Clear Sky Science · it
Un dataset delle citazioni scientifiche nelle Office Actions dell'Ufficio Brevetti USA
Perché le citazioni di brevetti contano per l'innovazione quotidiana
Quando senti parlare di un nuovo dispositivo, farmaco o tecnologia per l'energia pulita, dietro c'è quasi sempre una traccia di idee. Gran parte di quella traccia è registrata nei brevetti e nei documenti che essi citano. Questo articolo presenta un ampio nuovo dataset che rivela, con un livello di dettaglio inconsueto, quali lavori di ricerca scientifica gli esaminatori di brevetti utilizzano quando decidono se un'invenzione merita protezione. Aprendo questa finestra nascosta sul processo di esame, gli autori offrono a ricercatori, decisori politici e anche cittadini curiosi un nuovo modo per studiare come la conoscenza scientifica alimenti l'innovazione nel mondo reale.
Uno strato nascosto nel processo dei brevetti
La maggior parte degli studi sui brevetti analizza solo le citazioni pubblicate in prima pagina dei brevetti concessi. Questi elenchi sembrano semplici, ma sono il risultato finale di un complesso scambio tra richiedenti ed esaminatori governativi. Nel corso di questo dialogo, gli esaminatori emettono lettere formali chiamate Office Actions, in cui spiegano perché un brevetto dovrebbe essere accettato o rifiutato e fanno riferimento a lavori precedenti che ritengono importanti. Molti di questi elementi citati, in particolare gli articoli scientifici, non compaiono mai nel brevetto finale. Fino a oggi sono stati difficili da reperire in blocco, perciò la ricerca ha in gran parte ignorato questo ricco registro di come vengono prese le decisioni.
Costruire una nuova mappa dalle Office Actions
Gli autori attingono a un tesoro di dati delle Office Action pubblicati dall'U.S. Patent and Trademark Office e ospitati su Google Cloud. Da milioni di riferimenti, isolano circa 850.000 voci che non puntano ad altri brevetti, ma a fonti esterne come articoli di riviste, libri, siti web e manuali di prodotto. Progettano uno schema con 14 categorie di uso comune — che spaziano da libri e atti di conferenze a pagine web e documentazione di prodotto — e poi addestrano un modello di machine learning per classificare ogni citazione in una di queste tipologie. Questo modello, perfezionato usando esempi etichettati con l'aiuto di un avanzato sistema linguistico, classifica quasi 847.000 stringhe di citazione uniche.
Da riferimenti disordinati a record di ricerca puliti
Identificare quali citazioni sono scientifiche è solo il primo passo. I riferimenti reali sono disordinati: i titoli possono essere incompleti, gli anni digitati male e i numeri di pagina confusi. Per trasformare questo groviglio in dati utilizzabili, il team inserisce le stringhe grezze in uno strumento specializzato che le scompone in elementi come autore, anno, rivista e intervallo di pagine, applicando regole di pulizia accurate. Successivamente collegano questi record puliti a OpenAlex, un ampio database aperto di pubblicazioni scientifiche, usando due strategie. Quando è disponibile un titolo, cercano per titolo e mantengono solo corrispondenze ad alta confidenza; quando non lo è, si basano su combinazioni di nomi degli autori, rivista, anno e pagine. Se OpenAlex non trova una corrispondenza, ricorrono a Crossref, un'altra fonte principale di identificatori di pubblicazioni, e ritornano a OpenAlex usando eventuali digital object identifier scoperti.
Quanto è affidabile il nuovo dataset?
Poiché questa risorsa è pensata per supportare studi futuri, gli autori dedicano notevoli sforzi a testarne l'accuratezza. Il loro classificatore assegna correttamente le referenze al tipo giusto in circa il 92 percento dei casi nel complesso, e funziona particolarmente bene per le classi più comuni come articoli di riviste e brevetti. Per la fase di matching, verifiche manuali mostrano che le ricerche basate sul titolo diventano più accurate con l'aumentare del punteggio di corrispondenza, raggiungendo la metà degli anni '90 percentile nel gruppo migliore, mentre le ricerche basate su metadata dettagliati risultano corrette nel 99 percento dei casi in un campione. I controlli incrociati dei record recuperati tramite Crossref mostrano anch'essi un accordo quasi perfetto. Gli autori sono trasparenti sui punti più deboli — come categorie rare quali tesi o rapporti tecnici — e incoraggiano gli utilizzatori a perfezionare queste parti quando necessario.
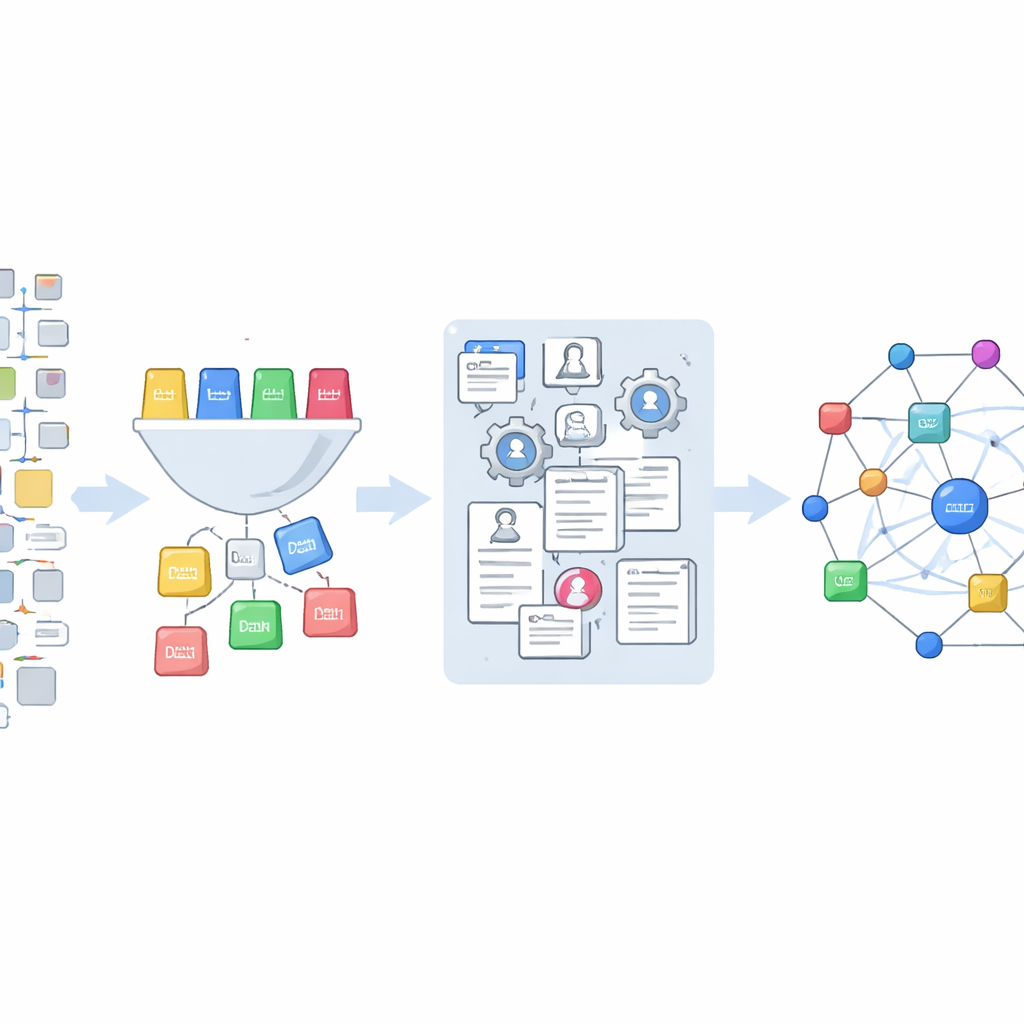
Nuovi modi per studiare come la scienza guida la tecnologia
Il dataset finale collega circa 265.000 riferimenti scientifici estratti dalle Office Action ad applicazioni di brevetto statunitensi individuali e a ricchi record di pubblicazione in OpenAlex. Questo permette ai ricercatori di porre nuovi tipi di domande: quanto fanno affidamento diversi gruppi di esaminatori o aree tecnologiche su articoli scientifici? Quali studi sono considerati importanti durante l'esame ma scompaiono dal brevetto finale? I brevetti abbandonati si basano su una diversa porzione del registro scientifico rispetto a quelli concessi? Poiché tutto il codice e i dati sono rilasciati apertamente, altri possono adattare gli strumenti, estendere la copertura e affinare le classificazioni. In termini semplici, questo lavoro trasforma un insieme oscuro e frammentato di documenti legali in una mappa chiara e riutilizzabile di come scienza e tecnologia si incontrano all'interno del sistema dei brevetti.
Citazione: Higham, K., Kotula, H., Scharfmann, E. et al. A dataset of scientific citations in U.S. patent Office Actions. Sci Data 13, 325 (2026). https://doi.org/10.1038/s41597-026-06720-7
Parole chiave: citazioni di brevetti, office actions, letteratura scientifica, dati sull'innovazione, OpenAlex