Clear Sky Science · it
Un set di immagini istopatologiche ad alta ingrandimento per la diagnosi e la prognosi del carcinoma squamoso orale
Perché questa ricerca conta
Il cancro orale può nascondersi alla vista, iniziando come una piccola lesione in bocca e trasformandosi in una malattia potenzialmente letale. I medici si affidano alle immagini al microscopio dei tessuti per decidere quanto sia grave un tumore e qual è la probabilità che ritorni o si diffonda, ma l’interpretazione di queste immagini è un lavoro lento e impegnativo. Questo studio presenta una nuova e ricca raccolta di immagini pensata per aiutare i sistemi di intelligenza artificiale (IA) a leggere questi vetrini insieme ai patologi, con l’obiettivo a lungo termine di fornire ai pazienti risposte più rapide e accurate sulla loro malattia e sulle opzioni terapeutiche.
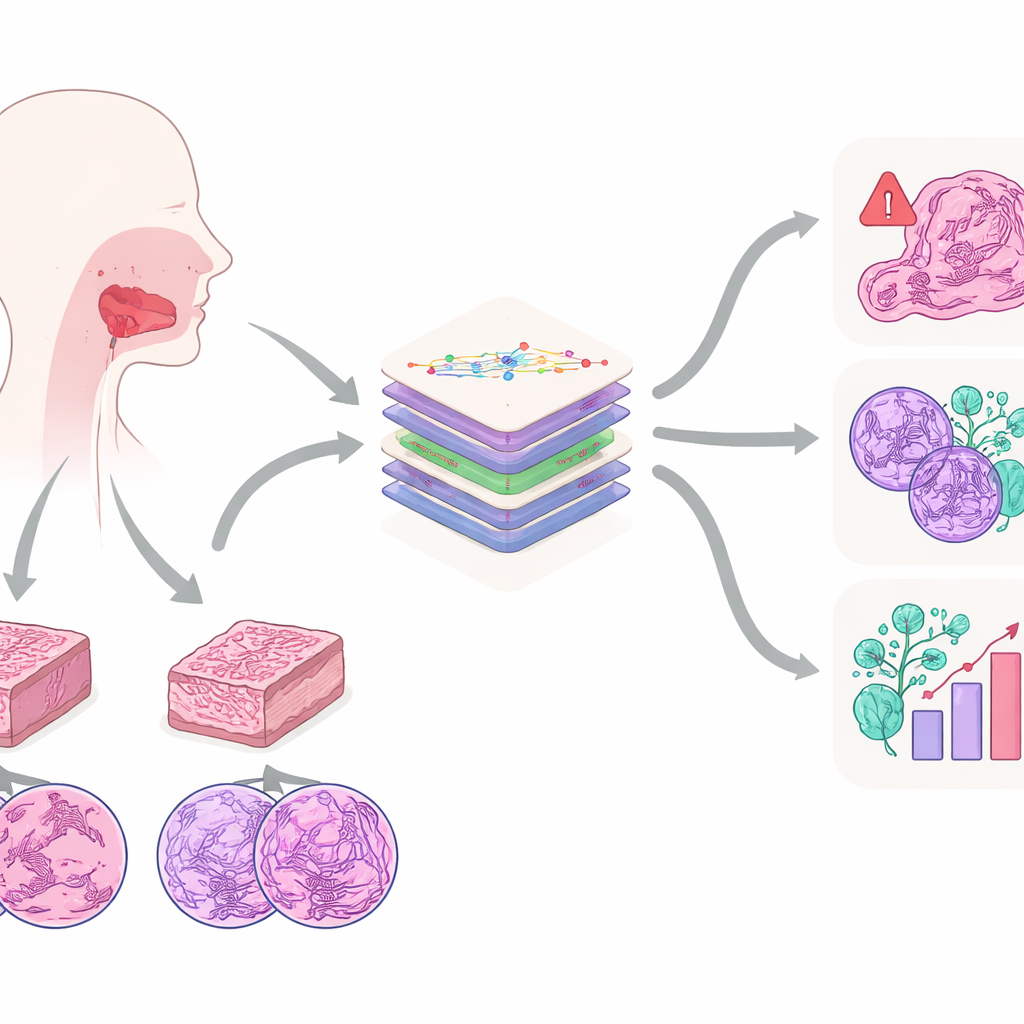
Uno sguardo ravvicinato a un cancro orale comune
Il lavoro si concentra sul carcinoma squamoso orale, uno dei tumori della bocca più frequenti e aggressivi. Spesso insorge in persone con una storia di consumo di tabacco o alcol e può estendersi nei tessuti circostanti e nei linfonodi del collo. Oggi, lo standard diagnostico rimane l’osservazione del patologo su fette di tessuto colorate al microscopio. Da queste sezioni gli esperti valutano quanto le cellule appaiono anomale, la profondità dell’invasione tumorale, se ha invaso nervi o vasi sanguigni e molti altri elementi che influenzano la sopravvivenza. Gli autori sostengono che questi schemi microscopici contengono molte più informazioni di quante un essere umano possa facilmente tenere a mente, rendendoli un bersaglio ideale per l’IA moderna.
Costruire un quadro più ricco dalle immagini dei tessuti
Per sbloccare queste informazioni, il team ha creato il dataset Multi‑OSCC: immagini al microscopio di 1.325 pazienti trattati per cancro orale in un singolo ospedale tra il 2015 e il 2022. Per ogni paziente, i patologi hanno preparato due blocchi di tessuto—uno dal centro del tumore e uno dal margine invasivo—e hanno acquisito immagini ad alta risoluzione a tre livelli di ingrandimento, simile a guardare una città da un aereo, da un tetto e da un angolo di strada. Questo ha prodotto sei immagini accuratamente selezionate per paziente, ciascuna contenente strutture chiave come nidi di cellule tumorali, spire di cheratina e nuclei cellulari altamente anomali. Insieme alle immagini, i ricercatori hanno raccolto cartelle cliniche dettagliate e follow‑up a lungo termine per verificare quali tumori sono ricomparsi o si sono diffusi.
Sei domande che interessano davvero i medici
Ciò che distingue Multi‑OSCC è che rispecchia le domande cliniche reali invece di concentrarsi su un’unica etichetta. Ogni paziente del dataset è annotato per sei esiti importanti. Uno è se il tumore è recidivato entro due anni dall’intervento chirurgico, una finestra critica in cui si verificano la maggior parte delle recidive. Un altro è se le cellule tumorali avevano già raggiunto i linfonodi del collo, informazione che guida le decisioni su interventi chirurgici cervicali estesi. Quattro etichette aggiuntive catturano quanto sono differenziate le cellule tumorali, la profondità di invasione del tumore e se è penetrato nei vasi sanguigni o si è sviluppato lungo i nervi—indizi sottili ma potenti sulla pericolosità del cancro. Questa impostazione permette ai modelli di IA di apprendere non solo la differenza “tumore versus normale”, ma un quadro più completo di rischio e gravità.
Insegnare all’IA a leggere vetrini complessi
I ricercatori hanno quindi valutato come diverse strategie di IA gestiscono questo dataset impegnativo. Hanno confrontato diversi backbone di riconoscimento delle immagini, inclusi sia le reti convoluzionali classiche sia i più recenti modelli basati su transformer, e hanno scoperto che i transformer pre‑addestrati specificamente su immagini di patologia hanno reso meglio nel complesso. Hanno testato modi diversi di combinare le informazioni dalle sei immagini per paziente e hanno scoperto che una strategia semplice—estrarre caratteristiche da ogni immagine e poi concatenarle—ha superato schemi di fusione più elaborati. Hanno inoltre esaminato come la standardizzazione del colore delle colorazioni influenzi le prestazioni, rivelando che mantenere il colore originale era cruciale per predire la recidiva, mentre una lieve normalizzazione del colore aiutava negli altri compiti diagnostici.
Limiti, sorprese e prossimi passi
Una sorpresa è stata che addestrare un singolo modello di IA per affrontare tutte e sei le domande contemporaneamente non ha ancora superato i modelli addestrati separatamente per ciascun compito. Un’altra è che i dettagliati frammenti microscopici, pur ricchi di informazioni cellulari, mancano ancora della visione architettonica ampia che offrono le immagini dell’intero vetrino. Nonostante ciò, i modelli addestrati sulle immagini di Multi‑OSCC hanno chiaramente superato i modelli che utilizzavano soltanto dati clinici come età, abitudini e storia medica, soprattutto nella previsione della recidiva tumorale. Gli autori presentano Multi‑OSCC come punto di partenza: un dataset pubblico e ben documentato che altri possono usare per sviluppare e confrontare metodi. Per i pazienti, la promessa a lungo termine è che gli strumenti futuri costruiti su questa risorsa possano aiutare i medici a individuare con maggiore affidabilità quali tumori orali sono più probabili che ritornino o si diffondano, portando a terapie più personalizzate e, in ultima analisi, a migliori probabilità di sopravvivenza.
Citazione: Guan, J., Guo, J., Chen, Q. et al. A High Magnifications Histopathology Image Dataset for Oral Squamous Cell Carcinoma Diagnosis and Prognosis. Sci Data 13, 371 (2026). https://doi.org/10.1038/s41597-026-06736-z
Parole chiave: cancro orale, immagini istopatologiche, intelligenza artificiale, deep learning, dataset di immagini mediche