Clear Sky Science · it
Ricerca IP ad alte prestazioni tramite accelerazione GPU per supportare il routing scalabile ed efficiente nelle reti di comunicazione guidate dai dati
Perché le strade di Internet più veloci sono importanti
Ogni foto che condividi, video che guardi in streaming o messaggio che invii deve attraversare un labirinto di incroci digitali chiamati router. Ogni router deve decidere rapidamente dove inviare il pacchetto di dati successivo. Con l’esplosione dell’uso globale di Internet, queste decisioni avvengono miliardi di volte al secondo e anche piccole latenze possono tradursi in navigazione più lenta o reti congestionate. Questo articolo esplora un nuovo modo per accelerare uno dei passaggi più dispendiosi in termini di tempo di quel processo decisionale sfruttando la massiccia potenza parallela delle unità di elaborazione grafica, gli stessi chip che alimentano i videogiochi e l’intelligenza artificiale, per mantenere le reti future rapide e scalabili.
La rubrica degli indirizzi nascosta di Internet
Al centro di ogni router c’è un enorme elenco di indirizzi, chiamato tabella di instradamento, che mappa intervalli di indirizzi IP al prossimo salto nel percorso. Quando arriva un pacchetto, il router deve cercare quale voce corrisponde meglio alla destinazione del pacchetto, usando la regola del “longest prefix match”: tra tutte le corrispondenze parziali sceglie la più specifica. I metodi software tradizionali memorizzano questi prefissi in strutture ad albero e le percorrono passo dopo passo. Questo funziona, ma quando le tabelle crescono a decine o centinaia di migliaia di voci il processo diventa più lento e richiede più memoria, specialmente sui normali processori centrali che possono gestire solo un numero limitato di compiti contemporaneamente.
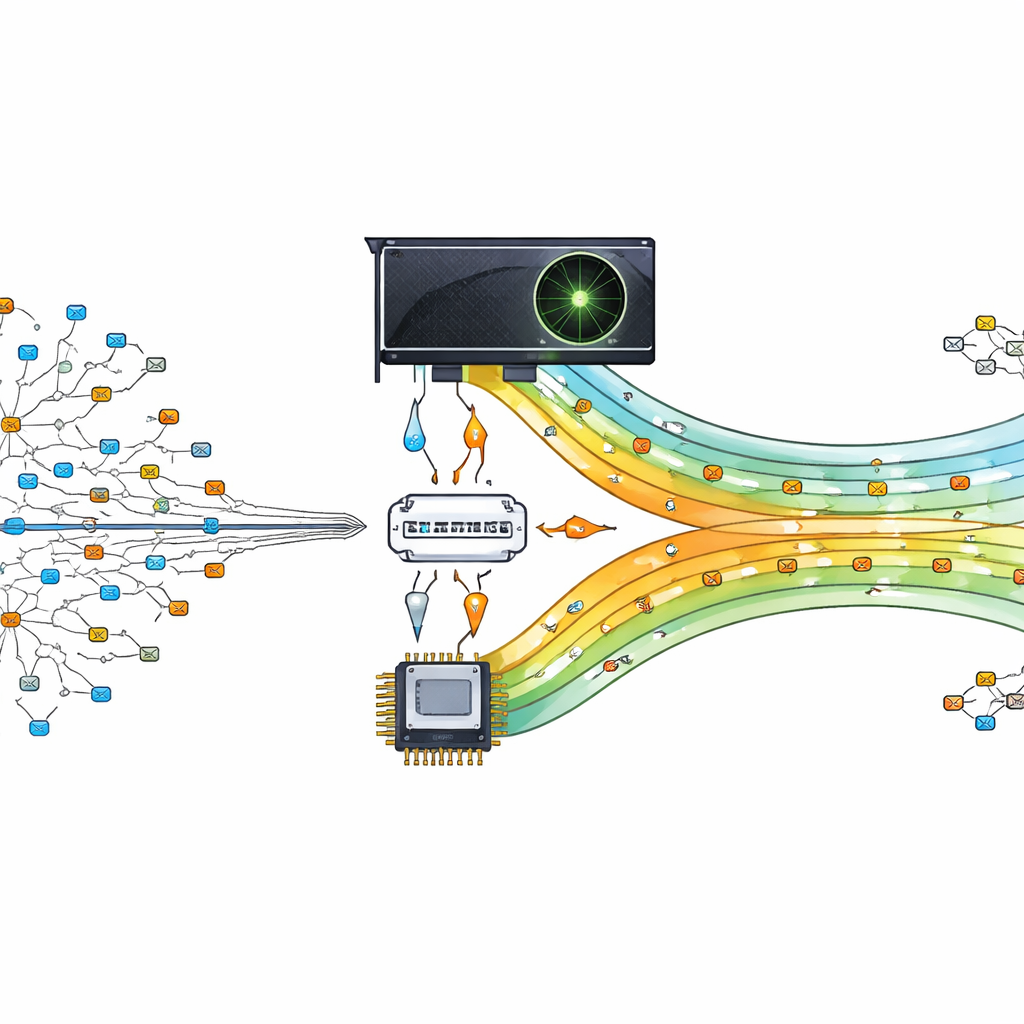
Trasformare un chip grafico in un agente del traffico
Gli autori propongono di delegare questo pesante lavoro di ricerca a una GPU (unità di elaborazione grafica), un chip progettato per eseguire migliaia di piccoli compiti in parallelo. Il loro progetto considera la GPU come un aiuto per il processore principale. Il processore centrale prepara e organizza la tabella di instradamento, quindi invia versioni compatte dei dati alla GPU. Quando arrivano i pacchetti, i loro indirizzi di destinazione vengono suddivisi e inviati alla GPU, dove molti thread cercano contemporaneamente la corrispondenza migliore. Consentendo a centinaia o migliaia di ricerche di avvenire in parallelo, il router può tenere il passo con le moderne esigenze di comunicazione guidate dai dati.
Rimpicciolire gli indirizzi per accelerare le decisioni
Un’intuizione chiave del lavoro è che indirizzi più corti sono più veloci da cercare. Invece di usare gli indirizzi IP grezzi, gli autori li comprimono con un metodo senza perdita chiamato codifica di Huffman, che assegna codici più corti ai pattern di indirizzo più comuni. Questo riduce il numero medio di bit necessari per rappresentare ogni voce, diminuendo sia l’uso di memoria sia l’altezza della struttura di ricerca sottostante. Memorizzano poi i prefissi in un albero “multibit” che esamina più bit contemporaneamente, anziché uno solo, riducendo ulteriormente il numero di passi necessari. Per adattarsi ai punti di forza della GPU, trasformano questo albero in semplici array monodimensionali, sostituendo il complesso inseguimento di puntatori con calcoli di indice regolari che migliaia di thread possono eseguire in modo efficiente.
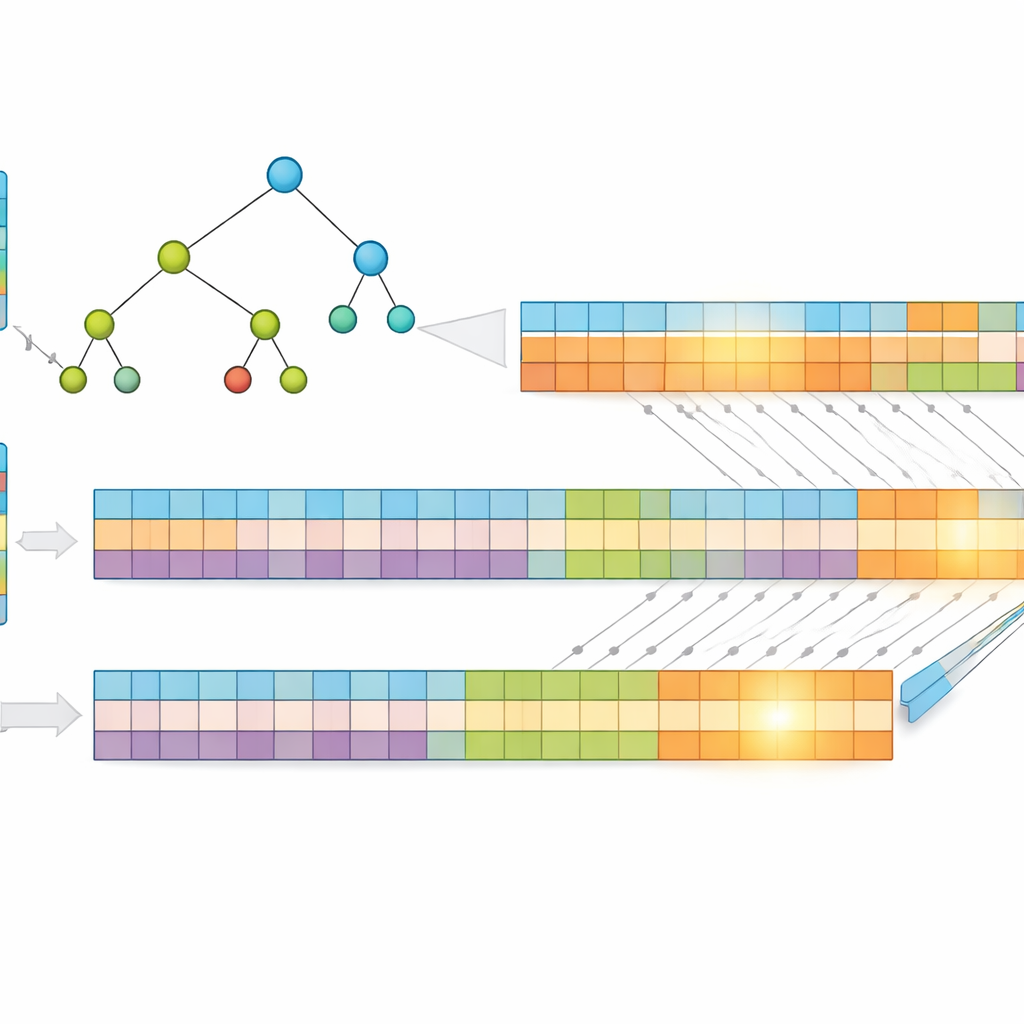
Dividere il problema per un parallelismo massiccio
Per spingere le prestazioni oltre, i ricercatori dividono ogni indirizzo compresso in due metà uguali e costruiscono due alberi separati—uno per la prima metà e uno per la seconda. Quando arriva un pacchetto, la GPU esegue la ricerca in entrambi gli alberi in parallelo. Ogni ricerca restituisce un piccolo insieme di possibili corrispondenze e la risposta finale si ottiene intersecando questi insiemi per trovare il prefisso condiviso e più specifico. Poiché il lavoro è diviso e processato simultaneamente, il tempo impiegato dipende principalmente dalla lunghezza massima del prefisso e dal numero di bit esaminati per passo, non dal numero di voci nella tabella. Test su dati reali di instradamento Internet mostrano che questo progetto mantiene un tempo di ricerca quasi costante anche quando la tabella cresce.
Cosa rivelano gli esperimenti
Il gruppo ha confrontato il loro metodo basato su GPU con varie tecniche note, inclusi alberi binari classici, alberi compressi e altri schemi accelerati su GPU come hashing e alberi di ricerca binari. Su dataset reali di instradamento, il loro sistema ha fornito guadagni spettacolari: circa il 83–91% più veloce rispetto ai metodi ad albero basati su processore centrale più diffusi e l’89–97% più veloce rispetto a metodi GPU precedenti. La compressione ha anche ridotto l’uso di memoria di circa un terzo in media, alleggerendo la pressione sulla memoria limitata on‑chip e contribuendo a mantenere le strutture di ricerca della GPU poco profonde ed efficienti. È importante notare che le prestazioni del metodo sono rimaste stabili al variare delle dimensioni delle tabelle di instradamento, sottolineando la sua idoneità per reti in crescita.
Cosa significa per gli utenti di tutti i giorni
Per un non specialista, il messaggio essenziale è che gli autori mostrano come trasformare un chip grafico in un efficiente agente del traffico per i dati Internet, usando strategie intelligenti di compressione e divisione delle informazioni di indirizzo. Combinando compressione, disposizioni di alberi più intelligenti e ricerca parallela massiccia, il loro approccio trova la migliore rotta per ogni pacchetto molto più rapidamente di molte tecniche esistenti, senza rallentare man mano che gli elenchi di indirizzi di Internet si espandono. Sebbene il lavoro sia dimostrato principalmente per il sistema di indirizzamento odierno, le stesse idee potrebbero essere estese allo spazio di indirizzamento più ampio di domani, contribuendo a mantenere reattivi i servizi online futuri man mano che la nostra domanda di dati continua a crescere.
Citazione: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
Parole chiave: Routing GPU, Ricerca IP, Scalabilità di rete, Inoltro dei pacchetti, Calcolo parallelo