Clear Sky Science · it
Rilevamento di oggetti camuffati tramite interazione gerarchica sensibile a contesto e texture
Perché individuare forme nascoste è importante
Dagli insetti mimetici color foglia al camuffamento militare fino alle formazioni difficili da vedere nelle scansioni mediche, il nostro mondo è pieno di elementi progettati per confondersi con lo sfondo. Insegnare ai computer a trovare in modo affidabile questi oggetti nascosti potrebbe aiutare a proteggere la fauna, migliorare le ispezioni di sicurezza e assistere i medici nella diagnosi precoce delle malattie. Questo articolo presenta un nuovo sistema di intelligenza artificiale, chiamato CTHINet, che impara a vedere attraverso il camuffamento prestando attenzione non solo al contesto complessivo della scena ma anche ai piccoli indizi di texture che l’occhio umano spesso perde.
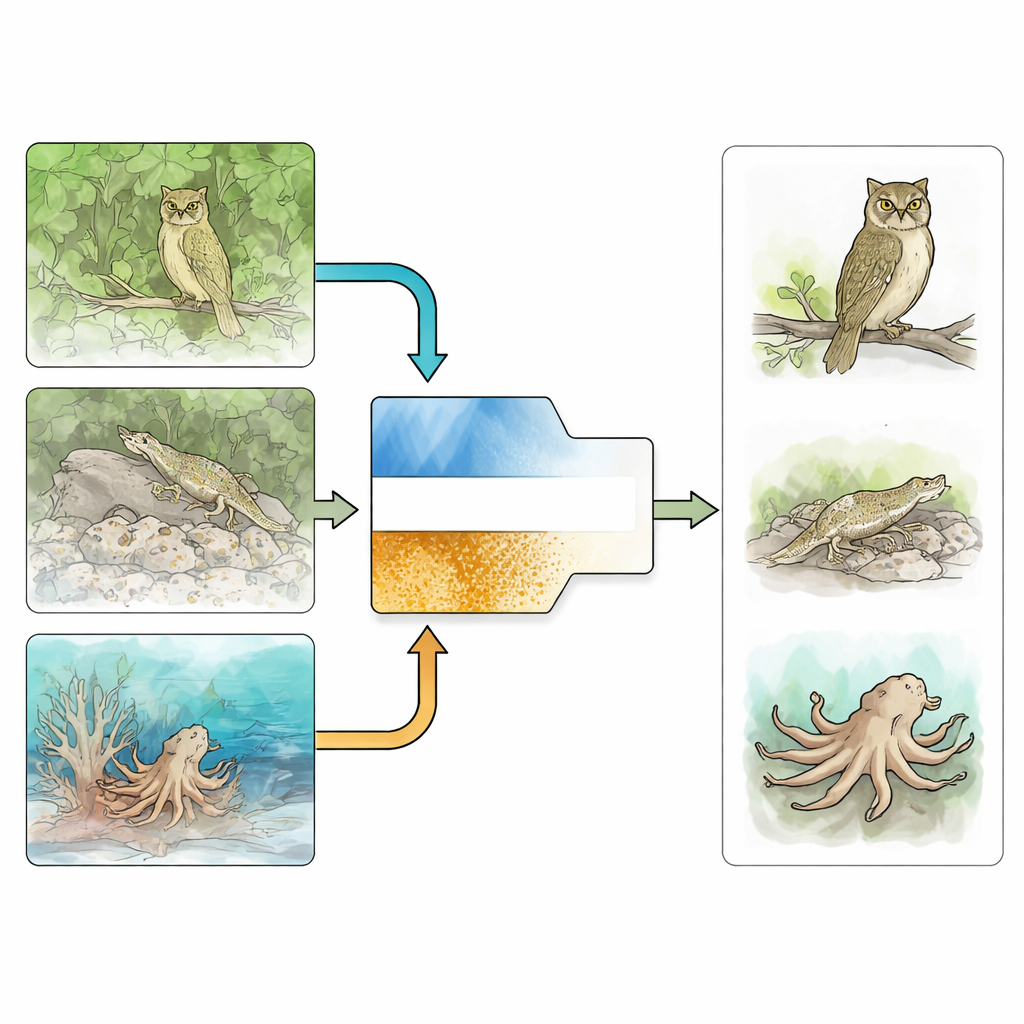
Vedere la foresta e gli alberi
Il rilevamento di oggetti camuffati è molto più difficile del rilevamento ordinario perché il bersaglio spesso corrisponde all’ambiente in colore, luminosità e forma. I metodi precedenti si basavano su indizi semplici progettati a mano come il movimento, i bordi o texture di base, che falliscono in scene affollate o rumorose. Gli approcci moderni basati sul deep learning hanno fatto progressi addestrando reti grandi su collezioni di immagini specializzate di animali mimetici e oggetti artificiali. Molti di questi metodi aggiungono suggerimenti extra, come delineare i contorni degli oggetti o stimare l’incertezza, ma possono facilmente essere sviati quando gli stessi bordi sono sfocati o ambigui — proprio la situazione tipica di un buon camuffamento.
Piccoli indizi di texture che smascherano il trucco
Gli autori sostengono che anche il camuffamento migliore lascia tracce riconoscibili nella finezza della texture di un’immagine — piccole differenze di grana, motivo o levigatezza che si rischia di non notare quando ci si concentra solo sui contorni. Partendo da questa idea, CTHINet separa l’apprendimento in due rami coordinati. Un ramo “contesto”, basato su un potente backbone transformer per la visione, cattura informazioni ampie e multi-scala sull’intera scena: come le regioni si relazionano tra loro, dove si trovano forme grandi e quali aree potrebbero plausibilmente contenere un oggetto. In parallelo, un ramo dedicato alla “texture” si concentra strettamente sui pattern superficiali sottili, addestrato con etichette di texture speciali che indicano alla rete quale tipo di dettaglio fine appartiene all’oggetto nascosto piuttosto che allo sfondo.
Come i due rami lavorano insieme
Far girare semplicemente due rami non basta; devono interagire in modo intelligente. CTHINet per prima cosa affina le feature di contesto usando un Modulo di Aggregazione delle Feature Multi-testa. Questo modulo suddivide l’informazione in più parti, ognuna elaborata con un diverso “livello di zoom” efficace, così il sistema può rispondere sia a insetti minuscoli sia ad animali di grandi dimensioni. Poi ricombina queste viste in modo che si informino a vicenda senza far esplodere il costo computazionale. Successivamente, una serie di Moduli di Interazione Mista Gerarchica collegano i flussi di contesto e texture. A ogni stadio, la rete raggruppa e miscela i canali di entrambi i rami, permette lo scambio di informazioni e poi li ripesa in modo che le combinazioni più informative vengano amplificate mentre quelle meno utili sono soppresse. Questa stratificazione da grosso a fine affina gradualmente il contorno di un oggetto nascosto e lo separa dai dettagli di sfondo distraenti.
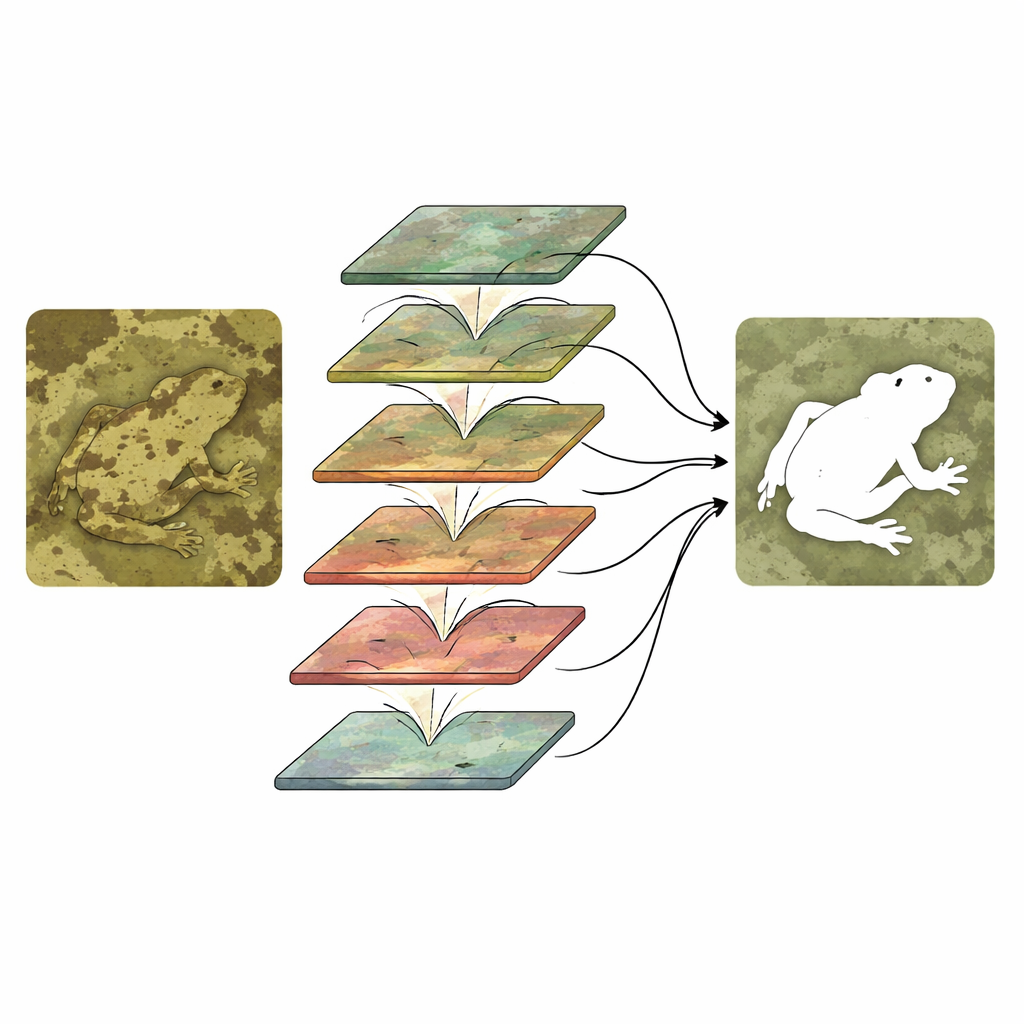
Dimostrare che funziona in natura e in clinica
Per testare CTHINet, i ricercatori lo hanno valutato su tre benchmark pubblici impegnativi di animali e oggetti camuffati, contenenti migliaia di immagini in ambienti naturali vari. Su diverse misure standard di accuratezza, il nuovo metodo ha costantemente superato più di venti sistemi di punta, soprattutto nelle scene difficili con bersagli piccoli, forte corrispondenza con lo sfondo o occlusioni parziali. Il team ha inoltre provato la stessa rete, con modifiche minime, su un compito medico: segmentare polipi in immagini di colonscopia. I polipi spesso si confondono con la parete intestinale in modo simile a come gli animali si mimetizzano nella vegetazione. Anche in questo caso, CTHINet ha fornito i migliori risultati tra diversi forti modelli per immagini mediche, suggerendo che il suo modo di combinare contesto e texture è utilmente generalizzabile.
Cosa significa per trovare l’improbabile da vedere
In termini quotidiani, CTHINet incarna un’idea semplice ma potente: per trovare qualcosa che è fatto per essere nascosto, un computer deve osservare sia il quadro generale sia i minimi dettagli di superficie, e lasciare che queste due viste si informino a vicenda passo dopo passo. Progettando una rete che separa chiaramente questi ruoli, per poi riunirli attraverso interazioni accuratamente scalate, gli autori ottengono un rilevamento più preciso dei bersagli camuffati e mostrano potenzialità per applicazioni mediche e industriali dove strutture importanti possono essere facilmente trascurate. Con l’aumento continuo dei dati visivi, sistemi sensibili a contesto e texture potrebbero diventare strumenti chiave per rivelare ciò che era destinato a rimanere invisibile.
Citazione: Wang, Z., Deng, Y., Shen, C. et al. Camouflaged object detection via context and texture-aware hierarchical interaction. Sci Rep 16, 9328 (2026). https://doi.org/10.1038/s41598-025-32409-9
Parole chiave: rilevamento di oggetti camuffati, visione artificiale, analisi della texture, segmentazione di immagini mediche, apprendimento profondo