Clear Sky Science · it
Dati a livello di scena dei film da Amazon X-Ray nel mercato statunitense combinati con IMDb
Perché le scene dei film sono importanti per comprendere la cultura
I film plasmano il nostro modo di vedere il mondo, eppure la maggior parte delle ricerche sul cinema si è concentrata su incassi, generi di base o potere delle star, non su ciò che effettivamente si svolge in scena, scena dopo scena. Questo articolo presenta un nuovo set di dati che consente ai ricercatori di approfondire il livello delle singole scene, dei personaggi e delle battute per oltre tremila film trasmessi negli Stati Uniti su Amazon Prime Video. Combinando la funzione X-Ray di Amazon con l’Internet Movie Database (IMDb), gli autori offrono una mappa dettagliata e standardizzata di chi appare dove e quando in ciascun film, aprendo la strada a studi più ricchi sulla rappresentazione, la narrazione e persino sui sistemi di intelligenza artificiale che apprendono dai video.
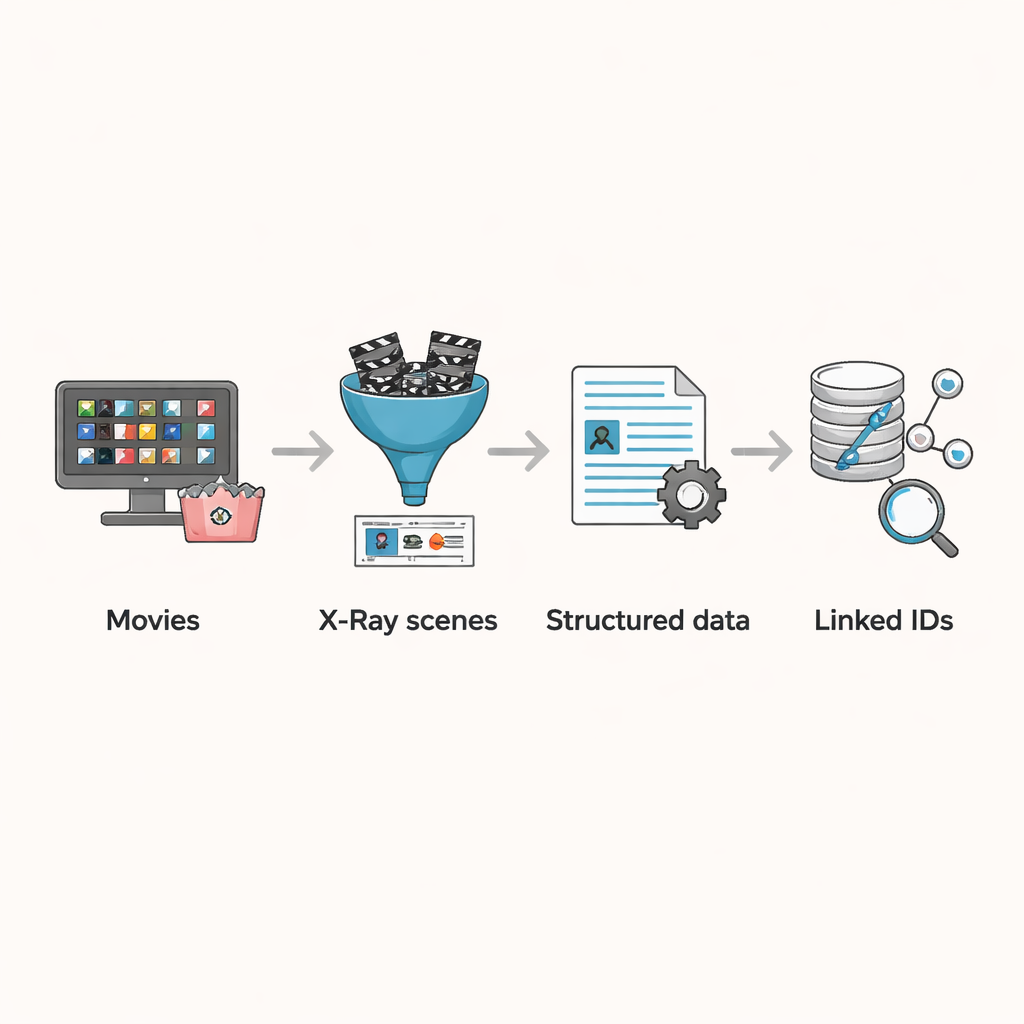
Dai copioni grezzi alle scene finite
Finora, la maggior parte degli studi su larga scala sui film si è basata su sceneggiature o file di sottotitoli. Queste fonti sono utili ma imperfette. I copioni sono spesso bozze iniziali che differiscono dal montaggio finale e possono omettere personaggi minori o modifiche tardive al montaggio. I sottotitoli catturano le battute pronunciate ma non i personaggi silenziosi, gli comparse di sfondo e la narrazione puramente visiva — per esempio la macchina da presa che indugia sul volto di un personaggio. A causa di queste lacune, i tentativi precedenti di tracciare chi interagisce con chi sullo schermo o come sono rappresentati diversi gruppi hanno dovuto indovinare a partire solo dal testo, il che può portare a errori nell’identificazione dei personaggi e delle loro relazioni.
Trasformare X-Ray in dati pronti per la ricerca
La funzione X-Ray di Amazon offre una via d’uscita da questi problemi. Quando gli spettatori mettono in pausa un film, X-Ray mostra quali attori e personaggi sono attualmente sullo schermo, informazioni curate e collegate direttamente al film nel montaggio finale. Gli autori hanno costruito una pipeline per raccogliere questi dati a livello di scena per 3.265 film disponibili nel catalogo Prime Video negli Stati Uniti a agosto 2023. Hanno prima raccolto tutte le voci di film incluse in Prime, filtrato quelle senza informazioni X-Ray e rimosso duplicati causati da titoli ripetuti o versioni alternative. Per ciascun film rimanente, hanno intercettato i flussi di dati usati dal lettore per caricare le informazioni di X-Ray e dei sottotitoli, salvando i risultati in file strutturati che elencano i confini delle scene, i personaggi presenti in ciascuna scena e, per la maggior parte dei titoli, la temporizzazione precisa di ogni segmento di sottotitolo.
Collegare le scene al più ampio mondo del cinema
La vera potenza del set di dati deriva dal collegare questi scomposizioni di scena a informazioni esterne. Sebbene X-Ray colleghi già ciascun personaggio a un profilo IMDb, non include un ID IMDb per il film stesso. Gli autori hanno progettato un algoritmo di abbinamento che parte dal titolo di un film, recupera diversi candidati da IMDb e poi confronta il cast principale indicato su IMDb con gli attori elencati nei dati X-Ray. Se almeno un attore principale coincide, il film viene considerato una corrispondenza. Questo processo automatizzato ha abbinato correttamente la grande maggioranza dei film, e il team ha quindi controllato manualmente le poche centinaia di casi dubbi, correggendo classificazioni errate e rimuovendo voci che non erano effettivamente film narrativi, come spettacoli di stand-up. Il risultato finale è un insieme accuratamente ripulito di film in cui ogni scena, personaggio e sottotitolo può essere collegato a ricchi metadati come anno, paese e demografia del cast.
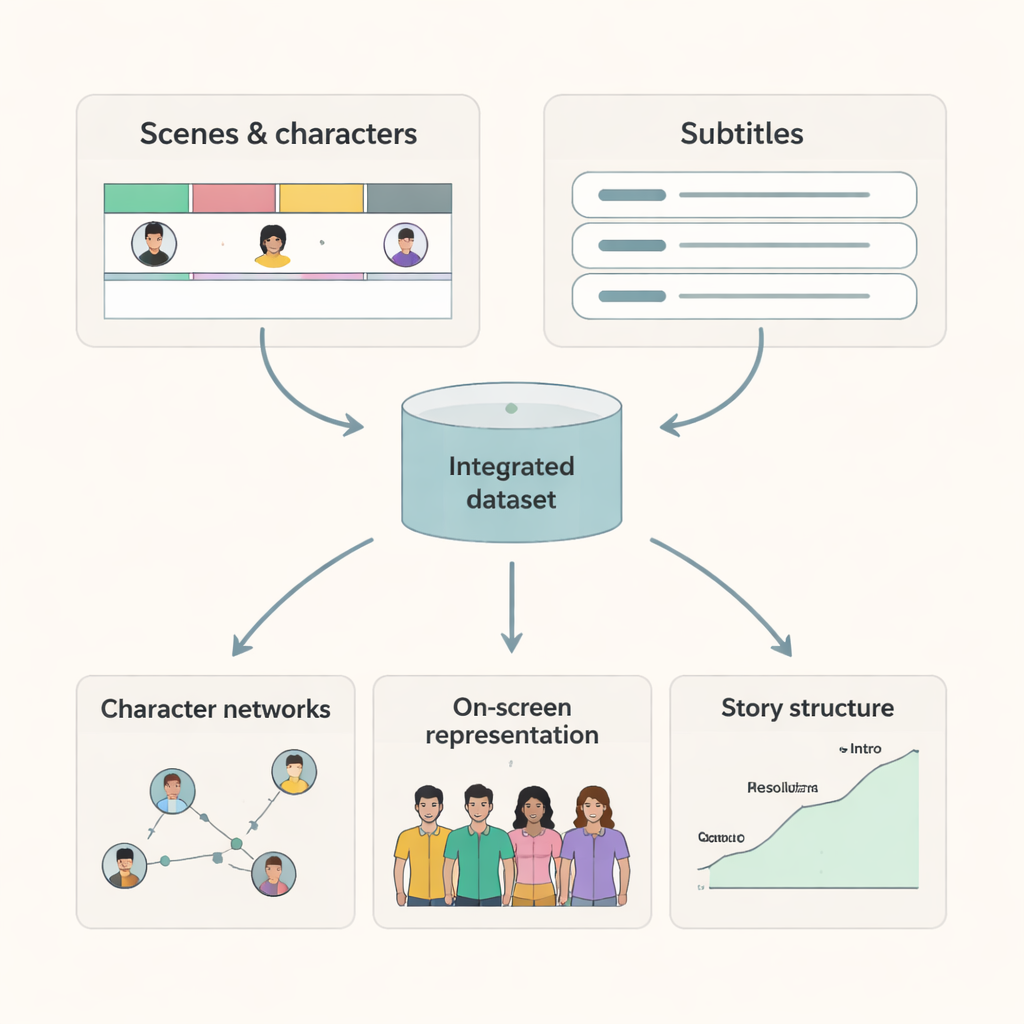
Cosa possono fare i ricercatori con questi film
Poiché ogni scena ha tempi di inizio e fine chiari e una lista di chi appare, i ricercatori possono ora costruire mappe precise delle interazioni tra personaggi e del tempo sullo schermo. I sottotitoli allineati con le scene rendono possibile studiare come il linguaggio varia tra i personaggi e i contesti, o come certi temi si sviluppano nel dialogo. Combinando questo set di dati con informazioni aggiuntive provenienti da IMDb e altre fonti, gli studiosi possono esaminare domande come: come è cambiato l’equilibrio di genere sullo schermo nel corso dei decenni? I personaggi di diversi background ricevono uguale attenzione narrativa? In che modo i modelli di interazione differiscono tra generi o paesi? Il dataset offre anche un benchmark di alta qualità per modelli di intelligenza artificiale che mirano a comprendere il contenuto video, perché fornisce verità di riferimento su chi è visibile e quando.
Una nuova lente sui film di tutti i giorni
In termini semplici, questo lavoro trasforma migliaia di film in un catalogo ricercabile, scena per scena, di chi appare, chi parla e come sono strutturate le storie. Pur essendo la raccolta limitata ai titoli disponibili su Prime Video negli Stati Uniti e dipendente dai processi interni di X-Ray di Amazon, copre comunque film di molte decadi e generi, non solo i celebri vincitori di premi. Questa ampiezza permette ai ricercatori di studiare i film di uso comune, non solo i classici che sopravvivono nella memoria. Man mano che il dataset viene aggiornato ed esteso, promette di approfondire la nostra comprensione di come i film riflettano la società — e di offrire a scienziati sociali e tecnologi un quadro più fedele di ciò che accade veramente sullo schermo.
Citazione: Shrestha, S., Heo, Y., Barron, A.T.J. et al. Scene-level movie data from Amazon X-Ray in the US market combined with IMDb. Sci Data 13, 275 (2026). https://doi.org/10.1038/s41597-026-06602-y
Parole chiave: set di dati sui film, analisi a livello di scena, Amazon X-Ray, metadati IMDb, rappresentazione sullo schermo