Clear Sky Science · it
Multi-TPC: un dataset multimodale per conversazioni a tre partecipanti con voce, movimento e sguardo
Perché come ci muoviamo e guardiamo mentre parliamo conta
Quando le persone parlano faccia a faccia, fanno molto più che scambiarsi parole. Ci si sporge in avanti, si annuisce, si lancia uno sguardo agli altri e si fanno pause nei punti giusti. Questi movimenti sottili diventano ancora più importanti quando tre persone conversano insieme, perché attenzione e turni di parola cambiano continuamente. Eppure, fino a oggi, scienziati e ingegneri avevano pochissimi dati di alta qualità che mostrassero come voce, movimento del corpo e sguardo funzionino insieme nelle conversazioni di piccolo gruppo. Questo articolo presenta un nuovo dataset pensato per colmare quella lacuna e aiutare a costruire assistenti virtuali, robot sociali e strumenti di studio delle interazioni umane più naturali.
Una nuova finestra sulle conversazioni a tre persone
Gli autori presentano Multi-TPC, una collezione pubblica di conversazioni a tre persone registrate in laboratorio usando motion capture, eye tracker e microfoni individuali. A differenza di molte risorse precedenti che si concentrano su un singolo parlante o su conversazioni tra solo due persone, Multi-TPC cattura discussioni spontanee tra tre sconosciuti che stanno in piedi formando un triangolo e parlano di qualunque argomento desiderino. Sono incluse oltre 5,3 ore di registrazioni da 21 partecipanti giovani adulti, suddivise in 24 sessioni. Per ogni istante di queste conversazioni, il dataset fornisce informazioni dettagliate su come ogni persona parla, muove il corpo e orienta il proprio sguardo.
Come sono state catturate le conversazioni
Per costruire questo dataset, il team ha creato un sistema di registrazione ibrido. Ogni partecipante indossava una tuta per motion capture a tutto corpo puntinata di marker riflettenti in modo che un insieme di otto telecamere potesse tracciare postura, movimento della testa e gesti in tre dimensioni. Occhiali leggeri con eye-tracking, simili per sensazione agli occhiali comuni, misuravano dove ciascuno stava guardando nel proprio campo visivo. Microfoni wireless fissati vicino al collo registravano la voce di ciascun parlante su tracce audio separate. Prima della registrazione, i partecipanti sono stati calibrati nel sistema e istruiti a rimanere in punti fissi formando un triangolo equilatero a circa un metro di distanza. Una clapperboard, visibile alle telecamere, agli eye tracker e ai microfoni, ha fornito un segnale preciso per allineare tutti i dispositivi nel tempo, garantendo che movimento, sguardo e voce potessero essere abbinati fotogramma per fotogramma.
Pulizia, organizzazione e arricchimento dei dati
Raccogliere i segnali grezzi è stato solo il primo passo. I ricercatori hanno processato con cura i dati di movimento, etichettando tutti i marker e colmando piccoli vuoti usando interpolazione matematica mentre verificavano le posizioni dei marker vicini. Le registrazioni audio sono state ripulite con metodi di riduzione del rumore e poi elaborate con software di riconoscimento vocale per produrre trascrizioni parola per parola, successivamente corrette manualmente. I punti di sguardo misurati in pixel della camera sono stati convertiti in angoli 3D che mostrano dove ciascuno guardava nello spazio. Tutti i segnali sono stati sottocampionati a 60 fotogrammi al secondo e sincronizzati, quindi archiviati in formati semplici e aperti. Il dataset finale è organizzato per modalità—movimento, sguardo, audio, parole e caratteristiche prosodiche come intensità e intonazione—with regole chiare di denominazione dei file in modo che i ricercatori possano facilmente risalire a qualsiasi istante nel tempo attraverso tutti e tre i partecipanti.
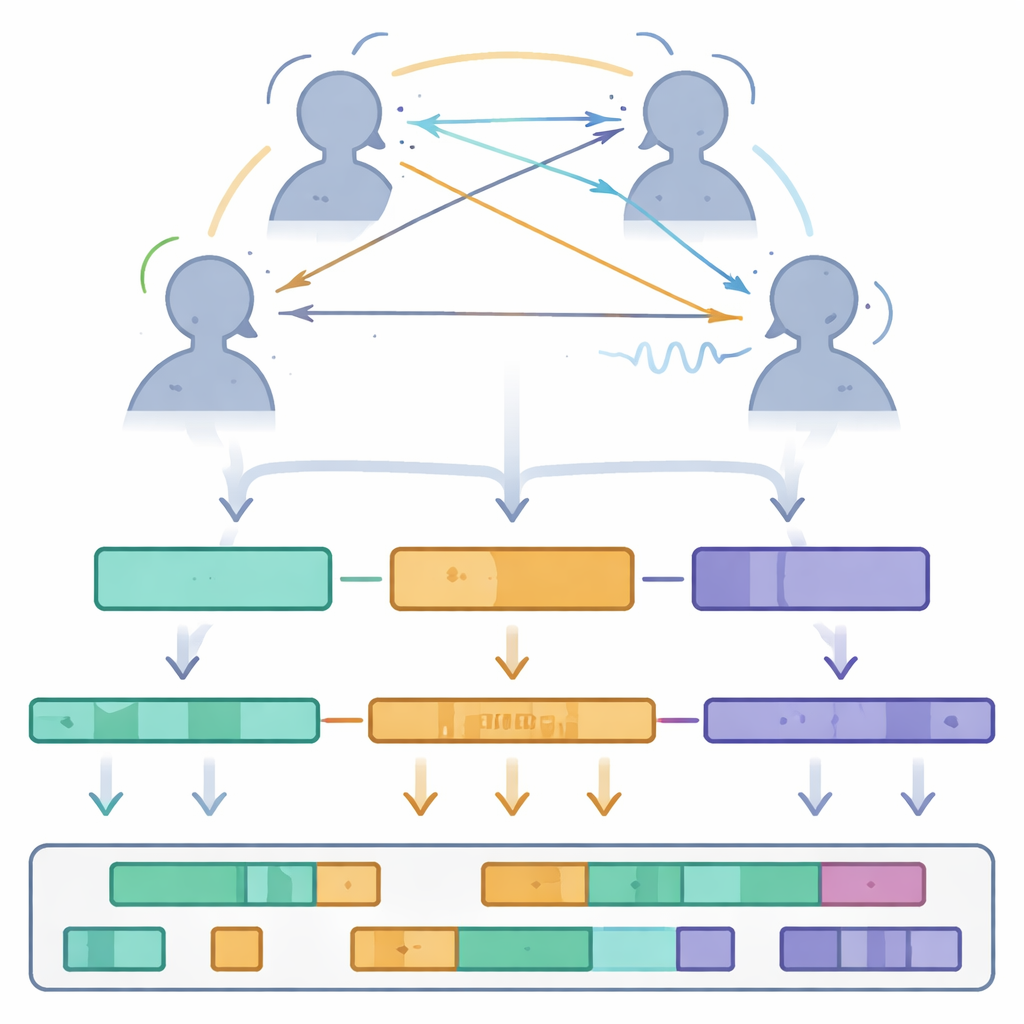
Cosa rivela il dataset sul parlare di gruppo
Usando Multi-TPC, gli autori hanno condotto un primo rilievo statistico di come si svolgono le conversazioni a tre. Hanno misurato i turni di parola e i silenzi, rilevando che un tipico turno di parola dura circa 2,7 secondi, separato da pause di poco più di un secondo. Hanno inoltre esaminato cenni del capo e scosse come forma di feedback dell’ascoltatore, rilevando in media circa un quarto di cenno o scossa al secondo—una prova che gli ascoltatori segnalano costantemente attenzione e atteggiamento senza pronunciare parole. L’analisi dello sguardo ha mostrato che le persone raramente fissano direttamente il volto altrui per lungo tempo. Piuttosto, spesso guardano leggermente di lato e i loro schemi di sguardo cambiano a seconda di chi sta parlando, se c’è una pausa o se più persone parlano contemporaneamente. Durante il parlato sovrapposto, lo sguardo dei partecipanti diventa più distribuito o si allontana da entrambi gli interlocutori, suggerendo incertezza su chi detiene il turno conversazionale.
Perché questa risorsa è importante per la tecnologia futura
Imballando tutti questi livelli informativi in un dataset ben documentato e condivisibile, Multi-TPC offre una nuova base per studiare come i piccoli gruppi gestiscono il passaggio di turno, l’attenzione e il feedback attraverso parole e movimento. Per il lettore comune, la conclusione è che la danza della conversazione—chi parla quando, chi guarda dove e come i cenni sottili modellano il flusso—è ora catturata in dettaglio. Per gli scienziati e gli sviluppatori, questo apre la porta a costruire personaggi virtuali e robot sociali che rispondono in modo più simile alle persone reali in contesti di gruppo, oltre a permettere studi più approfonditi su come ci coordiniamo tra noi tramite voce, corpo e sguardo.
Citazione: Lee, MC., Deng, Z. Multi-TPC: A Multimodal Dataset for Three-Party Conversations with Speech, Motion, and Gaze. Sci Data 13, 429 (2026). https://doi.org/10.1038/s41597-026-06819-x
Parole chiave: conversazione multimodale, gesto e sguardo, dataset di interazione sociale, passaggio di turno, agenti virtuali