Clear Sky Science · it
Un dataset per la super-risoluzione di video di opera tradizionale cinese basato sulla fusione di degradazione “Real-world+”
Ridare vita ai vecchi film d'opera
Molte registrazioni di opera tradizionale cinese esistono solo in forma video fragile e di bassa qualità. Il tempo, la polvere e le copie ripetute hanno sfocato i volti, attenuato i costumi e riempito le scene di rumore visivo. Questo articolo presenta un nuovo metodo per “pulire” e rendere più nitidi questi video in digitale, non riparando ogni film manualmente, ma costruendo una raccolta di addestramento specializzata per l’intelligenza artificiale. L’obiettivo è aiutare i computer a imparare come trasformare riprese sfuocate e invecchiate in immagini più chiare e vivide, preservando una parte importante della memoria culturale mondiale.
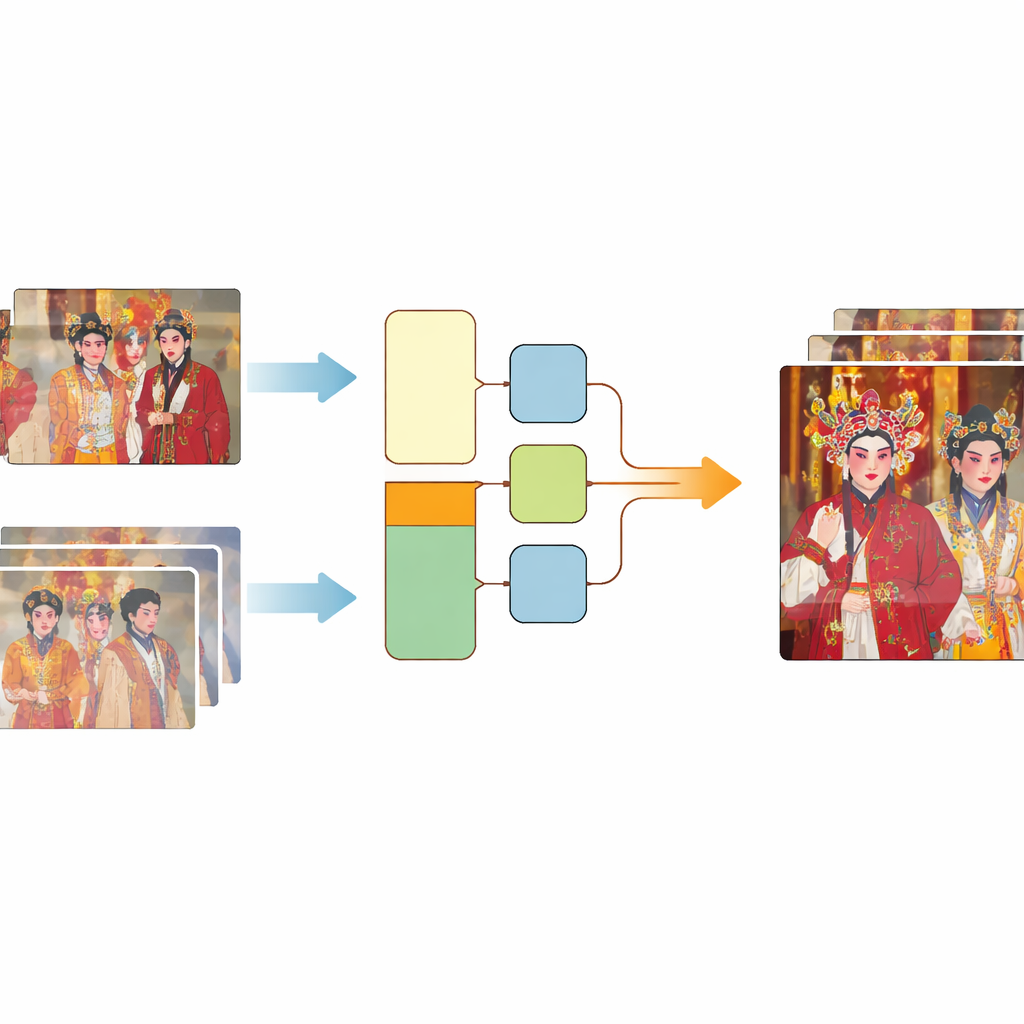
Perché i vecchi video d'opera sembrano così malridotti
L’opera tradizionale cinese, incluse famose forme come l’Opera di Pechino e il Kunqu, è stata riconosciuta dall’UNESCO come parte del patrimonio culturale dell’umanità. Eppure molti dei video sopravvissuti di queste rappresentazioni hanno attraversato un percorso lungo e durevole. Innanzitutto, l’attrezzatura di ripresa originale introduce sfocatura e rumore della camera. Poi, la conservazione su pellicola, nastro o dischi provoca graffi, deformazioni e perdita di dati. Infine, le copie ripetute, la compressione per Internet e la trasmissione di rete instabile aggiungono artefatti a blocchi, sfarfallio e cadute di frame. Il risultato non è una semplice sfocatura, ma un groviglio di molti tipi di danni diversi, che rende molto difficile per i metodi di restauro indovinare come dovrebbe apparire la scena originale.
Costruire coppie di fotogrammi sfocati e nitidi
I moderni metodi di “super-risoluzione” video addestrano i computer a prevedere un fotogramma nitido e dettagliato a partire da uno di bassa qualità. Per apprendere questa abilità servono molti esempi in cui un fotogramma sfocato corrisponde perfettamente allo stesso identico fotogramma in alta qualità. Le raccolte di addestramento esistenti si basano solitamente o su danni artificiali semplificati o su riprese reali che non sono perfettamente allineate tra versioni a bassa e alta qualità. Gli autori hanno creato una nuova risorsa chiamata CTOVSR partendo da quattro film d’opera tradizionale che erano stati restaurati professionalmente dalle bobine originali, raggiungendo risoluzioni molto elevate. Hanno quindi trovato versioni in definizione standard delle stesse esibizioni rilasciate online. Queste copie di qualità inferiore avevano subito l’intero processo di invecchiamento del mondo reale, rendendole immagini “prima” ideali.
Allineare ogni fotogramma con cura
Mettere in corrispondenza i video restaurati e quelli invecchiati non è stato affatto semplice. Differenze di frequenza dei fotogrammi, riprese mancanti, watermark aggiunti, bordi neri e rapporti d’aspetto mutevoli significavano che metodi automatici semplici non funzionavano. Il team ha estratto segmenti utilizzabili e poi ha realizzato un’attenta allineamento in tre fasi. Per prima cosa hanno usato uno strumento personalizzato, eye_comparer, per correggere manualmente problemi di sincronizzazione come perdita di fotogrammi, fotogrammi fuori ordine e “fotogrammi fantasma” alle transizioni di scena. In seguito hanno affrontato disallineamenti spaziali sovrapponendo i fotogrammi in un software di fotoritocco, allineando con precisione i contenuti e ritagliando bordi, loghi e sottotitoli preservando la massima porzione possibile della scena. Infine, hanno eseguito un controllo automatico usando una misura di similarità, mantenendo solo le coppie di fotogrammi quasi identiche nella struttura. Questo processo ha prodotto 250 coppie di sequenze reali di alta qualità che coprono centinaia di migliaia di fotogrammi.
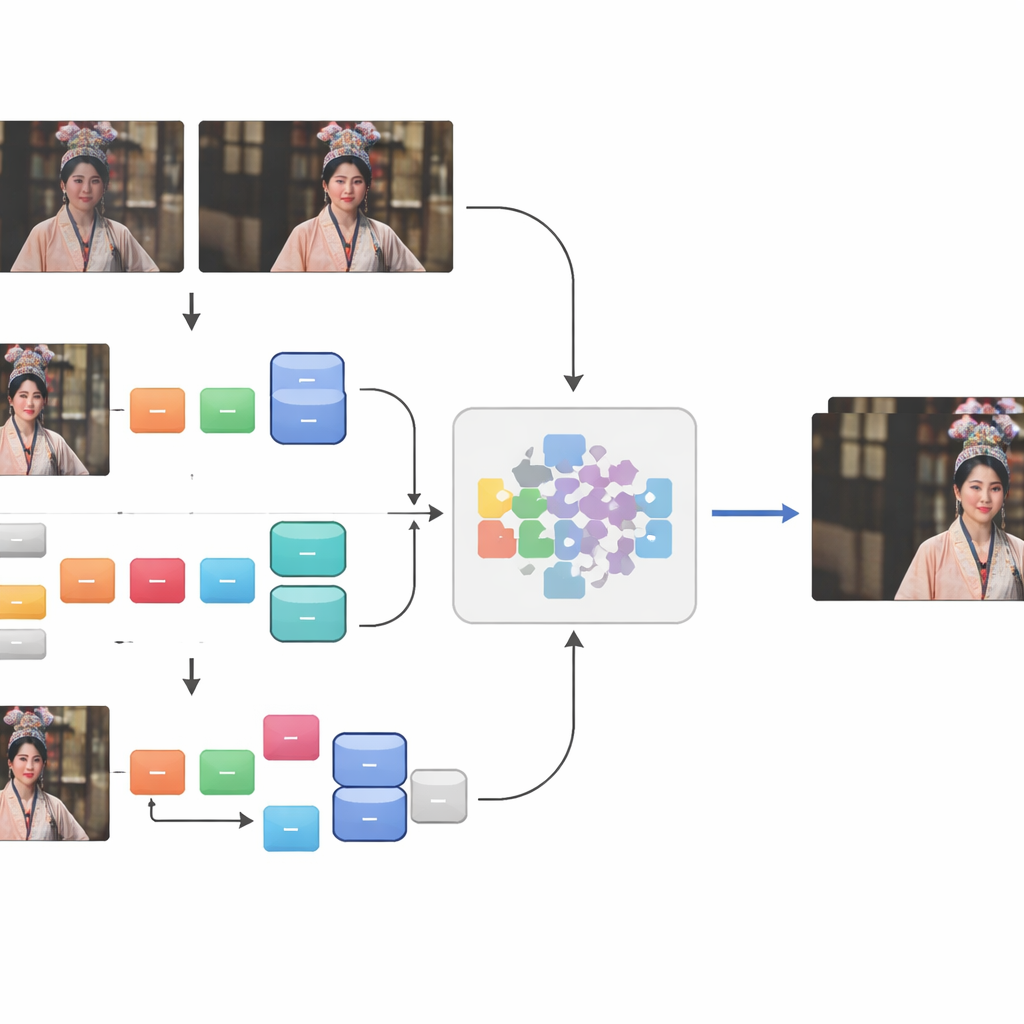
Fondere danni reali con usura simulata
Benché queste coppie accuratamente allineate catturassero un reale decadimento del mondo reale, erano ancora troppo poche per coprire la piena varietà di modi in cui un video può degradarsi. Per ampliare il materiale di addestramento, gli autori hanno aggiunto un secondo ingrediente: danni sintetici applicati a 41 ulteriori video d’opera in alta definizione. Hanno simulato danni spaziali — come sfocatura e rumore — attraverso una catena a due fasi di passaggi di degradazione, e danni temporali comprimendo i video con uno standard più vecchio largamente usato che riflette come molti clip online sono stati storicamente codificati. Fusione di questa porzione sintetica con le coppie “Real-world+”, hanno assemblato il dataset CTOVSR, che contiene 900 coppie di video a bassa–alta qualità strettamente allineate, ciascuna di 100 fotogrammi e che mostra una vasta gamma di opere, scene e condizioni di illuminazione.
Dimostrare il valore della nuova raccolta
Per verificare se CTOVSR aiuta davvero i computer a restaurare i vecchi video, gli autori hanno addestrato diversi modelli di super-risoluzione all’avanguardia usando solo questo dataset. Hanno confrontato i risultati con semplici metodi di ridimensionamento e hanno rilevato che i modelli addestrati producevano immagini molto più nitide, con dettagli dei costumi più definiti, trucco facciale più leggibile e meno artefatti visibili. Uno studio di ablation ha mostrato che combinare danni reali e sintetici è nettamente migliore che usare ciascuno dei due da solo. I ricercatori hanno anche testato i loro modelli addestrati su materiale completamente nuovo: clip d’opera invecchiate trovate online e perfino video di performance di altre culture, come l’opera italiana e la danza classica indiana. Osservatori umani hanno valutato i fotogrammi migliorati significativamente superiori rispetto agli originali o alle versioni upscalate di base, suggerendo che i modelli addestrati su CTOVSR possono generalizzare oltre il materiale specifico che contiene.
Salvare il patrimonio attraverso dati più intelligenti
In termini semplici, questo lavoro non introduce un altro algoritmo di restauro; offre invece il “materiale di pratica” preparato con cura di cui quegli algoritmi hanno bisogno per imparare. Abbinando meticolosamente versioni danneggiate e ad alta qualità di riprese d’opera tradizionale e arricchendole poi con usura simulata realistica, il dataset CTOVSR dà all’intelligenza artificiale una comprensione molto migliore di come i vecchi video decadono e di come dovrebbero apparire una volta restaurati. Questo approccio fornisce una via pratica non solo per ridare nuova vita visiva all’opera tradizionale cinese, ma anche per proteggere molte altre forme di video storico insostituibile dal dissolversi nell’oblio digitale.
Citazione: Xi, W., Qin, B., Zhang, Y. et al. A Chinese Traditional Opera Video Super-Resolution Dataset Based on the “Real-world+” Degradation Fusion. Sci Data 13, 387 (2026). https://doi.org/10.1038/s41597-026-06776-5
Parole chiave: super-risoluzione video, conservazione del patrimonio digitale, opera tradizionale cinese, restauro delle immagini, dataset di video degradati