Clear Sky Science · it
Un dataset di Named Entity Recognition cinese per il patrimonio culturale immateriale
Perché proteggere le tradizioni viventi richiede una lettura intelligente
In tutto il mondo, tradizioni viventi come la musica popolare, l’artigianato e le feste locali rischiano di scomparire dalla vita quotidiana. In Cina esistono già enormi quantità di testi che descrivono queste pratiche, ma la maggior parte è dispersa in lunghe pagine web difficili da cercare o analizzare per le persone — e anche per i computer. Questo studio presenta un dataset in lingua cinese costruito con cura e un modello avanzato di intelligenza artificiale in grado di individuare automaticamente informazioni chiave in quei testi, come i nomi delle arti, i maestri artigiani, i materiali e i luoghi. Insieme, offrono nuovi strumenti per preservare e studiare il patrimonio culturale immateriale su scala digitale.
Trasformare testo disordinato in conoscenza organizzata
L’idea centrale del lavoro è una tecnologia chiamata riconoscimento delle entità nominate, che insegna ai computer a evidenziare elementi importanti nel testo: persone, luoghi, tempi, organizzazioni e così via. Per il patrimonio culturale immateriale questo significa anche riconoscere tipi di entità specifiche, come i nomi di progetti di tutela, tecniche artigianali particolari e i materiali impiegati. Il problema è che, fino ad oggi, non esisteva un dataset pubblico specifico per questo dominio in cinese, e i sistemi generici faticavano con descrizioni vivide, espressioni poetiche e forme regionali presenti nei documenti sul patrimonio.
Costruire una collezione mirata di testi sul patrimonio
Per colmare questa lacuna, gli autori hanno raccolto un nuovo dataset, chiamato ICH-NER, preso dalla rete ufficiale cinese del Patrimonio Culturale Immateriale. Si sono concentrati su voci legate all’artigianato — come tessuti tradizionali, ceramiche, lavori in metallo e intaglio — perché queste descrizioni sono ricche di dettagli su processi e materiali. Dopo aver eliminato avvisi e duplicati, hanno definito otto categorie chiave di entità: nomi degli elementi di patrimonio, luoghi, persone, organizzazioni, periodi temporali, gruppi etnici, materiali e tecniche artigianali. Ogni carattere cinese nei testi è stato etichettato con un codice semplice che indica se appartiene a un’entità e, in caso affermativo, di quale tipo. In totale il dataset contiene 7.779 campioni e più di 21.000 entità etichettate, costituendo un solido benchmark per ricerche future.
Regole accurate per una etichettatura coerente
Poiché non esisteva un sistema di classificazione standard per questo tipo di testi, i ricercatori hanno prima elaborato linee guida dettagliate basate sulle liste nazionali del patrimonio e sulle descrizioni ufficiali. Hanno condotto una fase pilota per gestire i casi ambigui, come luoghi che fanno parte anche di nomi di progetti, o frasi annidate dove un’entità è contenuta in un’altra. Un singolo annotatore formato ha quindi etichettato l’intero dataset usando software open source, rivedendo più volte i lavori precedenti per correggere incoerenze. I dati finali sono suddivisi in set di addestramento e di sviluppo, con attenzione a mantenere proporzioni simili di ogni tipo di entità e una buona mescolanza di termini regionali e stili di scrittura in entrambe le parti.
Progettare un modello di IA sintonizzato sul linguaggio del patrimonio
Accanto al dataset, lo studio propone un modello di riconoscimento specializzato che combina diversi componenti moderni di IA. Prima, un potente codificatore linguistico (RoBERTa) converte i caratteri cinesi in rappresentazioni numeriche contestualizzate che riflettono l’uso delle parole nel testo circostante. Poi, un modulo Kolmogorov–Arnold Network impara pattern sottili e non lineari — per esempio come certi materiali tendono ad associarsi a particolari tecniche o regioni. Uno strato di multi‑head attention esamina quindi le relazioni su tutta la frase da più angolazioni e, infine, uno strato di decodifica sceglie la sequenza di tag di entità più probabile. Questa architettura è pensata per gestire frasi lunghe e complesse, piene di metafore e riferimenti culturali stratificati.
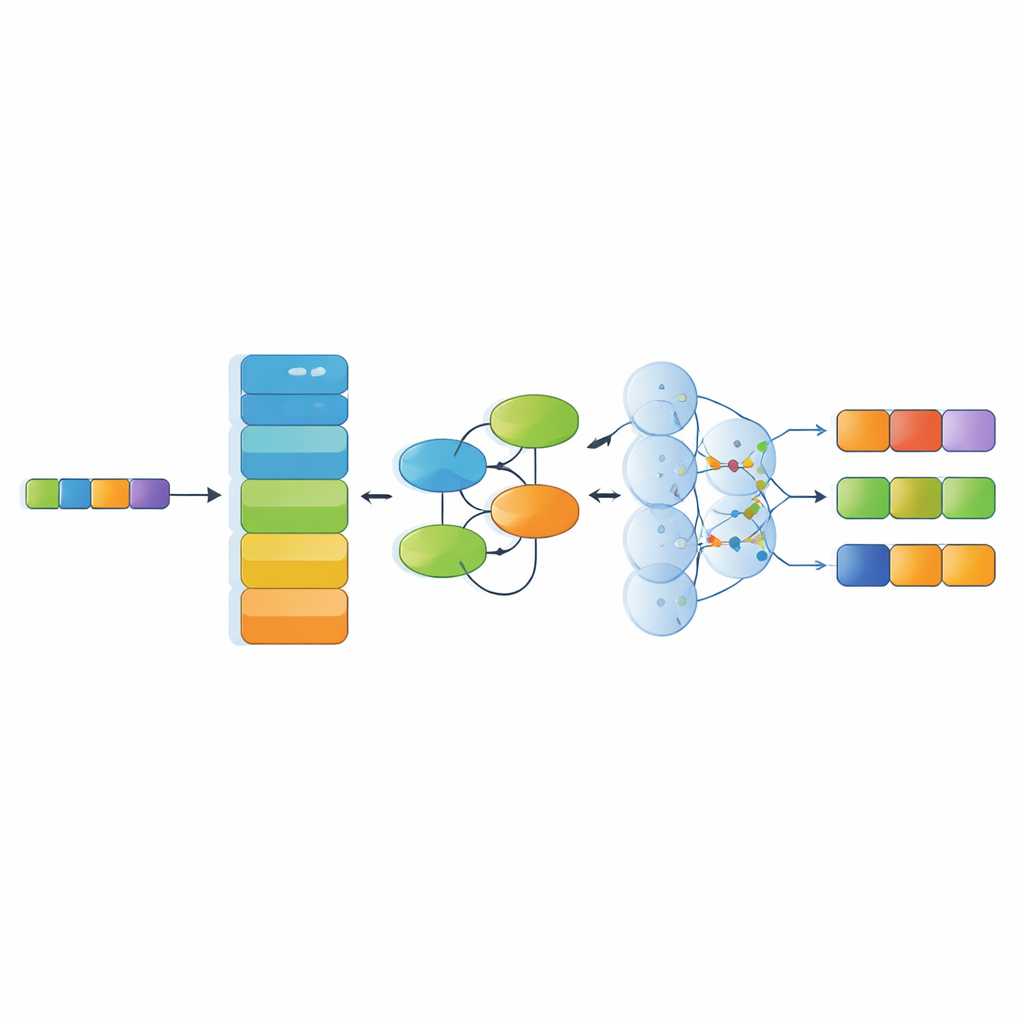
Quanto il sistema comprende il testo sul patrimonio
Gli autori hanno confrontato il loro modello con diversi forti baseline comunemente usati nella ricerca linguistica, inclusi sistemi basati su reti ricorrenti, strutture a reticolo per il testo cinese e un metodo recente che tratta le entità come segmenti raffinati passo dopo passo. Sul dataset ICH-NER, i metodi che si basano su modelli linguistici pre‑addestrati moderni hanno nettamente superato gli approcci più datati. Il loro sistema combinato RoBERTa–KAN–attention–decoder ha raggiunto il miglior equilibrio complessivo tra precisione e richiamo, soprattutto per categorie complesse come materiali, organizzazioni e tecniche artigianali, dove i dati sono relativamente scarsi e le descrizioni spesso intricate o ambigue.
Cosa significa per la cultura vivente nell’era digitale
In termini pratici, il nuovo dataset e il modello rendono più semplice per i computer estrarre chi, cosa, dove e quando da descrizioni ricche di arti tradizionali. Queste informazioni strutturate possono alimentare knowledge graph, mappe interattive o strumenti di ricerca che aiutano ricercatori, curatori e pubblico a esplorare come le tecniche si diffondono, come famiglie o regioni influenzano un’arte e come le pratiche evolvono nel tempo. Pur essendo un lavoro tecnico, il suo impatto è umano: offre un modo per trasformare descrizioni disperse e legate al testo di tradizioni viventi in conoscenza organizzata che può sostenere meglio la conservazione e la comprensione del patrimonio culturale immateriale.
Citazione: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
Parole chiave: patrimonio culturale immateriale, riconoscimento delle entità nominate, elaborazione della lingua cinese, dataset culturali, preservazione digitale