Clear Sky Science · it
Manifesto dei Dati Biomedici: una documentazione leggera dei dati per aumentare la trasparenza per AI/ML
Perché note dati più intelligenti contano per la tua salute
Man mano che ospedali e ricercatori affrettano l’uso dell’intelligenza artificiale per prevedere malattie e guidare i trattamenti, la qualità dei dati che alimentano questi strumenti determina silenziosamente chi beneficia — e chi può restare escluso. Questo articolo presenta un modo pratico per “etichettare la scatola” dei dataset biomedici, così chiunque costruisca sistemi di AI può vedere rapidamente da dove provengono i dati, chi rappresentano e come dovrebbero — e non dovrebbero — essere usati. Snellendo questo tipo di documentazione, gli autori mirano a rendere l’AI medica più equa, sicura e affidabile.
Le storie nascoste nei dati medici
La maggior parte dei grandi dataset biomedici — raccolte di risultati di laboratorio, immagini o esiti dei trattamenti — non è stata creata pensando all’AI. Spesso mancano registrazioni chiare su come i dati sono stati raccolti, quali pazienti sono stati inclusi o cosa è stato modificato nel tempo. Questi dettagli mancanti possono nascondere bias, come la sottorappresentazione di alcuni gruppi o la registrazione incoerente di informazioni chiave. Quando dati simili vengono usati per addestrare sistemi di machine learning, gli strumenti risultanti possono funzionare bene per alcuni pazienti e male per altri, rafforzando le disparità di cura esistenti. Gli autori sostengono che una documentazione migliore e standardizzata è essenziale per scoprire e gestire questi rischi prima del dispiegamento degli algoritmi.
Combinare le migliori idee in una guida semplice
Esistono già in ambito AI diversi approcci di “schede informative” sui dati, come Datasheets for Datasets, Data Cards e HealthSheets. Ognuno propone domande strutturate su scopo, contenuto, modalità di raccolta e limiti di un dataset. Tuttavia, sono stati in gran parte progettati da informatici per dataset specifici per AI e possono essere lunghi e difficili da compilare per i ricercatori biomedici impegnati. Per evitare di reinventare la ruota, il team ha mappato e armonizzato i campi di quattro modelli ampiamente citati, costruendo una lista consolidata di 136 domande che catturava i concetti più importanti eliminando le sovrapposizioni. Hanno poi affinato l’elenco fino a 100 campi raggruppati in sette categorie intuitive, che vanno dalle informazioni di base e dagli usi dei dati a questioni come etica, vincoli legali e modalità di creazione delle etichette.
Ascoltare le persone che usano e creano i dati
Successivamente, i ricercatori hanno chiesto a stakeholder biomedici reali — tra cui clinici, biologi di laboratorio, manager dei dati ed esperti computazionali — di valutare quanto fosse essenziale ciascun campo di documentazione per il loro lavoro. Ventitré partecipanti di una rete di ricerca oncologica multicentrica hanno completato il sondaggio. Il team ha raggruppato i rispondenti in due «personas» ampie: chi è più vicino alla raccolta dei dati al banco o al letto del paziente e chi invece gestisce, cura o analizza i dati. Sono emerse differenze chiare nelle priorità. Per esempio, entrambi i gruppi hanno valutato con grande importanza sapere quando un dataset è stato aggiornato l’ultima volta e quando potrebbe cambiare di nuovo. Ma solo i manager dei dati e gli esperti computazionali hanno dato forte priorità ai dettagli su come sono state assegnate le etichette o su come saranno gli aggiornamenti futuri, mentre i clinici e gli scienziati di laboratorio hanno dato più rilievo agli usi previsti e inadatti dei dati.
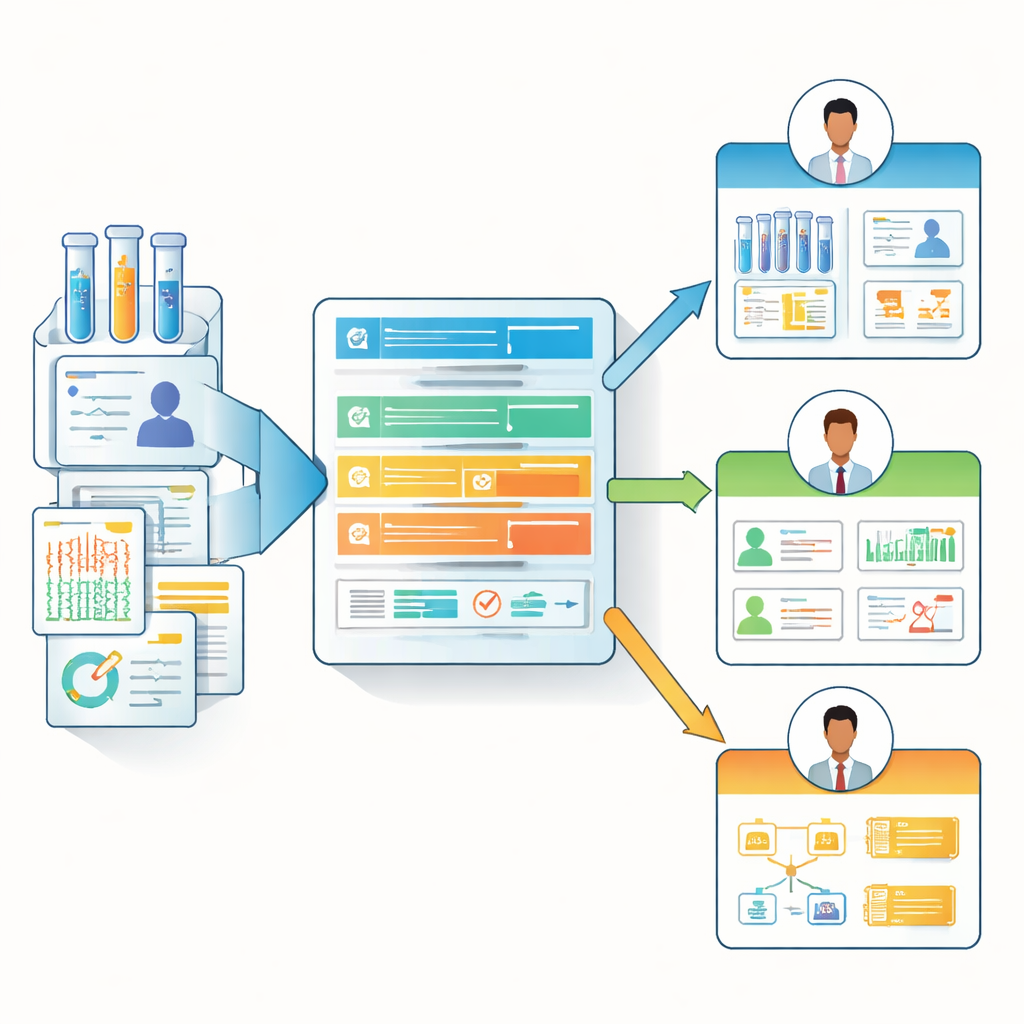
Da taglia unica a note dati consapevoli dei ruoli
Sulla base di queste intuizioni del sondaggio, gli autori hanno progettato il “Biomedical Data Manifest”, un modello di documentazione leggero e web-based che si adatta ai diversi ruoli. Invece di costringere ogni contribuente a compilare una checklist enorme, il manifesto utilizza una gerarchia di domande principali e opzionali, più dettagliate. Può mettere in evidenza i campi più rilevanti per ogni persona — per esempio, evidenziando la provenienza dei dati e i dettagli sugli aggiornamenti per gli analisti, mentre enfatizza il contesto clinico e i vincoli per i ricercatori e i clinici in prima linea. Il team fornisce un modulo pronto all’uso (ad esempio in Microsoft Forms), un modello di visualizzazione HTML e un pacchetto open-source in R chiamato BioDataManifest. Questo software può trasformare automaticamente le risposte al sondaggio in pagine manifesto chiare e persino recuperare informazioni da repository pubblici importanti come il Genomic Data Commons e dbGaP per creare manifesti parziali per dataset esistenti.
Cosa significa questo per l’AI medica futura
In definitiva, il Biomedical Data Manifest è uno strumento pratico per rendere il «foglio informativo» dei dataset biomedici più facile da creare, condividere e comprendere. Separando la documentazione sui dati dalla documentazione su modelli AI specifici, e adattando ciò che viene mostrato ai diversi ruoli degli utenti, il framework riduce l’onere per i ricercatori offrendo agli utenti a valle il contesto necessario per giudicare se un dataset è adatto a uno scopo. In termini pratici, trasforma dataset medici opachi in pacchi chiaramente etichettati, aiutando gli sviluppatori di AI a individuare limiti e potenziali bias prima che incidano sui pazienti. Se adottata su larga scala, questo tipo di documentazione riutilizzabile e consapevole dei ruoli potrebbe rendere l’AI biomedica più trasparente, riproducibile ed equa.
Citazione: Bottomly, D., Suciu, C.G., Cordier, B. et al. Biomedical Data Manifest: A lightweight data documentation mapping to increase transparency for AI/ML. Sci Data 13, 414 (2026). https://doi.org/10.1038/s41597-026-06670-0
Parole chiave: documentazione dei dati biomedici, AI responsabile in medicina, trasparenza dei dataset, bias nel machine learning, governance dei dati