Clear Sky Science · it
Dataset PreprintToPaper: collegare i preprint di bioRxiv alle pubblicazioni su riviste
Perché la ricerca precoce conta per tutti noi
Molto prima che una scoperta scientifica appaia su una rivista patinata, spesso emerge come “preprint” – una versione preliminare del lavoro condivisa liberamente. Durante la pandemia di COVID‑19, questi preprint hanno influenzato titoli di giornale, dibattiti pubblici e persino politiche sanitarie. Eppure è stato sorprendentemente difficile tracciare quali studi iniziali sono poi diventati articoli formali su riviste e quali no. Questo articolo presenta il dataset PreprintToPaper, una mappa ampia e controllata che collega i preprint di scienze della vita sul server bioRxiv alle loro eventuali pubblicazioni su riviste, offrendo al pubblico, ai giornalisti e ai ricercatori una visione più chiara di come i risultati preliminari si muovono nel sistema scientifico.
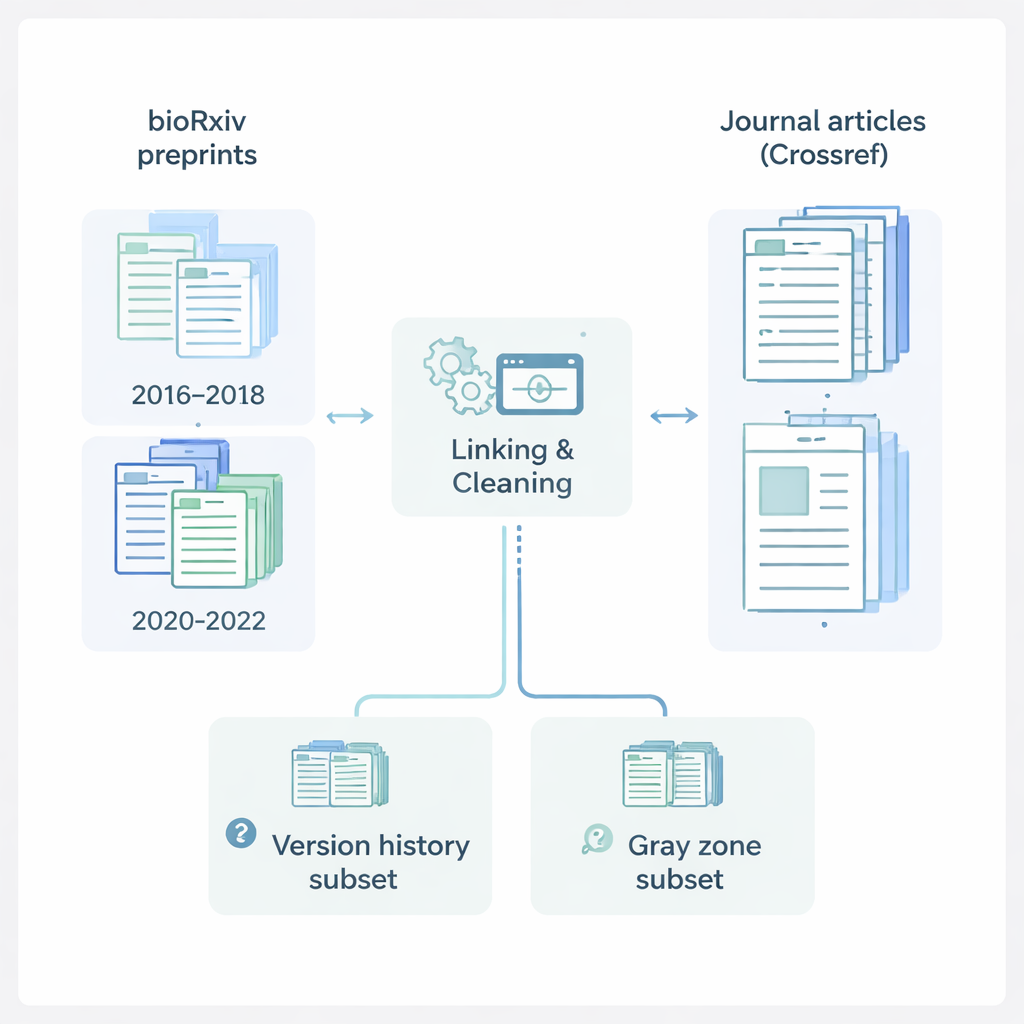
Seguire il percorso dalla bozza all’articolo
Gli autori si sono concentrati su bioRxiv, un importante server online dove i ricercatori delle scienze biologiche pubblicano i preprint. Hanno raccolto informazioni su 145.517 preprint da due finestre temporali chiave: 2016–2018, prima della pandemia di COVID‑19, e 2020–2022, durante la frenesia editoriale della pandemia. Per ciascun preprint hanno registrato dettagli come titolo, abstract, autori, istituzioni, area tematica, licenza e date di sottomissione. Hanno poi utilizzato Crossref, un registro centrale di articoli di riviste, per recuperare informazioni corrispondenti sui paper pubblicati: nomi delle riviste, date di pubblicazione e elenchi completi degli autori. Combinando queste fonti, hanno costruito un record ricco e unificato che segue uno studio dalla sua prima comparsa pubblica come preprint fino alla sua forma finale su una rivista scientifica.
Raggruppare i preprint in categorie chiare
Per interpretare questa ampia raccolta, il team ha classificato ogni preprint in uno di tre gruppi. I preprint “Pubblicati” avevano un chiaro collegamento digitale da bioRxiv a un articolo di rivista. Gli elementi “Solo preprint” erano pubblicati sul server ma non mostravano segni di essere stati pubblicati altrove. Il gruppo più interessante, chiamato “Zona grigia”, comprende i casi che sembrano essere stati pubblicati su una rivista ma mancano di un collegamento ufficiale su bioRxiv. Per cogliere come i preprint cambiano nel tempo, i ricercatori hanno anche costruito un file separato con la cronologia delle versioni elencando ogni versione disponibile per i preprint che avevano una versione originale e almeno un aggiornamento successivo. Questo consente ad altri di studiare come titoli, elenchi di autori e altri dettagli evolvono tra la prima bozza e l’ultima versione del preprint.
Individuare corrispondenze nascoste e verificarle manualmente
Molti preprint che in realtà sono stati pubblicati non ricevono mai un collegamento adeguato su bioRxiv, creando punti ciechi per chi cerca di tracciare la produzione scientifica. Per scoprire queste connessioni mancanti, gli autori hanno confrontato titoli e elenchi di autori dei preprint con i record di riviste presenti in Crossref. Hanno usato un punteggio di similarità compreso tra 0 e 1 per misurare quanto due titoli corrispondano; i potenziali collegamenti della Zona grigia richiedevano un punteggio di almeno 0,75. Hanno quindi raffinato questi candidati con misure basate sugli autori: quanto differivano i conteggi degli autori e quanto i nomi apparivano simili. Per verificare l’affidabilità di queste regole automatiche, due annotatori umani hanno esaminato manualmente 299 casi al limite. I loro giudizi hanno mostrato un forte accordo, e un modello statistico ha evidenziato che quando gli elenchi di autori corrispondono bene, un presunto collegamento è molto probabile che sia genuino.
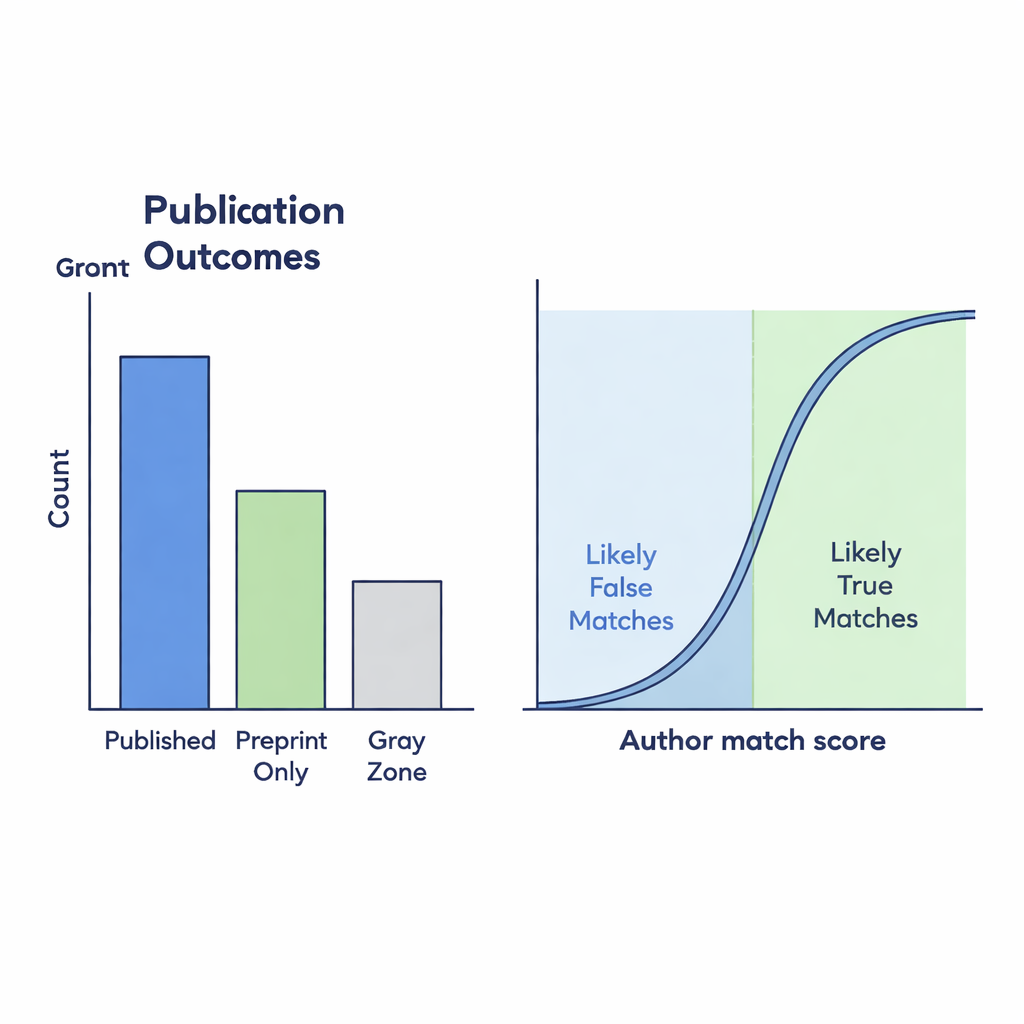
Cosa rivelano i numeri sulla produzione scientifica
Il dataset finale mostra come i modelli di preprinting e pubblicazione siano cambiati prima e durante la pandemia. Nel complesso contiene oltre 90.000 preprint chiaramente pubblicati, più di 35.000 che sembrano rimanere solo sul server e circa 19.000 casi della Zona grigia in cui il collegamento a un articolo di rivista ha richiesto lavoro investigativo. Se si conta solo il gruppo “Pubblicati” ufficialmente collegato, sembra che una quota molto più piccola di preprint si trasformi in articoli di rivista nel tempo. Ma quando si includono le probabilmente corrispondenze della Zona grigia — quelle con forte similarità degli autori — il calo dei tassi di pubblicazione è molto meno drastico. Questo suggerisce che i collegamenti mancanti nelle infrastrutture sottostanti possono fuorviare sulle reali trasformazioni del panorama scientifico.
Perché questa risorsa è utile oltre gli specialisti
Per i non specialisti, il messaggio principale è che i risultati scientifici precoci non scompaiono in una scatola nera. Con il dataset PreprintToPaper diventa possibile vedere quali risultati pubblicati rapidamente sopravvivono alla revisione tra pari, quanto tempo impiega questo percorso e quale tipo di studi non esce mai dalla fase di preprint. I decisori politici possono usare queste informazioni per valutare quanto funzionano le pratiche di scienza aperta; i giornalisti possono meglio giudicare quanto sia solido un dato risultato; e i ricercatori possono costruire strumenti che selezionino e riassumano un flusso travolgente di paper. In breve, questo dataset trasforma un flusso caotico di ricerche preliminari in un registro più tracciabile e responsabile di come le idee si muovono dalla prima pubblicazione alla pubblicazione raffinata.
Citazione: Badalova, F., Sienkiewicz, J. & Mayr, P. PreprintToPaper dataset: connecting bioRxiv preprints with journal publications. Sci Data 13, 301 (2026). https://doi.org/10.1038/s41597-026-06867-3
Parole chiave: preprint, pubblicazione scientifica, scienza aperta, ricerca sul COVID-19, bibliometria