Clear Sky Science · it
CNeuroMod-THINGS, un dataset fMRI ad alta densità per le neuroscienze visive
Perché guardare immagini può rivelare come funziona la nostra mente
Ogni giorno i nostri occhi acquisiscono migliaia di immagini — da tazze di caffè e smartphone a cani, alberi e strade affollate. Dietro le quinte, il nostro cervello riconosce rapidamente ciò che vediamo e spesso lo ricorda in seguito. Il progetto CNeuroMod-THINGS si è proposto di catturare questa attività nascosta con straordinaria precisione, creando uno dei dataset cerebrali più approfonditi mai raccolti mentre persone osservano immagini del mondo reale. Questa risorsa è pensata per alimentare la prossima generazione di ricerche sul cervello e sull’intelligenza artificiale.
Costruire una libreria ricca di risposte cerebrali
Invece di scansionare centinaia di volontari una o due volte, il team ha scansionato ripetutamente appena quattro partecipanti molto impegnati. Ogni persona è tornata per 33–36 visite, per un totale di circa 200 ore di imaging cerebrale nell’ambito del più ampio progetto CNeuroMod e di decine di ore dedicate solo alle immagini. Durante queste sessioni i volontari hanno visto fino a 4.320 fotografie distinte tratte dalla collezione di immagini THINGS, che copre 720 categorie di oggetti di uso quotidiano come strumenti, animali, veicoli e mobili. Questa scelta accurata di immagini assicura che siano rappresentati molti angoli del nostro mondo visivo, non solo pochi oggetti popolari.

Un gioco di memoria dentro lo scanner MRI
Per mantenere i partecipanti coinvolti e sondare la memoria, i ricercatori hanno trasformato la visione delle immagini in un gioco di riconoscimento continuo. In ogni prova, un’unica immagine compariva al centro dello schermo mentre la persona giaceva nello scanner MRI. Usando un controller personalizzato in stile videogioco, i partecipanti segnalavano se ritenevano che l’immagine fosse nuova o fosse già stata vista e quanto fossero sicuri di quel giudizio. La maggior parte delle immagini è stata mostrata tre volte: una alla prima esposizione, una qualche minuto dopo nella stessa visita e un’altra in una visita successiva, spesso a circa una settimana di distanza. Questo disegno sperimentale ha permesso al team di confrontare la memoria a breve e a più lungo termine per esattamente le stesse immagini monitorando i corrispondenti cambiamenti nell’attività cerebrale.
Catturare segnali dettagliati dalla visione e dalla memoria
Il dataset va ben oltre semplici misure “on/off” dell’attività cerebrale. Gli autori hanno usato metodi di analisi avanzati per stimare una risposta separata per ogni singola prova e per ogni immagine in ciascun minuscolo pixel tridimensionale della scansione cerebrale. Hanno inoltre tracciato dove le persone guardavano con telecamere per il tracciamento oculare, monitorato respirazione e battito cardiaco e misurato il movimento della testa. I controlli di qualità mostrano che i segnali sono sorprendentemente stabili: i partecipanti hanno risposto quasi in ogni prova, hanno mantenuto lo sguardo vicino al centro dello schermo e si sono mossi pochissimo. Nelle aree visive chiave — regioni note per rispondere fortemente a volti, corpi o scene — la stessa immagine produceva schemi di attività altamente coerenti ogni volta che appariva. Questi modelli erano così robusti che, quando le risposte sono state rappresentate in una mappa semplificata bidimensionale, le immagini con significati simili (per esempio animali o veicoli) tendevano a raggrupparsi insieme.
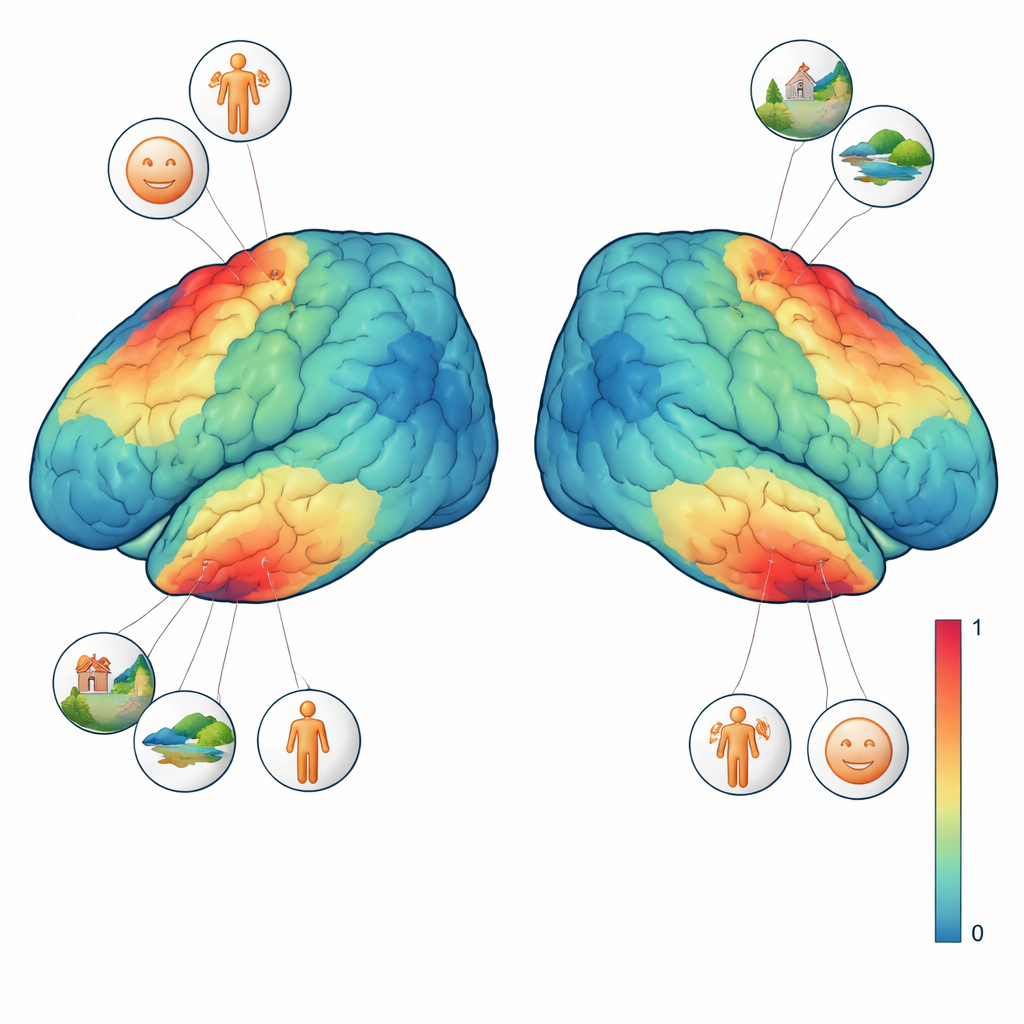
Mappare ciò che interessa alle diverse regioni cerebrali
Per interpretare meglio questi segnali, tre dei quattro partecipanti hanno completato test visivi aggiuntivi. In uno, forme in movimento attraversavano uno sfondo testurizzato per rivelare quale parte del campo visivo ciascuna regione cerebrale “vede”. In un altro, sono stati mostrati brevi blocchi di volti, luoghi, parti del corpo, personaggi e oggetti generici per individuare le regioni che preferiscono un tipo di immagine rispetto ad altri. Combinando questi compiti di localizzazione con l’esperimento principale, il team ha potuto porre domande precise come: un singolo voxel risponde di più quando è presente un volto o quando è visibile l’intera scena? Hanno scoperto che le regioni selettive per i volti rispondevano più fortemente ogniqualvolta compariva qualsiasi tipo di volto, mentre una regione selettiva per le scene preferiva immagini con sfondi ricchi come stanze, strade o paesaggi, anche quando non erano visibili persone. Queste preferenze fini sono emerse a livello di singole immagini e persino di singoli voxel.
Una base per modelli più intelligenti della visione
Al suo nucleo, CNeuroMod-THINGS è una risorsa pubblica accuratamente curata piuttosto che un risultato isolato. Tutti i dati cerebrali, il tracciamento oculare, le risposte comportamentali, le annotazioni delle immagini e il codice di analisi sono condivisi liberamente sotto una licenza aperta. Poiché le stesse quattro persone sono state scansionate in molti altri compiti — guardando film, giocando ai videogiochi, ascoltando storie — i ricercatori possono ora costruire modelli dettagliati specifici per individuo che collegano esperimenti controllati a esperienze più naturali. Per i non specialisti, il punto fondamentale è che ora disponiamo di una “tabella di consultazione” ad alta risoluzione che mostra come un cervello umano reale risponde a migliaia di immagini di uso quotidiano. Questo aiuterà gli scienziati a testare idee sulla percezione visiva e sulla memoria e guiderà la progettazione di sistemi di visione artificiale che vedono il mondo in modo un po’ più simile a noi.
Citazione: St-Laurent, M., Pinsard, B., Contier, O. et al. CNeuroMod-THINGS, a densely-sampled fMRI dataset for visual neuroscience. Sci Data 13, 141 (2026). https://doi.org/10.1038/s41597-026-06591-y
Parole chiave: fMRI, percezione visiva, riconoscimento degli oggetti, dati cerebrali, memoria