Clear Sky Science · it
Un set di dati unificato per la progettazione di anticorpi e nanobody che include sequenza, struttura e dati di affinità di legame
Perché gli strumenti immunitari minuscoli e i big data contano
Gli anticorpi e i loro cugini più piccoli, i nanobody, sono i missili a guida di precisione dell’organismo contro infezioni e cancro. Oggi gli sviluppatori di farmaci cercano di progettare queste molecole al computer, proprio come gli ingegneri progettano aeromobili. Ma fino a tempi recenti il materiale di base per tale progettazione basata sull’intelligenza artificiale — dati affidabili sui componenti degli anticorpi, sulle loro forme e su quanto fortemente si leghino ai bersagli — era sparso in molti database incompatibili. Questo articolo presenta l’Antibody and Nanobody Design Dataset (ANDD), una risorsa pubblica unificata costruita per fornire ai ricercatori dati puliti e completi necessari a creare la prossima generazione di terapie mirate.
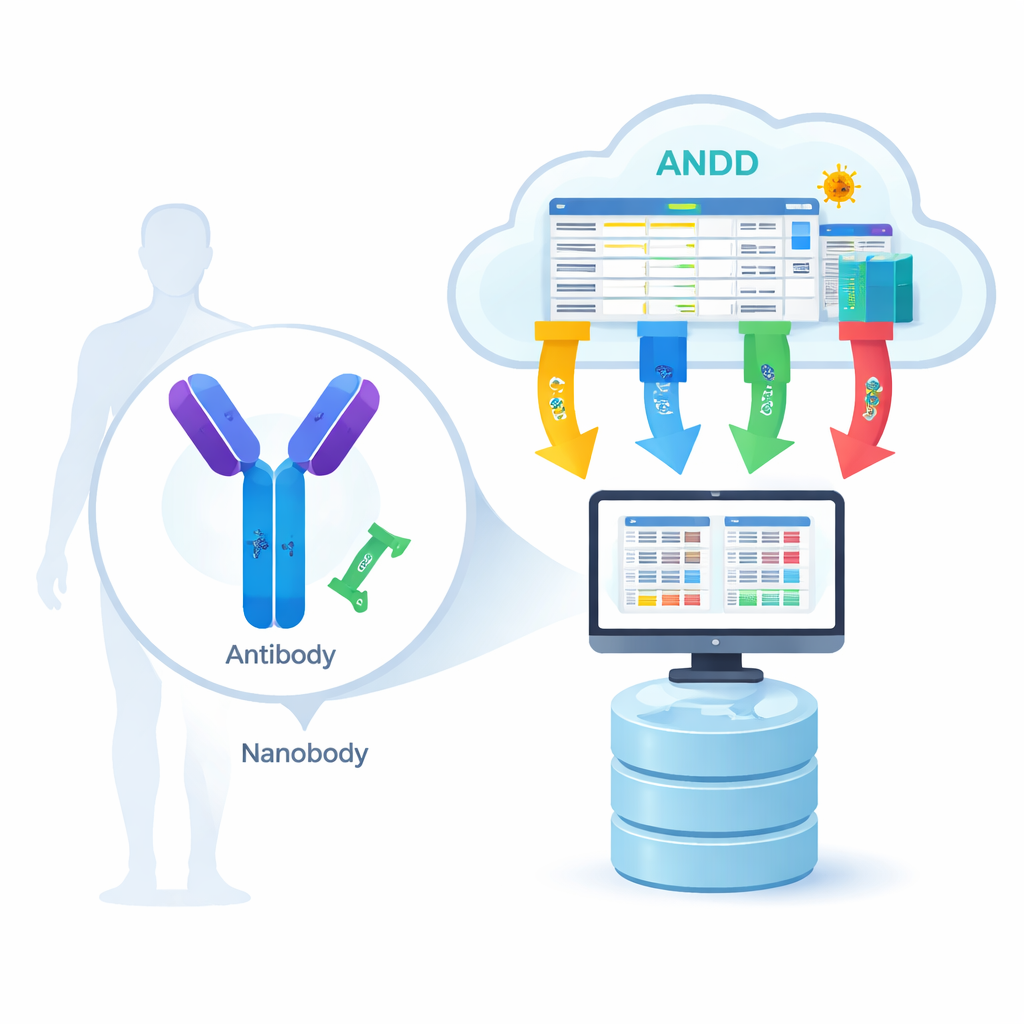
Da serratura e chiave biologica a progetto digitale
Gli anticorpi sono grandi proteine a forma di Y, mentre i nanobody sono versioni monopezzo molto più piccole presenti in animali come lama e alpaca. Entrambi riconoscono «serrature» specifiche su virus, cellule tumorali o altre proteine correlate a malattie. Perché i modelli computazionali imparino come avviene questo riconoscimento, servono quattro tipi di informazioni per molti esempi diversi: la sequenza di amminoacidi (l’elenco dei componenti), la struttura 3D (la forma), l’antigene (il bersaglio) e la forza di legame (quanto saldamente i due si uniscono). Finora, la maggior parte delle risorse includeva solo una o due di queste informazioni alla volta, costringendo gli scienziati a saltare tra database e a comporre manualmente i dati, rallentando il progresso e introducendo errori.
Riunire pezzi sparsi in una libreria organizzata
Il team di ANDD ha raccolto dati da 15 fonti principali, comprese banche dati dedicate ad anticorpi e nanobody, repository generali di proteine e persino documenti di brevetto. Questi input grezzi sono stati poi elaborati tramite una pipeline accuratamente scriptata: download, riformattazione in uno schema condiviso, verifica incrociata degli identificatori, rimozione dei duplicati e armonizzazione delle regole di denominazione. Quando i database differivano, sono state date priorità a fonti curate e a esperimenti diretti. Il risultato finale è una singola tabella più un insieme di file di struttura che collegano in modo coerente sequenza, struttura, bersaglio e informazioni di legame, con ogni record etichettato in modo che gli utenti possano tracciare esattamente la sua origine e come è stato processato.
Dettaglio stratificato per diverse esigenze di ricerca
Non tutte le voci in ANDD hanno lo stesso livello di dettaglio, quindi gli autori hanno organizzato la raccolta in livelli di dettaglio crescente. Al livello più ampio ci sono 48.683 voci di anticorpi e nanobody con informazioni di sequenza. Un ampio sottoinsieme aggiunge strutture 3D, e un sottoinsieme più piccolo include anche la sequenza delle proteine bersaglio. Il livello più dettagliato — migliaia di voci — aggiunge l’affinità di legame misurata o predetta. Per gli anticorpi, ad esempio, 18.464 voci hanno la sequenza, lo stesso numero combina sequenza e struttura, oltre 8.000 includono anche le sequenze degli antigeni, e 7.737 possiedono sequenza, struttura, antigene e dati di affinità completi. Esiste una gerarchia parallela per i nanobody, offrendo sia agli sperimentatori sia ai costruttori di modelli flessibilità: si possono scegliere dataset ampi e semplici o sottoinsiemi più piccoli e ricchi di informazioni.
Colmare i vuoti sull’affinità di legame
L’affinità di legame è cruciale per la progettazione di farmaci, ma i valori sperimentali sono scarsi e riportati in modo disomogeneo. Per affrontare questa lacuna senza confondere dati e previsioni, gli autori hanno usato uno strumento di deep learning specializzato, ANTIPASTI, per stimare l’affinità solo per le voci che avevano strutture ma mancavano delle misure sperimentali. Questi 2.271 valori predetti sono chiaramente etichettati e mantenuti separati dalle circa 7.000 misurazioni sperimentali. Il team ha poi verificato la coerenza complessiva usando un altro modello, AlphaBind, e confrontando misure matematicamente correlate di legame. Forti correlazioni e basso errore suggeriscono che i valori sperimentali curati sono affidabili e che i valori predetti seguono tendenze sensate senza essere considerati verità assolute.
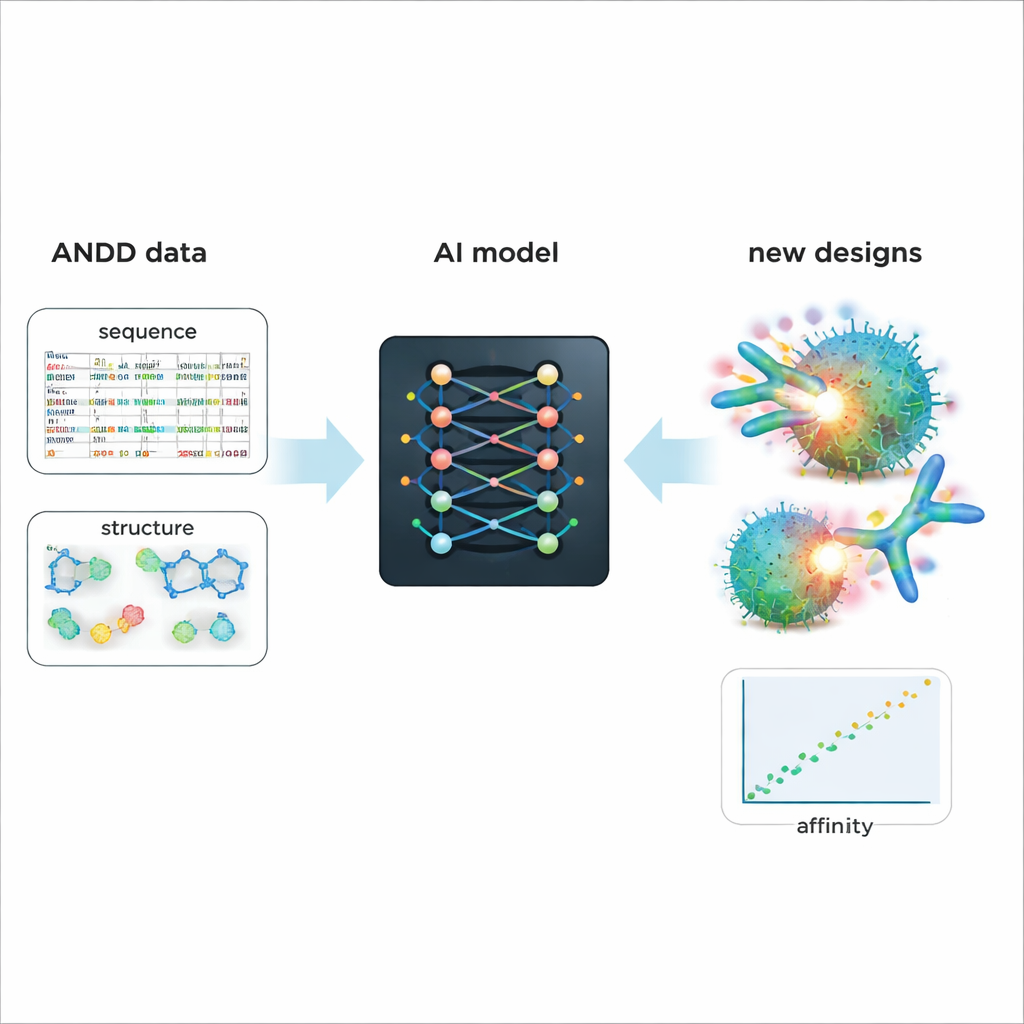
Alimentare una progettazione più intelligente dei farmaci futuri
Per dimostrare il valore pratico di ANDD, gli autori hanno messo a punto un modello generativo di IA esistente che progetta anticorpi e nanobody. L’addestramento sulle informazioni combinate di sequenza, struttura, bersaglio e affinità di ANDD ha portato a molecole generate con migliori previsioni di legame e forme più realistiche rispetto a un modello di riferimento addestrato su dati più vecchi e semplici. Oltre a questo caso di studio, ANDD è disponibile liberamente con una licenza permissiva, fornisce documentazione completa e una pipeline di costruzione riproducibile, ed è progettato per essere aggiornato regolarmente. Per i non specialisti, il messaggio principale è che ANDD trasforma un mosaico disordinato di dati sugli anticorpi in una libreria coerente e affidabile — offrendo agli strumenti di IA un punto di partenza molto migliore per progettare farmaci biologici più precisi ed efficaci.
Citazione: Wu, Y., Liu, X., Hrovatin, K. et al. A Unified Dataset for Antibody and Nanobody Design Including Sequence, Structure, and Binding Affinity Data. Sci Data 13, 295 (2026). https://doi.org/10.1038/s41597-026-06878-0
Parole chiave: progettazione di anticorpi, nanobody, affinità di legame, terapeutici biologici, scoperta di farmaci con IA