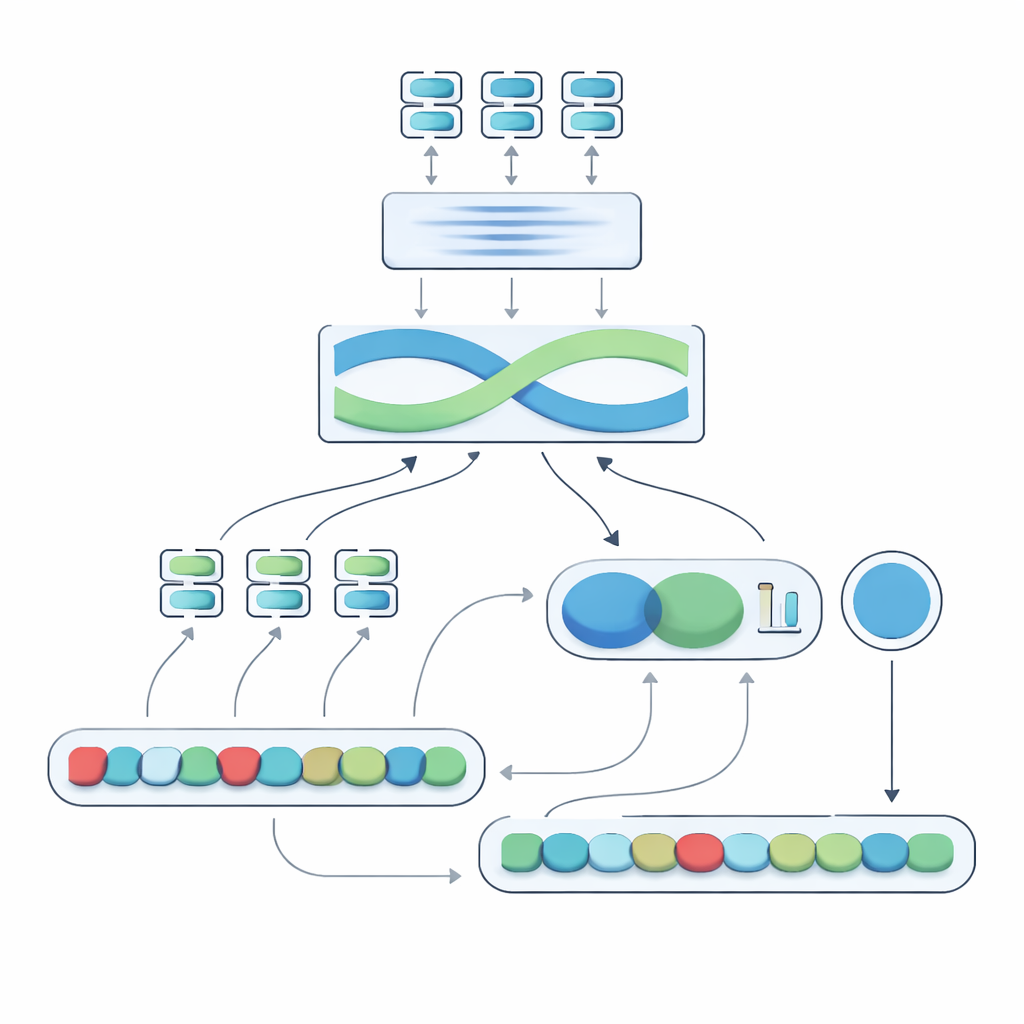
Insegnare al modello a percepire il ribaltamento indotto dalla negazione
Nella seconda fase, il sistema confronta i due riassunti delle frasi e aggiunge informazioni esplicite sulla negazione. Osserva quanto i riassunti differiscono, quanto si sovrappongono, e combina questi segnali con tre caratteristiche semplici: la differenza nel numero di parole di negazione, se le frasi hanno conteggi di negazione pari o dispari (che possono invertire o annullare il significato negativo), e se la negazione appare in posizioni più o meno corrispondenti. Tutti questi indizi vengono fusi in una piccola rete predittiva che produce un punteggio di similarità da 0 a 100. Addestrato end-to-end sul dataset curato, questo punteggio diventa sensibile al modo in cui la negazione rimodella il significato anziché trattare “non” come una parola qualsiasi.
Quanto bene si comporta il nuovo scorer nella pratica
Per testare il loro approccio, gli autori lo valutano sia sul loro dataset personalizzato sia su un benchmark largamente usato di similarità tra frasi. Rispetto a solidi modelli basati su transformer che usano metodi standard, il nuovo scorer ottiene un errore di previsione più basso e una qualità di classificazione molto più alta, con un punteggio F1 vicino a 0,97. In esempi scelti con cura, assegna punteggi di similarità bassi quando la negazione ribalta chiaramente il significato e punteggi alti quando la doppia negazione effettivamente si annulla, mentre i modelli concorrenti tendono ancora a sovrastimare la similarità. Uno studio di ablazione conferma che entrambi gli ingredienti chiave — lo strato ricorrente sensibile alla sequenza e le caratteristiche esplicite di negazione — sono importanti per questo miglioramento delle prestazioni.
Cosa significa per gli studenti e per gli strumenti futuri
Per un lettore non tecnico, la conclusione è semplice: il modo in cui diciamo “non” conta, e le macchine possono essere addestrate a coglierlo. Fondendo più modelli linguistici, elaborazione contestuale e semplici conteggi e posizioni delle parole di negazione, il scorer proposto offre un modo più equo e affidabile per stabilire quando due frasi significano davvero la stessa cosa. Questo può aiutare i sistemi di valutazione automatica a evitare errori gravi, come trattare “non è permesso” come se fosse “è permesso”. Sebbene il metodo richieda maggiori risorse computazionali e sia ancora focalizzato su domini tecnici, indica la strada verso strumenti futuri che catturano meglio la logica fine del linguaggio quotidiano, rendendo le tecnologie linguistiche automatiche più intelligenti e più affidabili.
Citazione: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
Parole chiave: similarità tra frasi, negazione nel linguaggio, valutazione automatica, elaborazione del linguaggio naturale, modelli di deep learning