Clear Sky Science · it
Estrazione di relazioni e normalizzazione dei concetti basate su transformer utilizzando un corpus annotato di trial clinici
Aiutare i medici a trovare i pazienti giusti più velocemente
Ogni trial clinico dipende dall’identificazione di pazienti che soddisfino un lungo elenco di condizioni mediche, trattamenti e vincoli temporali. Oggi i medici spesso devono leggere a mano cartelle cliniche elettroniche e descrizioni dei trial, un processo lento e soggetto a errori. Questo articolo presenta una raccolta ampia e attentamente verificata di testi di trial clinici in spagnolo e mostra come l’intelligenza artificiale moderna possa trasformare quel linguaggio non strutturato in dati organizzati, aprendo la strada a ricerche mediche più rapide, eque e precise.
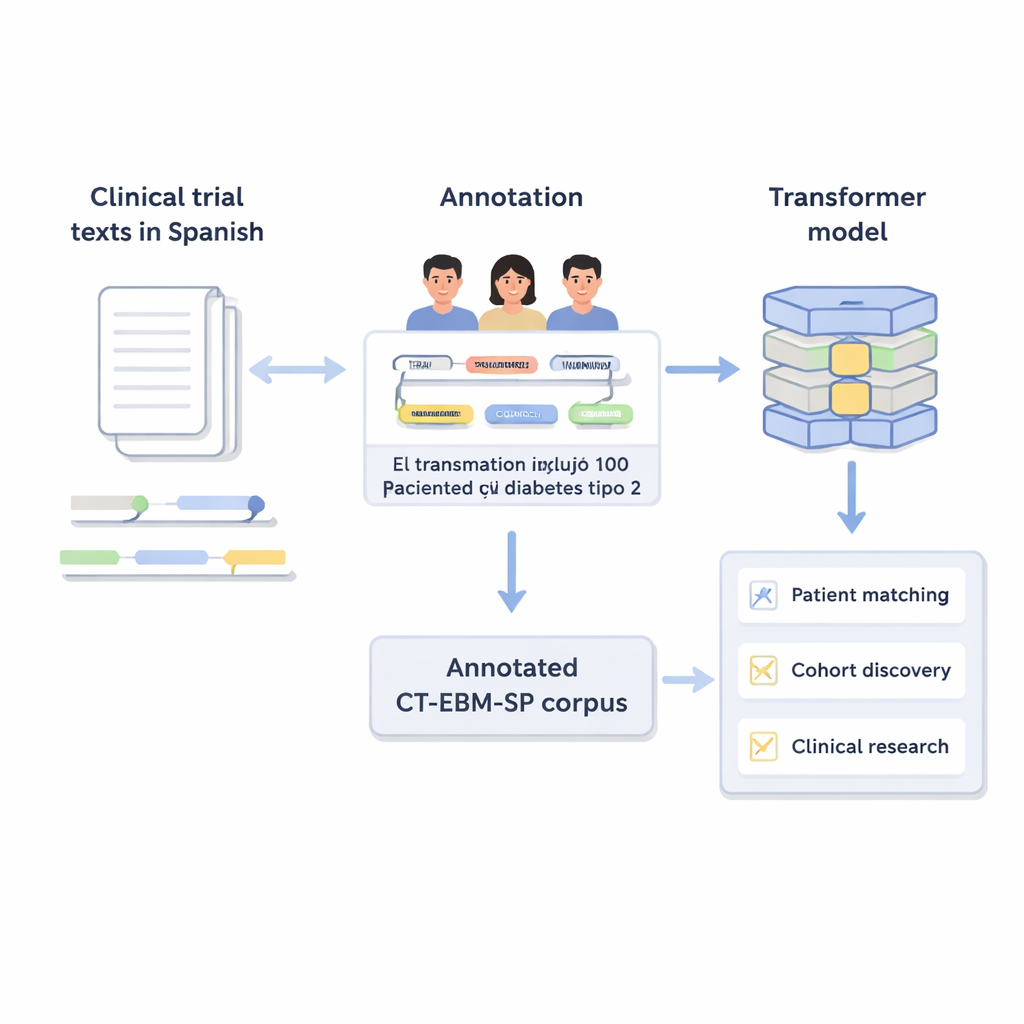
Trasformare il testo libero in informazioni organizzate
I trial clinici descrivono chi può e non può partecipare usando un linguaggio medico quotidiano: limiti di età, malattie pregresse, risultati di esami e trattamenti provati. I computer faticano a interpretare questo tipo di testo libero. Gli autori hanno creato la versione 3 del corpus CT‑EBM‑SP, un dataset di 1.200 testi di trial clinici in spagnolo contenente quasi 300.000 parole. Esperti umani hanno esaminato questi testi e annotato 23 tipi di entità mediche, come malattie, farmaci, risultati di test ed espressioni temporali, oltre a indicatori di negazione (per esempio, “sin antecedentes de”) e di incertezza. Hanno anche etichettato 11 attributi che catturano dettagli come se un evento è passato o futuro e se è accaduto al paziente o a un familiare.
Far sì che i termini medici parlino la stessa lingua
Una sfida importante in medicina è che lo stesso concetto può essere scritto in molti modi. Per risolvere questo problema, il team ha collegato la maggior parte delle entità annotate a codici standardizzati del Unified Medical Language System (UMLS), un grande dizionario medico multilingue. Questo passaggio, chiamato normalizzazione dei concetti, fa sì che diverse grafie o frasi puntino allo stesso identificatore univoco. Per esempio, varie varianti di “25‑idrossivitamina D” sono tutte mappate su un unico concetto UMLS. In totale, il corpus include oltre 87.000 entità e più di 68.000 relazioni, e circa l’82% delle entità è stato normalizzato con successo. Due esperti hanno verificato indipendentemente questi collegamenti, ottenendo un accordo molto elevato, il che indica che le annotazioni sono affidabili.
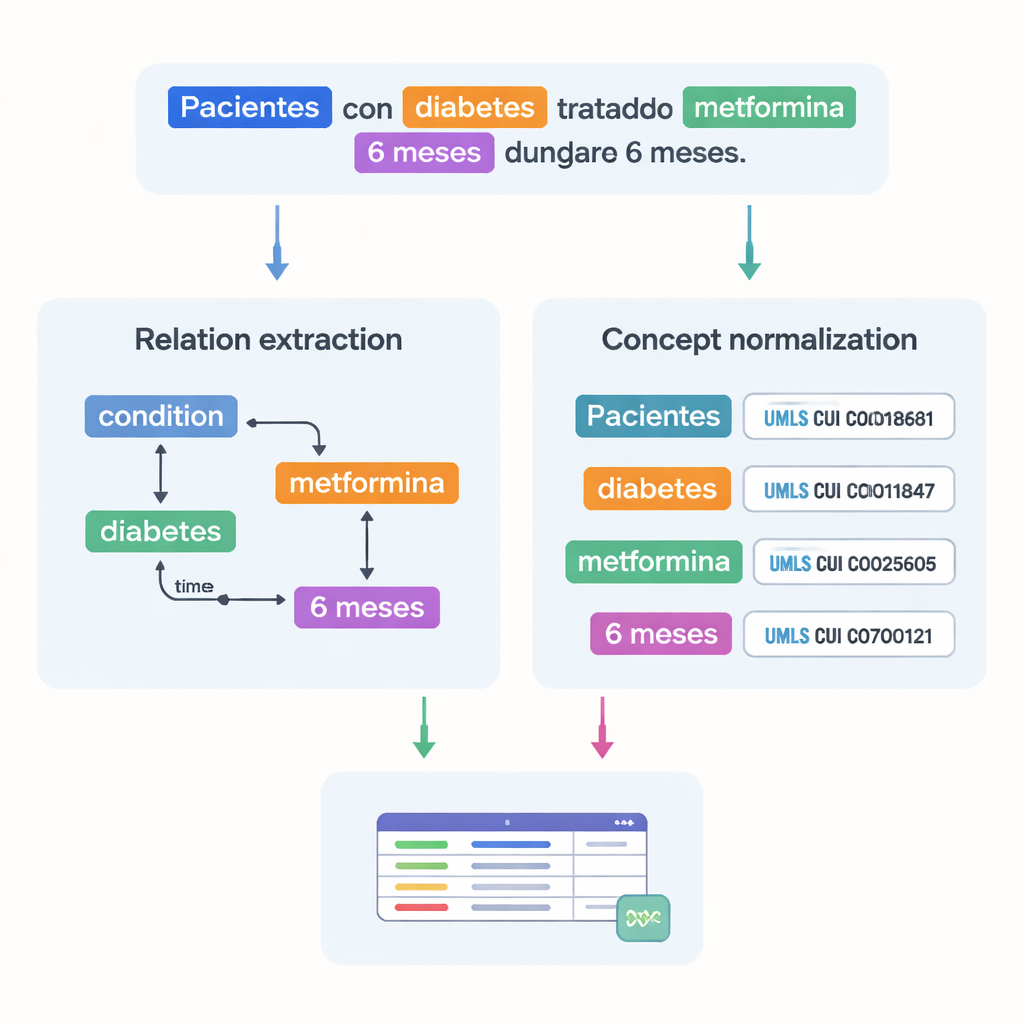
Catturare come i fatti medici si relazionano fra loro
Oltre a elencare termini medici, il dataset registra come questi si connettono. Gli autori hanno progettato 18 tipi di relazioni per catturare schemi rilevanti nei trial, come quale dose appartiene a quale farmaco, quanto dura un trattamento o quale condizione sperimenta un paziente. Le relazioni temporali indicano se un evento avviene prima o dopo un altro, e altri collegamenti segnalano dove si manifesta una malattia nel corpo o se una frase esprime negazione o speculazione. Insieme, queste relazioni permettono ai computer di costruire grafi della situazione di un paziente—chi è il paziente, quale condizione ha, quale trattamento riceve e con quale tempistica—piuttosto che limitarsi a riconoscere parole isolate.
Addestrare e testare modelli di IA moderni
Per dimostrare l’utilità pratica del corpus, gli autori hanno fatto fine‑tuning di diversi modelli di IA basati su transformer, incluse versioni multilingue di BERT e RoBERTa. Hanno addestrato questi modelli su due compiti: l’estrazione delle relazioni, che impara a ricostruire i collegamenti fra entità, e la normalizzazione dei concetti medici, che mappa il testo sui codici UMLS. Nell’estrazione delle relazioni, il miglior modello ha raggiunto un punteggio F1 vicino a 0,88, il che significa che ha identificato correttamente la maggior parte delle relazioni con relativamente pochi errori. Per la normalizzazione dei concetti, un modello multilingue chiamato SapBERT, usato senza ulteriore addestramento, ha indovinato correttamente il concetto giusto al primo tentativo quasi nel 90% dei casi. Questi risultati mostrano che dataset ben annotati e di dimensioni medie possono alimentare modelli accurati ed efficienti anche senza sistemi linguistici di uso generale molto grandi.
Perché questa risorsa conta per la cura futura
Il corpus CT‑EBM‑SP e i modelli associati forniscono una base per strumenti che possono analizzare automaticamente i testi di trial clinici in spagnolo, confrontarli con le cartelle dei pazienti e supportare la scoperta di coorti negli ospedali. Poiché i dati sono allineati con standard medici internazionali e sono stati attentamente verificati da esperti, possono anche aiutare a sviluppare risorse simili per altre lingue con meno strumenti digitali. In termini pratici, questo lavoro mira a rendere più facile e sicuro offrire i trial giusti alle persone giuste, accelerando le scoperte mediche e riducendo il carico sui professionisti della salute.
Citazione: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
Parole chiave: trial clinici, text mining medico, assistenza sanitaria spagnola, modelli transformer, medicina basata sulle prove