Clear Sky Science · it
Stima del rango percentuale educativo a livello di comunità in Cina usando big data multisorgente e machine learning
Perché il livello d’istruzione del tuo quartiere conta
Dove viviamo influenza le scuole che frequentano i nostri figli, la sicurezza delle nostre strade e persino il valore delle nostre case. Eppure in Cina le informazioni di base su quanto siano istruiti i vari quartieri sono state a lungo difficili da reperire. Questo studio cambia le carte in tavola: utilizzando immagini satellitari, foto di strada e algoritmi informatici avanzati, stima il livello educativo relativo di oltre 120.000 comunità in tutto il paese, offrendo una nuova lente sulla disuguaglianza sociale e sulla vita urbana.
Oltre gli anni di scolarizzazione
La maggior parte delle statistiche confronta l’istruzione contando gli anni trascorsi a scuola. Ma questo può risultare fuorviante fra le generazioni. Un diploma di scuola superiore un tempo collocava qualcuno vicino al vertice della propria coorte d’età; oggi molti dei loro figli hanno lauree universitarie. Gli autori usano invece un “rango percentuale educativo”, che indica la posizione di una persona all’interno della propria coorte di nascita, da 0 (meno istruito) a 100 (più istruito). In questo modo, una persona anziana con soltanto la scuola media e una persona più giovane con una laurea possono essere riconosciute come aventi uno status sociale simile se si collocano, per esempio, intorno al 70° percentile della loro generazione.
Trasformare il paesaggio cittadino in indizi sociali
Per mappare i ranghi percentili educativi a livello di comunità, il team ha utilizzato sei ondate di un ampio sondaggio nazionale oltre a una vasta gamma di “big data” che descrivono l’ambiente costruito. Hanno osservato che tipo di luoghi circondano ogni quartiere — negozi, scuole, ospedali, parchi e uffici — quanto sono dense le costruzioni e le strade, quanto l’area appare luminosa di notte dalle immagini satellitari e quante persone vi sono tipicamente presenti. Da milioni di foto street view, hanno impiegato la visione artificiale per misurare spazi verdi, marciapiedi, traffico, segni di degrado come rifiuti o graffiti e persino quanto una strada appaia ricca o sicura agli osservatori umani. Hanno inoltre considerato il terreno, come altitudine e pendenza, poiché le aree ripide o remote spesso restano indietro nello sviluppo. 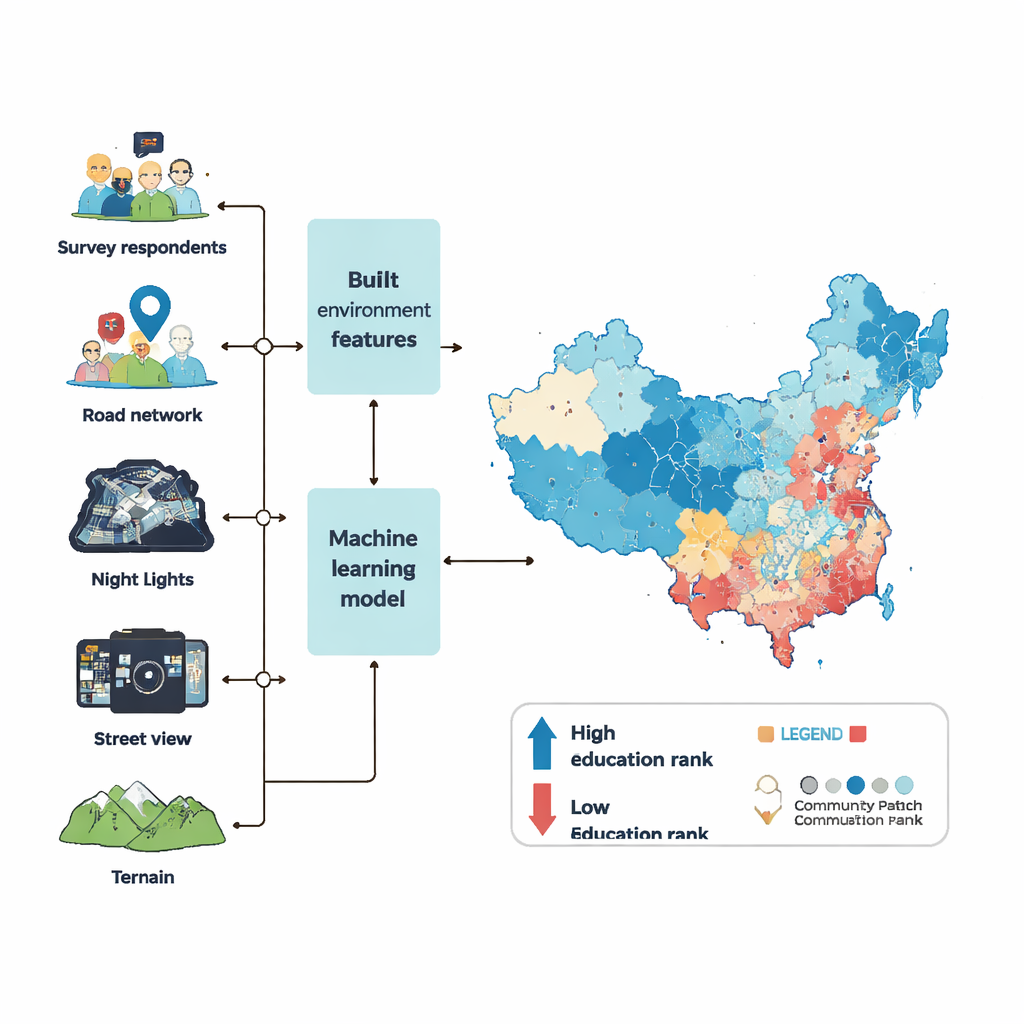
Insegnare alle macchine a leggere la città
Con questi ingredienti, i ricercatori hanno addestrato un potente modello di machine learning (chiamato XGBoost) per apprendere il legame tra le caratteristiche fisiche di una comunità e il rango percentuale educativo medio dei suoi residenti. Hanno prima colmato le lacune nei dati ambientali usando un accurato processo statistico di “imputazione” in modo che i valori mancanti non alterassero i risultati. Poi hanno ottimizzato i parametri interni del modello attraverso centinaia di esecuzioni, valutando le prestazioni in base a quanto bene il modello riusciva a prevedere i ranghi educativi per comunità del sondaggio che non aveva visto prima. Il modello finale è stato in grado di spiegare oltre il 90 percento delle differenze tra comunità nei dati di test, con errori limitati — prestazioni superiori rispetto a sforzi simili in altri paesi.
Cosa rivela la nuova mappa nazionale
Con il modello addestrato, gli autori hanno previsto i ranghi percentili medi di istruzione per 122.126 comunità in tutta la Cina continentale nel 2020, coprendo la maggior parte delle aree urbane e circa l’85 percento della popolazione. I centri città emergono generalmente come i più istruiti, seguiti da poli secondari e poi da sobborghi lontani, sebbene ogni metropoli abbia il proprio schema. Il nucleo storico di Pechino, ad esempio, non ospita i ranghi più alti, mentre le zone altamente istruite di Shenzhen sono disperse su più centri. Per verificare l’affidabilità, il team ha confrontato le loro stime con i dati del censimento ufficiale e con registri proprietari dei servizi basati sulla localizzazione, dove disponibili. A livello di prefettura e contea, le aree con ranghi percentili previsti più elevati mostrano anche più anni di istruzione nel censimento. A livello di quartiere a Pechino e Guangzhou, la loro mappa si allinea da vicino sia con i benchmark aziendali sia con quelli del censimento. 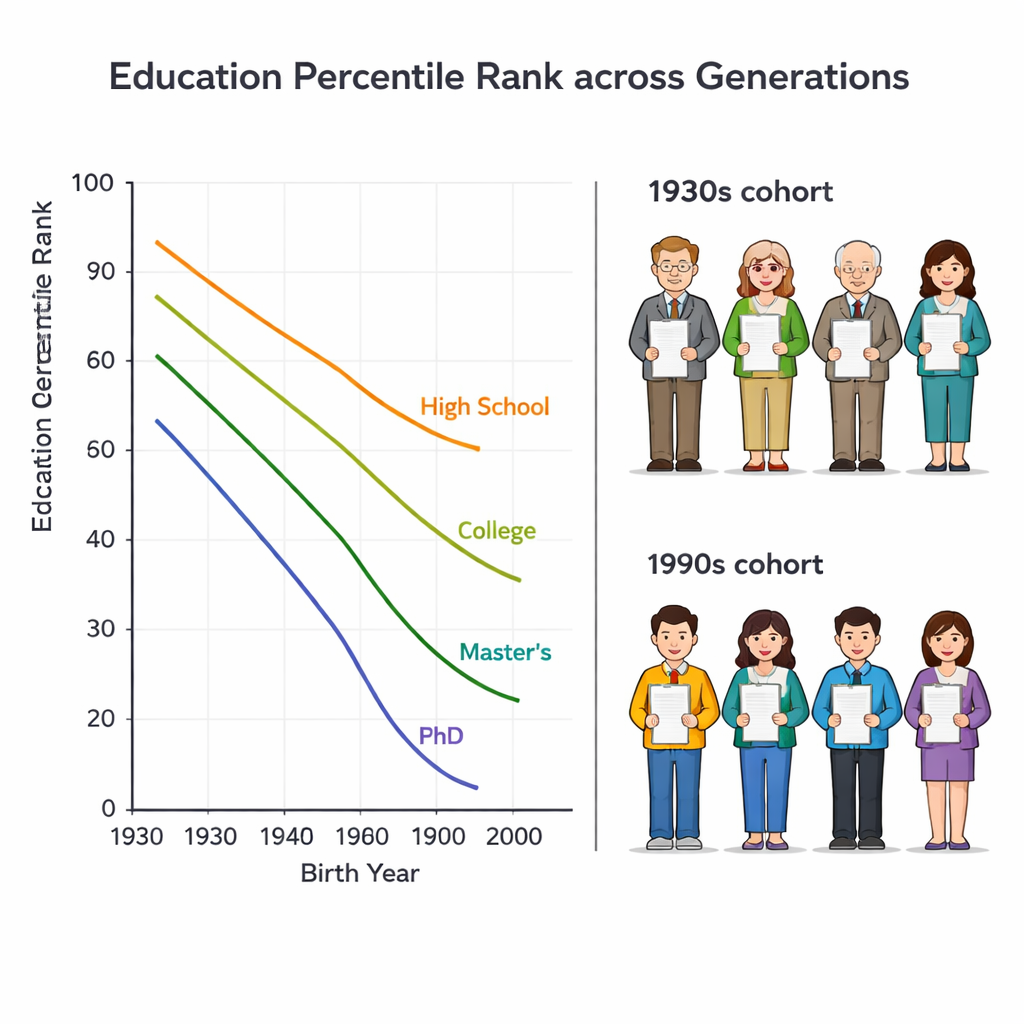
Perché questo è importante nella vita di tutti i giorni
Per i responsabili politici, i pianificatori e i ricercatori, questo nuovo dataset aperto offre un ritratto dettagliato e aggiornato dei vantaggi e svantaggi educativi nelle città cinesi. Può essere utilizzato per studiare dove si stanno formando enclave della classe media, fino a che punto si è diffusa la gentrificazione o quali distretti potrebbero necessitare di scuole migliori, servizi sociali o trasporti pubblici. Per i lettori non specialisti, il messaggio centrale è semplice: «leggendo» le strade, le luci e gli edifici di un quartiere, gli strumenti moderni dei dati possono approssimare la posizione sociale dei suoi residenti con sorprendente precisione. Questo lavoro non sostituisce i censimenti tradizionali, ma fornisce un modo rapido e a basso costo per colmare le lacune tra essi e per comprendere meglio come i luoghi che costruiamo riflettano e rinforzino le nostre divisioni sociali.
Citazione: Zhang, Y., Pan, Z., You, Y. et al. Community-level education percentile rank estimation in China using multi-source big data and machine learning. Sci Data 13, 304 (2026). https://doi.org/10.1038/s41597-026-06664-y
Parole chiave: disuguaglianza educativa, Cina urbana, big data, machine learning, quartieri